 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction of GPU Failures Under Deep Learning Workloads
Paper and Code
Jan 27, 2022
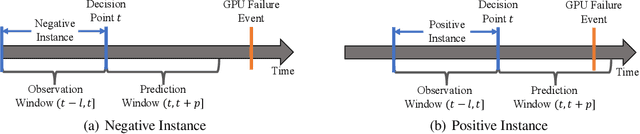
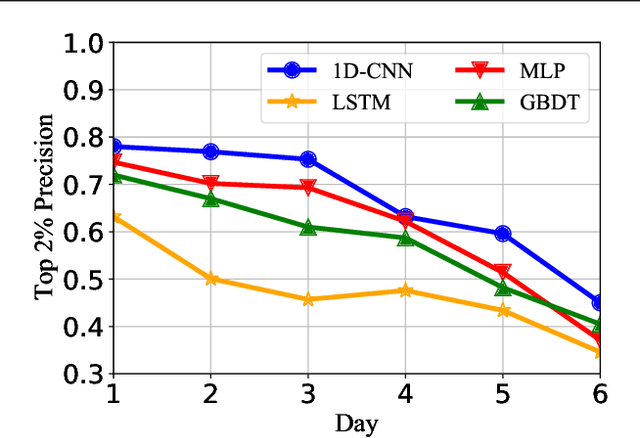

Graphics processing units (GPUs) are the de facto standard for processing deep learning (DL) tasks. Meanwhile, GPU failures, which are inevitable, cause severe consequences in DL tasks: they disrupt distributed trainings, crash inference services, and result in service level agreement violations. To mitigate the problem caused by GPU failures, we propose to predict failures by using ML models. This paper is the first to study prediction models of GPU failures under large-scale production deep learning workloads. As a starting point, we evaluate classic prediction models and observe that predictions of these models are both inaccurate and unstable. To improve the precision and stability of predictions, we propose several techniques, including parallel and cascade model-ensemble mechanisms and a sliding training method. We evaluate the performances of our various techniques on a four-month production dataset including 350 million entries. The results show that our proposed techniques improve the prediction precision from 46.3\% to 84.0\%.