 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Backdoor Attacks in Federated Learning
Paper and Code
Oct 28, 2020
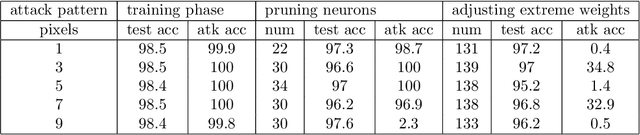
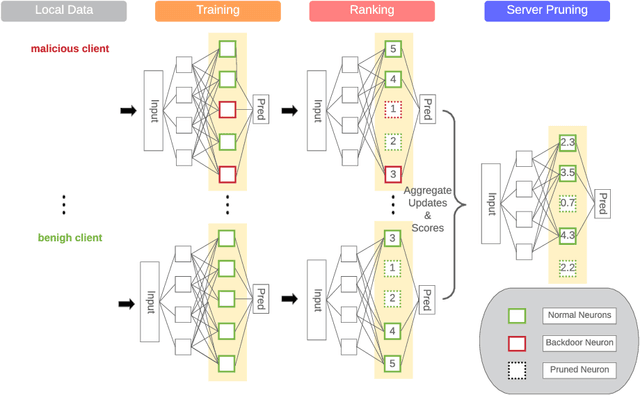
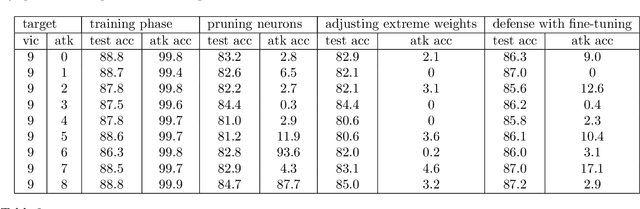
Malicious clients can attack federated learning systems by using malicious data, including backdoor samples, during the training phase. The compromised global model will perform well on the validation dataset designed for the task. However, a small subset of data with backdoor patterns may trigger the model to make a wrong prediction. Previously, there was an arms race. Attackers tried to conceal attacks and defenders tried to detect attacks during the aggregation stage of training on the server-side in a federated learning system. In this work, we propose a new method to mitigate backdoor attacks after the training phase. Specifically, we designed a federated pruning method to remove redundant neurons in the network and then adjust the model's extreme weight values. Experiments conducted on distributed Fashion-MNIST have shown that our method can reduce the average attack success rate from 99.7% to 1.9% with a 5.5% loss of test accuracy on the validation dataset. To minimize the pruning influence on test accuracy, we can fine-tune after pruning, and the attack success rate drops to 6.4%, with only a 1.7% loss of test accuracy.