 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntology-Guided, Hybrid Prompt Learning for Generalization in Knowledge Graph Question Answering
Feb 06, 2025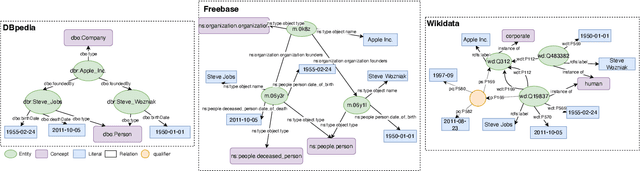
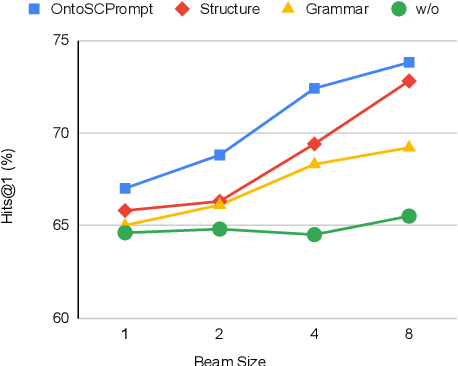


Most existing Knowledge Graph Question Answering (KGQA) approaches are designed for a specific KG, such as Wikidata, DBpedia or Freebase. Due to the heterogeneity of the underlying graph schema, topology and assertions, most KGQA systems cannot be transferred to unseen Knowledge Graphs (KGs) without resource-intensive training data. We present OntoSCPrompt, a novel Large Language Model (LLM)-based KGQA approach with a two-stage architecture that separates semantic parsing from KG-dependent interactions. OntoSCPrompt first generates a SPARQL query structure (including SPARQL keywords such as SELECT, ASK, WHERE and placeholders for missing tokens) and then fills them with KG-specific information. To enhance the understanding of the underlying KG, we present an ontology-guided, hybrid prompt learning strategy that integrates KG ontology into the learning process of hybrid prompts (e.g., discrete and continuous vectors). We also present several task-specific decoding strategies to ensure the correctness and executability of generated SPARQL queries in both stages. Experimental results demonstrate that OntoSCPrompt performs as well as SOTA approaches without retraining on a number of KGQA datasets such as CWQ, WebQSP and LC-QuAD 1.0 in a resource-efficient manner and can generalize well to unseen domain-specific KGs like DBLP-QuAD and CoyPu KG Code: \href{https://github.com/LongquanJiang/OntoSCPrompt}{https://github.com/LongquanJiang/OntoSCPrompt}
Biomedical Entity Linking with Triple-aware Pre-Training
Aug 28, 2023Linking biomedical entities is an essential aspect in biomedical natural language processing tasks, such as text mining and question answering. However, a difficulty of linking the biomedical entities using current large language models (LLM) trained on a general corpus is that biomedical entities are scarcely distributed in texts and therefore have been rarely seen during training by the LLM. At the same time, those LLMs are not aware of high level semantic connection between different biomedical entities, which are useful in identifying similar concepts in different textual contexts. To cope with aforementioned problems, some recent works focused on injecting knowledge graph information into LLMs. However, former methods either ignore the relational knowledge of the entities or lead to catastrophic forgetting. Therefore, we propose a novel framework to pre-train the powerful generative LLM by a corpus synthesized from a KG. In the evaluations we are unable to confirm the benefit of including synonym, description or relational information.
Survey on English Entity Linking on Wikidata
Dec 03, 2021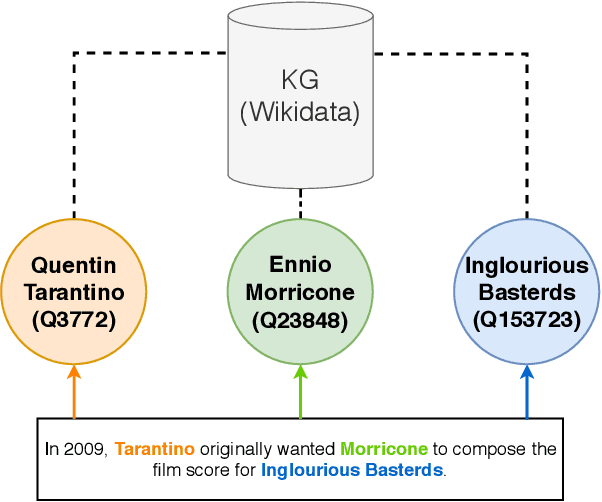

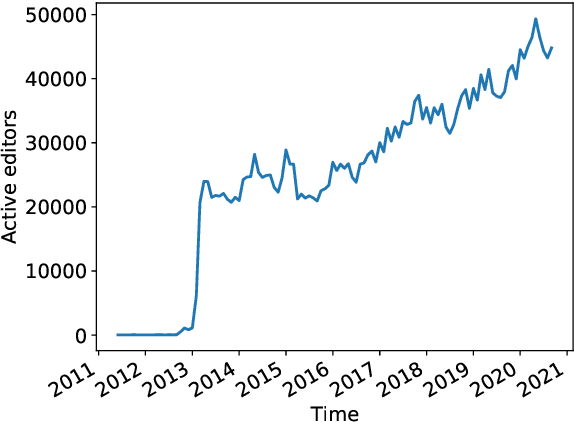
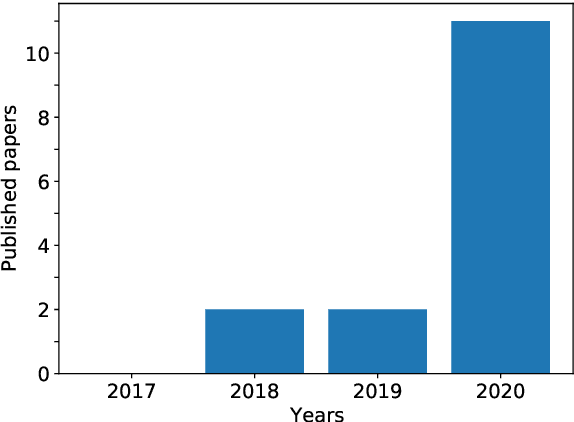
Wikidata is a frequently updated, community-driven, and multilingual knowledge graph. Hence, Wikidata is an attractive basis for Entity Linking, which is evident by the recent increase in published papers. This survey focuses on four subjects: (1) Which Wikidata Entity Linking datasets exist, how widely used are they and how are they constructed? (2) Do the characteristics of Wikidata matter for the design of Entity Linking datasets and if so, how? (3) How do current Entity Linking approaches exploit the specific characteristics of Wikidata? (4) Which Wikidata characteristics are unexploited by existing Entity Linking approaches? This survey reveals that current Wikidata-specific Entity Linking datasets do not differ in their annotation scheme from schemes for other knowledge graphs like DBpedia. Thus, the potential for multilingual and time-dependent datasets, naturally suited for Wikidata, is not lifted. Furthermore, we show that most Entity Linking approaches use Wikidata in the same way as any other knowledge graph missing the chance to leverage Wikidata-specific characteristics to increase quality. Almost all approaches employ specific properties like labels and sometimes descriptions but ignore characteristics such as the hyper-relational structure. Hence, there is still room for improvement, for example, by including hyper-relational graph embeddings or type information. Many approaches also include information from Wikipedia, which is easily combinable with Wikidata and provides valuable textual information, which Wikidata lacks.