 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Variance to Invariance: Qualitative Content Analysis for Narrative Graph Annotation
Mar 04, 2026Narratives in news discourse play a critical role in shaping public understanding of economic events, such as inflation. Annotating and evaluating these narratives in a structured manner remains a key challenge for Natural Language Processing (NLP). In this work, we introduce a narrative graph annotation framework that integrates principles from qualitative content analysis (QCA) to prioritize annotation quality by reducing annotation errors. We present a dataset of inflation narratives annotated as directed acyclic graphs (DAGs), where nodes represent events and edges encode causal relations. To evaluate annotation quality, we employed a $6\times3$ factorial experimental design to examine the effects of narrative representation (six levels) and distance metric type (three levels) on inter-annotator agreement (Krippendorrf's $α$), capturing the presence of human label variation (HLV) in narrative interpretations. Our analysis shows that (1) lenient metrics (overlap-based distance) overestimate reliability, and (2) locally-constrained representations (e.g., one-hop neighbors) reduce annotation variability. Our annotation and implementation of graph-based Krippendorrf's $α$ are open-sourced. The annotation framework and evaluation results provide practical guidance for NLP research on graph-based narrative annotation under HLV.
AMA-Bench: Evaluating Long-Horizon Memory for Agentic Applications
Feb 26, 2026Large Language Models (LLMs) are deployed as autonomous agents in increasingly complex applications, where enabling long-horizon memory is critical for achieving strong performance. However, a significant gap exists between practical applications and current evaluation standards for agent memory: existing benchmarks primarily focus on dialogue-centric, human-agent interactions. In reality, agent memory consists of a continuous stream of agent-environment interactions that are primarily composed of machine-generated representations. To bridge this gap, we introduce AMA-Bench (Agent Memory with Any length), which evaluates long-horizon memory for LLMs in real agentic applications. It features two key components: (1) a set of real-world agentic trajectories across representative agentic applications, paired with expert-curated QA, and (2) a set of synthetic agentic trajectories that scale to arbitrary horizons, paired with rule-based QA. Our comprehensive study shows that existing memory systems underperform on AMA-Bench primarily because they lack causality and objective information and are constrained by the lossy nature of similarity-based retrieval employed by many memory systems. To address these limitations, we propose AMA-Agent, an effective memory system featuring a causality graph and tool-augmented retrieval. Our results demonstrate that AMA-Agent achieves 57.22% average accuracy on AMA-Bench, surpassing the strongest memory system baselines by 11.16%.
Robust Polyp Detection and Diagnosis through Compositional Prompt-Guided Diffusion Models
Feb 25, 2025Colorectal cancer (CRC) is a significant global health concern, and early detection through screening plays a critical role in reducing mortality. While deep learning models have shown promise in improving polyp detection, classification, and segmentation, their generalization across diverse clinical environments, particularly with out-of-distribution (OOD) data, remains a challenge. Multi-center datasets like PolypGen have been developed to address these issues, but their collection is costly and time-consuming. Traditional data augmentation techniques provide limited variability, failing to capture the complexity of medical images. Diffusion models have emerged as a promising solution for generating synthetic polyp images, but the image generation process in current models mainly relies on segmentation masks as the condition, limiting their ability to capture the full clinical context. To overcome these limitations, we propose a Progressive Spectrum Diffusion Model (PSDM) that integrates diverse clinical annotations-such as segmentation masks, bounding boxes, and colonoscopy reports-by transforming them into compositional prompts. These prompts are organized into coarse and fine components, allowing the model to capture both broad spatial structures and fine details, generating clinically accurate synthetic images. By augmenting training data with PSDM-generated samples, our model significantly improves polyp detection, classification, and segmentation. For instance, on the PolypGen dataset, PSDM increases the F1 score by 2.12% and the mean average precision by 3.09%, demonstrating superior performance in OOD scenarios and enhanced generalization.
