 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Brushstroke Generation with Diffusion Models for Oil Painting
Mar 01, 2026Many creative multimedia systems are built upon visual primitives such as strokes or textures, which are difficult to collect at scale and fundamentally different from natural image data. This data scarcity makes it challenging for modern generative models to learn expressive and controllable primitives, limiting their use in process-aware content creation. In this work, we study the problem of learning human-like brushstroke generation from a small set of hand-drawn samples (n=470) and propose StrokeDiff, a diffusion-based framework with Smooth Regularization (SmR). SmR injects stochastic visual priors during training, providing a simple mechanism to stabilize diffusion models under sparse supervision without altering the inference process. We further show how the learned primitives can be made controllable through a Bézier-based conditioning module and integrated into a complete stroke-based painting pipeline, including prediction, generation, ordering, and compositing. This demonstrates how data-efficient primitive modeling can support expressive and structured multimedia content creation. Experiments indicate that the proposed approach produces diverse and structurally coherent brushstrokes and enables paintings with richer texture and layering, validated by both automatic metrics and human evaluation.
Understanding the Role of Rehearsal Scale in Continual Learning under Varying Model Capacities
Feb 24, 2026Rehearsal is one of the key techniques for mitigating catastrophic forgetting and has been widely adopted in continual learning algorithms due to its simplicity and practicality. However, the theoretical understanding of how rehearsal scale influences learning dynamics remains limited. To address this gap, we formulate rehearsal-based continual learning as a multidimensional effectiveness-driven iterative optimization problem, providing a unified characterization across diverse performance metrics. Within this framework, we derive a closed-form analysis of adaptability, memorability, and generalization from the perspective of rehearsal scale. Our results uncover several intriguing and counterintuitive findings. First, rehearsal can impair model's adaptability, in sharp contrast to its traditionally recognized benefits. Second, increasing the rehearsal scale does not necessarily improve memory retention. When tasks are similar and noise levels are low, the memory error exhibits a diminishing lower bound. Finally, we validate these insights through numerical simulations and extended analyses on deep neural networks across multiple real-world datasets, revealing statistical patterns of rehearsal mechanisms in continual learning.
Exploring the Impact of Parameter Update Magnitude on Forgetting and Generalization of Continual Learning
Feb 24, 2026The magnitude of parameter updates are considered a key factor in continual learning. However, most existing studies focus on designing diverse update strategies, while a theoretical understanding of the underlying mechanisms remains limited. Therefore, we characterize model's forgetting from the perspective of parameter update magnitude and formalize it as knowledge degradation induced by task-specific drift in the parameter space, which has not been fully captured in previous studies due to their assumption of a unified parameter space. By deriving the optimal parameter update magnitude that minimizes forgetting, we unify two representative update paradigms, frozen training and initialized training, within an optimization framework for constrained parameter updates. Our theoretical results further reveals that sequence tasks with small parameter distances exhibit better generalization and less forgetting under frozen training rather than initialized training. These theoretical insights inspire a novel hybrid parameter update strategy that adaptively adjusts update magnitude based on gradient directions. Experiments on deep neural networks demonstrate that this hybrid approach outperforms standard training strategies, providing new theoretical perspectives and practical inspiration for designing efficient and scalable continual learning algorithms.
Bipartite Graph Attention-based Clustering for Large-scale scRNA-seq Data
Feb 07, 2026scRNA-seq clustering is a critical task for analyzing single-cell RNA sequencing (scRNA-seq) data, as it groups cells with similar gene expression profiles. Transformers, as powerful foundational models, have been applied to scRNA-seq clustering. Their self-attention mechanism automatically assigns higher attention weights to cells within the same cluster, enhancing the distinction between clusters. Existing methods for scRNA-seq clustering, such as graph transformer-based models, treat each cell as a token in a sequence. Their computational and space complexities are $\mathcal{O}(n^2)$ with respect to the number of cells, limiting their applicability to large-scale scRNA-seq datasets.To address this challenge, we propose a Bipartite Graph Transformer-based clustering model (BGFormer) for scRNA-seq data. We introduce a set of learnable anchor tokens as shared reference points to represent the entire dataset. A bipartite graph attention mechanism is introduced to learn the similarity between cells and anchor tokens, bringing cells of the same class closer together in the embedding space. BGFormer achieves linear computational complexity with respect to the number of cells, making it scalable to large datasets. Experimental results on multiple large-scale scRNA-seq datasets demonstrate the effectiveness and scalability of BGFormer.
