 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfiliTable: Profiling-Driven Tabular Data Processing via Agentic Workflows
May 12, 2026Table processing-including cleaning, transformation, augmentation, and matching-is a foundational yet error-prone stage in real-world data pipelines. While recent LLM-based approaches show promise for automating such tasks, they often struggle in practice due to ambiguous instructions, complex task structures, and the lack of structured feedback, resulting in syntactically correct but semantically flawed code. To address these challenges, we propose ProfiliTable, an autonomous multi-agent framework centered on dynamic profiling, which constructs and iteratively refines a unified execution context through interactive exploration, knowledge-augmented synthesis, and feedback-driven refinement. ProfiliTable integrates (i) a Profiler that performs ReAct-style data exploration to build semantic understanding, (ii) a Generator that retrieves curated operators to synthesize task-aware code, and (iii) an Evaluator-Summarizer loop that injects execution scores and diagnostic insights to enable closed-loop refinement. Extensive experiments on a diverse benchmark covering 18 tabular task types demonstrate that ProfiliTable consistently outperforms strong baselines, particularly in complex multi-step scenarios. These results highlight the critical role of dynamic profiling in reliably translating ambiguous user intents into robust and governance-compliant table transformations.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Biomedical Entity Linking with Triple-aware Pre-Training
Aug 28, 2023Linking biomedical entities is an essential aspect in biomedical natural language processing tasks, such as text mining and question answering. However, a difficulty of linking the biomedical entities using current large language models (LLM) trained on a general corpus is that biomedical entities are scarcely distributed in texts and therefore have been rarely seen during training by the LLM. At the same time, those LLMs are not aware of high level semantic connection between different biomedical entities, which are useful in identifying similar concepts in different textual contexts. To cope with aforementioned problems, some recent works focused on injecting knowledge graph information into LLMs. However, former methods either ignore the relational knowledge of the entities or lead to catastrophic forgetting. Therefore, we propose a novel framework to pre-train the powerful generative LLM by a corpus synthesized from a KG. In the evaluations we are unable to confirm the benefit of including synonym, description or relational information.
Knowledge Graph Question Answering Leaderboard: A Community Resource to Prevent a Replication Crisis
Jan 20, 2022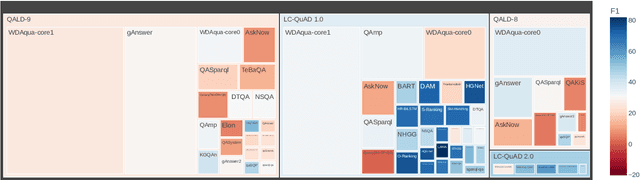
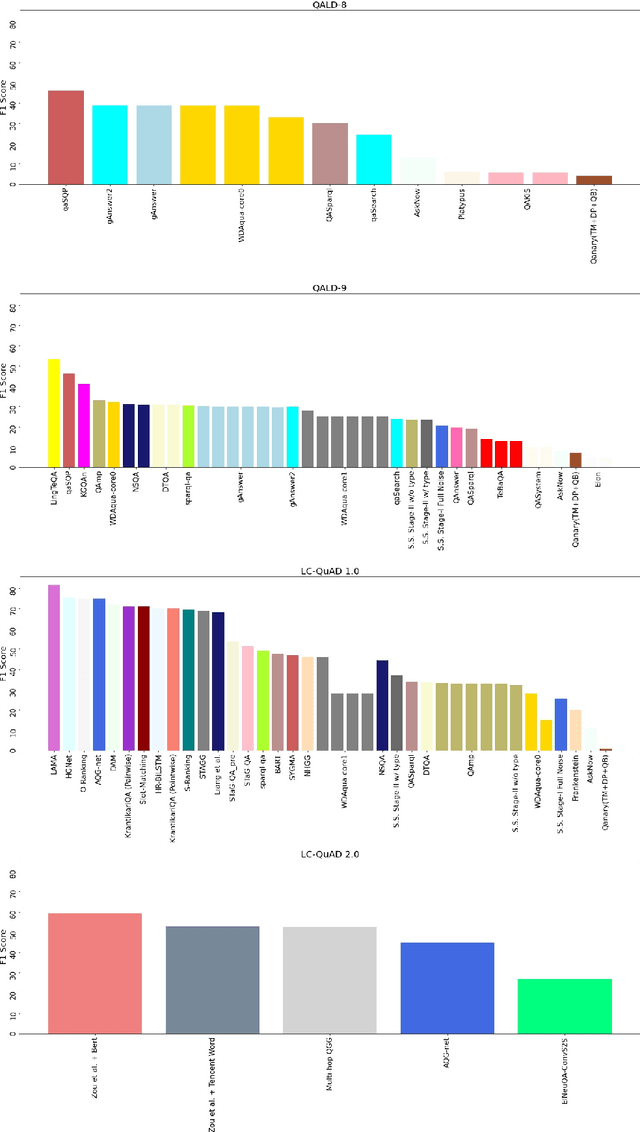
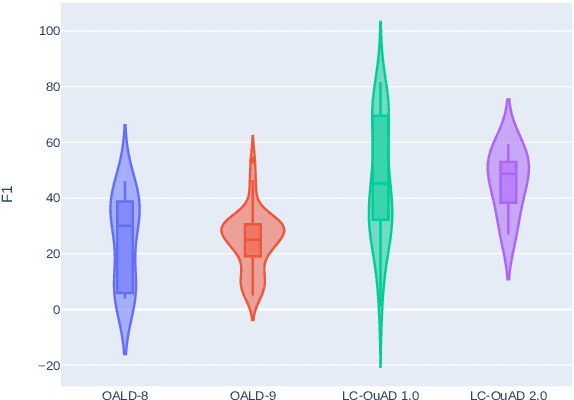