Ontology-Guided, Hybrid Prompt Learning for Generalization in Knowledge Graph Question Answering
Feb 06, 2025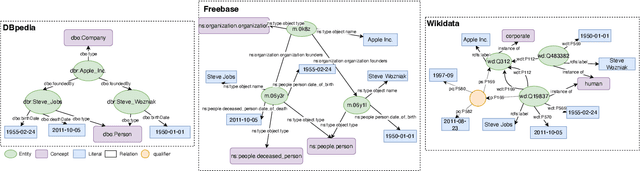
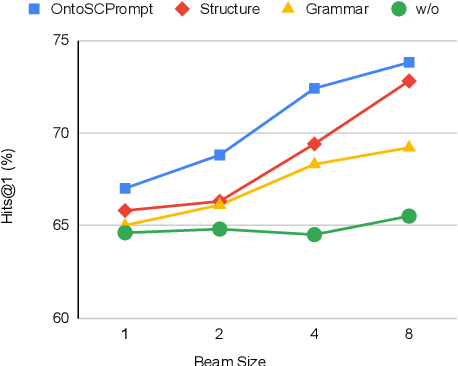


Most existing Knowledge Graph Question Answering (KGQA) approaches are designed for a specific KG, such as Wikidata, DBpedia or Freebase. Due to the heterogeneity of the underlying graph schema, topology and assertions, most KGQA systems cannot be transferred to unseen Knowledge Graphs (KGs) without resource-intensive training data. We present OntoSCPrompt, a novel Large Language Model (LLM)-based KGQA approach with a two-stage architecture that separates semantic parsing from KG-dependent interactions. OntoSCPrompt first generates a SPARQL query structure (including SPARQL keywords such as SELECT, ASK, WHERE and placeholders for missing tokens) and then fills them with KG-specific information. To enhance the understanding of the underlying KG, we present an ontology-guided, hybrid prompt learning strategy that integrates KG ontology into the learning process of hybrid prompts (e.g., discrete and continuous vectors). We also present several task-specific decoding strategies to ensure the correctness and executability of generated SPARQL queries in both stages. Experimental results demonstrate that OntoSCPrompt performs as well as SOTA approaches without retraining on a number of KGQA datasets such as CWQ, WebQSP and LC-QuAD 1.0 in a resource-efficient manner and can generalize well to unseen domain-specific KGs like DBLP-QuAD and CoyPu KG Code: \href{https://github.com/LongquanJiang/OntoSCPrompt}{https://github.com/LongquanJiang/OntoSCPrompt}
Reporting and Analysing the Environmental Impact of Language Models on the Example of Commonsense Question Answering with External Knowledge
Jul 24, 2024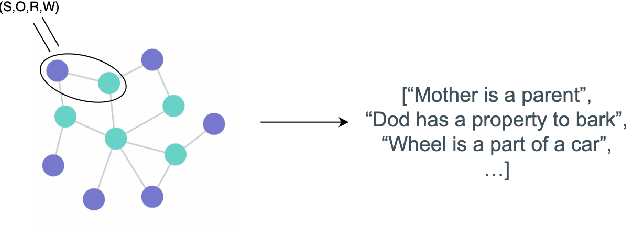
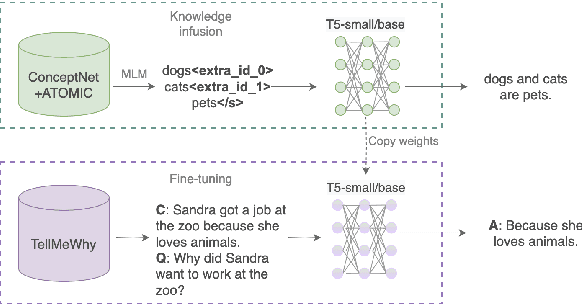
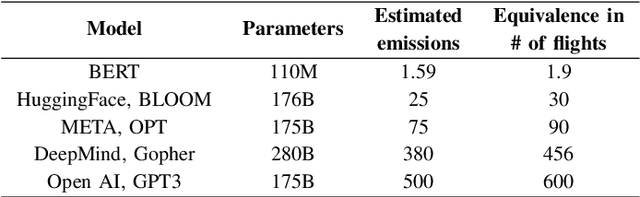
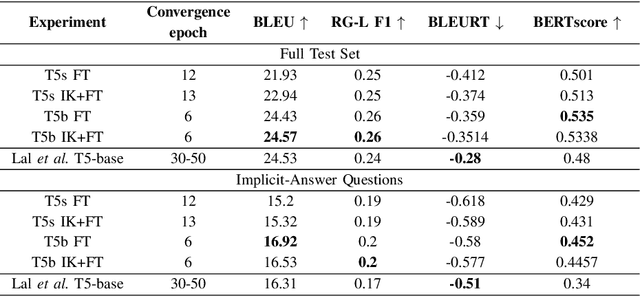
Human-produced emissions are growing at an alarming rate, causing already observable changes in the climate and environment in general. Each year global carbon dioxide emissions hit a new record, and it is reported that 0.5% of total US greenhouse gas emissions are attributed to data centres as of 2021. The release of ChatGPT in late 2022 sparked social interest in Large Language Models (LLMs), the new generation of Language Models with a large number of parameters and trained on massive amounts of data. Currently, numerous companies are releasing products featuring various LLMs, with many more models in development and awaiting release. Deep Learning research is a competitive field, with only models that reach top performance attracting attention and being utilized. Hence, achieving better accuracy and results is often the first priority, while the model's efficiency and the environmental impact of the study are neglected. However, LLMs demand substantial computational resources and are very costly to train, both financially and environmentally. It becomes essential to raise awareness and promote conscious decisions about algorithmic and hardware choices. Providing information on training time, the approximate carbon dioxide emissions and power consumption would assist future studies in making necessary adjustments and determining the compatibility of available computational resources with model requirements. In this study, we infused T5 LLM with external knowledge and fine-tuned the model for Question-Answering task. Furthermore, we calculated and reported the approximate environmental impact for both steps. The findings demonstrate that the smaller models may not always be sustainable options, and increased training does not always imply better performance. The most optimal outcome is achieved by carefully considering both performance and efficiency factors.
Master of Disaster: A Disaster-Related Event Monitoring System From News Streams
Jun 13, 2024The need for a disaster-related event monitoring system has arisen due to the societal and economic impact caused by the increasing number of severe disaster events. An event monitoring system should be able to extract event-related information from texts, and discriminates event instances. We demonstrate our open-source event monitoring system, namely, Master of Disaster (MoD), which receives news streams, extracts event information, links extracted information to a knowledge graph (KG), in this case Wikidata, and discriminates event instances visually. The goal of event visualization is to group event mentions referring to the same real-world event instance so that event instance discrimination can be achieved by visual screening.