LLM-Guided Diagnostic Evidence Alignment for Medical Vision-Language Pretraining under Limited Pairing
Feb 07, 2026Most existing CLIP-style medical vision--language pretraining methods rely on global or local alignment with substantial paired data. However, global alignment is easily dominated by non-diagnostic information, while local alignment fails to integrate key diagnostic evidence. As a result, learning reliable diagnostic representations becomes difficult, which limits their applicability in medical scenarios with limited paired data. To address this issue, we propose an LLM-Guided Diagnostic Evidence Alignment method (LGDEA), which shifts the pretraining objective toward evidence-level alignment that is more consistent with the medical diagnostic process. Specifically, we leverage LLMs to extract key diagnostic evidence from radiology reports and construct a shared diagnostic evidence space, enabling evidence-aware cross-modal alignment and allowing LGDEA to effectively exploit abundant unpaired medical images and reports, thereby substantially alleviating the reliance on paired data. Extensive experimental results demonstrate that our method achieves consistent and significant improvements on phrase grounding, image--text retrieval, and zero-shot classification, and even rivals pretraining methods that rely on substantial paired data.
Large-Scale Terminal Agentic Trajectory Generation from Dockerized Environments
Feb 03, 2026Training agentic models for terminal-based tasks critically depends on high-quality terminal trajectories that capture realistic long-horizon interactions across diverse domains. However, constructing such data at scale remains challenging due to two key requirements: \textbf{\emph{Executability}}, since each instance requires a suitable and often distinct Docker environment; and \textbf{\emph{Verifiability}}, because heterogeneous task outputs preclude unified, standardized verification. To address these challenges, we propose \textbf{TerminalTraj}, a scalable pipeline that (i) filters high-quality repositories to construct Dockerized execution environments, (ii) generates Docker-aligned task instances, and (iii) synthesizes agent trajectories with executable validation code. Using TerminalTraj, we curate 32K Docker images and generate 50,733 verified terminal trajectories across eight domains. Models trained on this data with the Qwen2.5-Coder backbone achieve consistent performance improvements on TerminalBench (TB), with gains of up to 20\% on TB~1.0 and 10\% on TB~2.0 over their respective backbones. Notably, \textbf{TerminalTraj-32B} achieves strong performance among models with fewer than 100B parameters, reaching 35.30\% on TB~1.0 and 22.00\% on TB~2.0, and demonstrates improved test-time scaling behavior. All code and data are available at https://github.com/Wusiwei0410/TerminalTraj.
One-shot synthesis of rare gastrointestinal lesions improves diagnostic accuracy and clinical training
Dec 30, 2025Rare gastrointestinal lesions are infrequently encountered in routine endoscopy, restricting the data available for developing reliable artificial intelligence (AI) models and training novice clinicians. Here we present EndoRare, a one-shot, retraining-free generative framework that synthesizes diverse, high-fidelity lesion exemplars from a single reference image. By leveraging language-guided concept disentanglement, EndoRare separates pathognomonic lesion features from non-diagnostic attributes, encoding the former into a learnable prototype embedding while varying the latter to ensure diversity. We validated the framework across four rare pathologies (calcifying fibrous tumor, juvenile polyposis syndrome, familial adenomatous polyposis, and Peutz-Jeghers syndrome). Synthetic images were judged clinically plausible by experts and, when used for data augmentation, significantly enhanced downstream AI classifiers, improving the true positive rate at low false-positive rates. Crucially, a blinded reader study demonstrated that novice endoscopists exposed to EndoRare-generated cases achieved a 0.400 increase in recall and a 0.267 increase in precision. These results establish a practical, data-efficient pathway to bridge the rare-disease gap in both computer-aided diagnostics and clinical education.