Data-driven systems need to be evaluated to establish trust in the scientific approach and its applicability. In particular, this is true for Knowledge Graph (KG) Question Answering (QA), where complex data structures are made accessible via natural-language interfaces. Evaluating the capabilities of these systems has been a driver for the community for more than ten years while establishing different KGQA benchmark datasets. However, comparing different approaches is cumbersome. The lack of existing and curated leaderboards leads to a missing global view over the research field and could inject mistrust into the results. In particular, the latest and most-used datasets in the KGQA community, LC-QuAD and QALD, miss providing central and up-to-date points of trust. In this paper, we survey and analyze a wide range of evaluation results with significant coverage of 100 publications and 98 systems from the last decade. We provide a new central and open leaderboard for any KGQA benchmark dataset as a focal point for the community - https://kgqa.github.io/leaderboard. Our analysis highlights existing problems during the evaluation of KGQA systems. Thus, we will point to possible improvements for future evaluations.
Neural Data Server: A Large-Scale Search Engine for Transfer Learning Data
Jan 09, 2020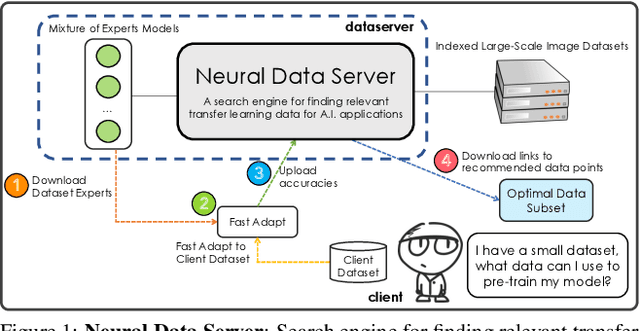
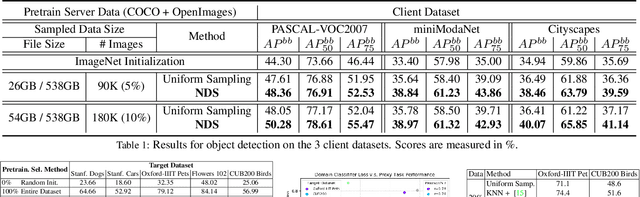

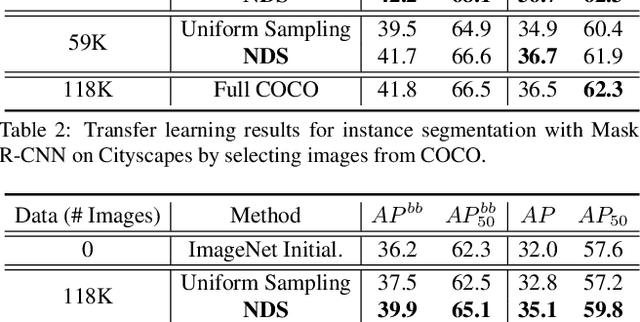
Transfer learning has proven to be a successful technique to train deep learning models in the domains where little training data is available. The dominant approach is to pretrain a model on a large generic dataset such as ImageNet and finetune its weights on the target domain. However, in the new era of an ever-increasing number of massive datasets, selecting the relevant data for pretraining is a critical issue. We introduce Neural Data Server (NDS), a large-scale search engine for finding the most useful transfer learning data to the target domain. Our NDS consists of a dataserver which indexes several large popular image datasets, and aims to recommend data to a client, an end-user with a target application with its own small labeled dataset. As in any search engine that serves information to possibly numerous users, we want the online computation performed by the dataserver to be minimal. The dataserver represents large datasets with a much more compact mixture-of experts model, and employs it to perform data search in a series of dataserver-client transactions at a low computational cost. We show the effectiveness of NDS in various transfer learning scenarios, demonstrating state-of-the-art performance on several target datasets and tasks such as image classification, object detection and instance segmentation. Our Neural Data Server is available as a web-service at http://aidemos.cs.toronto.edu/nds/, recommending data to users with the aim to improve performance of their A.I. application.