Shared Object Manipulation with a Team of Collaborative Quadrupeds
Oct 01, 2025
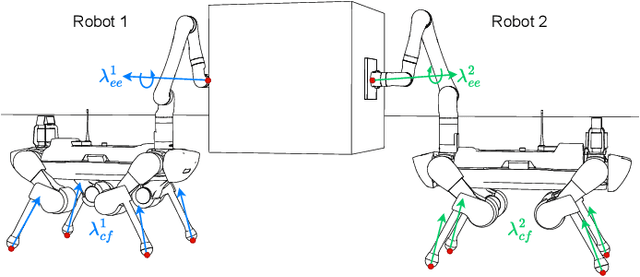
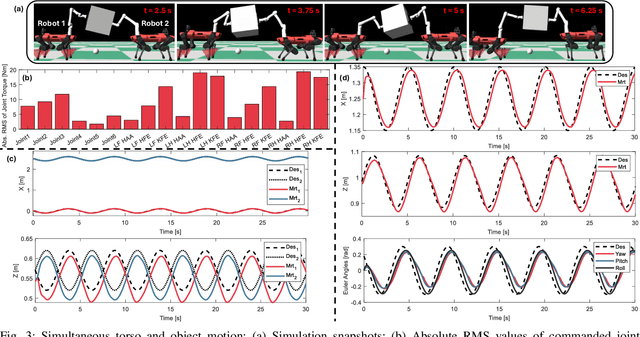
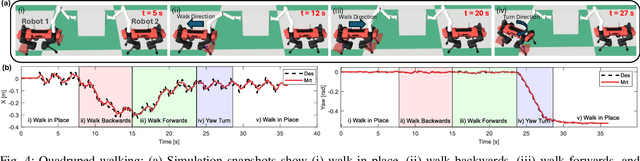
Utilizing teams of multiple robots is advantageous for handling bulky objects. Many related works focus on multi-manipulator systems, which are limited by workspace constraints. In this paper, we extend a classical hybrid motion-force controller to a team of legged manipulator systems, enabling collaborative loco-manipulation of rigid objects with a force-closed grasp. Our novel approach allows the robots to flexibly coordinate their movements, achieving efficient and stable object co-manipulation and transport, validated through extensive simulations and real-world experiments.
EndoFinder: Online Lesion Retrieval for Explainable Colorectal Polyp Diagnosis Leveraging Latent Scene Representations
Jul 23, 2025Colorectal cancer (CRC) remains a leading cause of cancer-related mortality, underscoring the importance of timely polyp detection and diagnosis. While deep learning models have improved optical-assisted diagnostics, they often demand extensive labeled datasets and yield "black-box" outputs with limited interpretability. In this paper, we propose EndoFinder, an online polyp retrieval framework that leverages multi-view scene representations for explainable and scalable CRC diagnosis. First, we develop a Polyp-aware Image Encoder by combining contrastive learning and a reconstruction task, guided by polyp segmentation masks. This self-supervised approach captures robust features without relying on large-scale annotated data. Next, we treat each polyp as a three-dimensional "scene" and introduce a Scene Representation Transformer, which fuses multiple views of the polyp into a single latent representation. By discretizing this representation through a hashing layer, EndoFinder enables real-time retrieval from a compiled database of historical polyp cases, where diagnostic information serves as interpretable references for new queries. We evaluate EndoFinder on both public and newly collected polyp datasets for re-identification and pathology classification. Results show that EndoFinder outperforms existing methods in accuracy while providing transparent, retrieval-based insights for clinical decision-making. By contributing a novel dataset and a scalable, explainable framework, our work addresses key challenges in polyp diagnosis and offers a promising direction for more efficient AI-driven colonoscopy workflows. The source code is available at https://github.com/ku262/EndoFinder-Scene.
Endo-CLIP: Progressive Self-Supervised Pre-training on Raw Colonoscopy Records
May 14, 2025



Pre-training on image-text colonoscopy records offers substantial potential for improving endoscopic image analysis, but faces challenges including non-informative background images, complex medical terminology, and ambiguous multi-lesion descriptions. We introduce Endo-CLIP, a novel self-supervised framework that enhances Contrastive Language-Image Pre-training (CLIP) for this domain. Endo-CLIP's three-stage framework--cleansing, attunement, and unification--addresses these challenges by (1) removing background frames, (2) leveraging large language models to extract clinical attributes for fine-grained contrastive learning, and (3) employing patient-level cross-attention to resolve multi-polyp ambiguities. Extensive experiments demonstrate that Endo-CLIP significantly outperforms state-of-the-art pre-training methods in zero-shot and few-shot polyp detection and classification, paving the way for more accurate and clinically relevant endoscopic analysis.