 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivasis: Synthesizing the Largest "Public" Private Dataset from Scratch
Feb 03, 2026Research involving privacy-sensitive data has always been constrained by data scarcity, standing in sharp contrast to other areas that have benefited from data scaling. This challenge is becoming increasingly urgent as modern AI agents--such as OpenClaw and Gemini Agent--are granted persistent access to highly sensitive personal information. To tackle this longstanding bottleneck and the rising risks, we present Privasis (i.e., privacy oasis), the first million-scale fully synthetic dataset entirely built from scratch--an expansive reservoir of texts with rich and diverse private information--designed to broaden and accelerate research in areas where processing sensitive social data is inevitable. Compared to existing datasets, Privasis, comprising 1.4 million records, offers orders-of-magnitude larger scale with quality, and far greater diversity across various document types, including medical history, legal documents, financial records, calendars, and text messages with a total of 55.1 million annotated attributes such as ethnicity, date of birth, workplace, etc. We leverage Privasis to construct a parallel corpus for text sanitization with our pipeline that decomposes texts and applies targeted sanitization. Our compact sanitization models (<=4B) trained on this dataset outperform state-of-the-art large language models, such as GPT-5 and Qwen-3 235B. We plan to release data, models, and code to accelerate future research on privacy-sensitive domains and agents.
Golden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text
Jan 30, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a cornerstone for unlocking complex reasoning in Large Language Models (LLMs). Yet, scaling up RL is bottlenecked by limited existing verifiable data, where improvements increasingly saturate over prolonged training. To overcome this, we propose Golden Goose, a simple trick to synthesize unlimited RLVR tasks from unverifiable internet text by constructing a multiple-choice question-answering version of the fill-in-the-middle task. Given a source text, we prompt an LLM to identify and mask key reasoning steps, then generate a set of diverse, plausible distractors. This enables us to leverage reasoning-rich unverifiable corpora typically excluded from prior RLVR data construction (e.g., science textbooks) to synthesize GooseReason-0.7M, a large-scale RLVR dataset with over 0.7 million tasks spanning mathematics, programming, and general scientific domains. Empirically, GooseReason effectively revives models saturated on existing RLVR data, yielding robust, sustained gains under continuous RL and achieving new state-of-the-art results for 1.5B and 4B-Instruct models across 15 diverse benchmarks. Finally, we deploy Golden Goose in a real-world setting, synthesizing RLVR tasks from raw FineWeb scrapes for the cybersecurity domain, where no prior RLVR data exists. Training Qwen3-4B-Instruct on the resulting data GooseReason-Cyber sets a new state-of-the-art in cybersecurity, surpassing a 7B domain-specialized model with extensive domain-specific pre-training and post-training. This highlights the potential of automatically scaling up RLVR data by exploiting abundant, reasoning-rich, unverifiable internet text.
Long Grounded Thoughts: Distilling Compositional Visual Reasoning Chains at Scale
Nov 07, 2025Recent progress in multimodal reasoning has been driven largely by undisclosed datasets and proprietary data synthesis recipes, leaving open questions about how to systematically build large-scale, vision-centric reasoning datasets, particularly for tasks that go beyond visual math. In this work, we introduce a new reasoning data generation framework spanning diverse skills and levels of complexity with over 1M high-quality synthetic vision-centric questions. The dataset also includes preference data and instruction prompts supporting both offline and online RL. Our synthesis framework proceeds in two stages: (1) scale; and (2) complexity. Reasoning traces are then synthesized through a two-stage process that leverages VLMs and reasoning LLMs, producing CoT traces for VLMs that capture the richness and diverse cognitive behaviors found in frontier reasoning models. Remarkably, we show that finetuning Qwen2.5-VL-7B on our data outperforms all open-data baselines across all evaluated vision-centric benchmarks, and even surpasses strong closed-data models such as MiMo-VL-7B-RL on V* Bench, CV-Bench and MMStar-V. Perhaps most surprising, despite being entirely vision-centric, our data transfers positively to text-only reasoning (MMLU-Pro) and audio reasoning (MMAU), demonstrating its effectiveness. Similarly, despite not containing videos or embodied visual data, we observe notable gains when evaluating on a single-evidence embodied QA benchmark (NiEH). Finally, we use our data to analyze the entire VLM post-training pipeline. Our empirical analysis highlights that (i) SFT on high-quality data with non-linear reasoning traces is essential for effective online RL, (ii) staged offline RL matches online RL's performance while reducing compute demands, and (iii) careful SFT on high quality data can substantially improve out-of-domain, cross-modality transfer.
Socratic-MCTS: Test-Time Visual Reasoning by Asking the Right Questions
Jun 10, 2025Recent research in vision-language models (VLMs) has centered around the possibility of equipping them with implicit long-form chain-of-thought reasoning -- akin to the success observed in language models -- via distillation and reinforcement learning. But what about the non-reasoning models already trained and deployed across the internet? Should we simply abandon them, or is there hope for a search mechanism that can elicit hidden knowledge and induce long reasoning traces -- without any additional training or supervision? In this paper, we explore this possibility using a Monte Carlo Tree Search (MCTS)-inspired algorithm, which injects subquestion-subanswer pairs into the model's output stream. We show that framing reasoning as a search process -- where subquestions act as latent decisions within a broader inference trajectory -- helps the model "connect the dots" between fragmented knowledge and produce extended reasoning traces in non-reasoning models. We evaluate our method across three benchmarks and observe consistent improvements. Notably, our approach yields a 2% overall improvement on MMMU-PRO, including a significant 9% gain in Liberal Arts.
Prismatic Synthesis: Gradient-based Data Diversification Boosts Generalization in LLM Reasoning
May 26, 2025Effective generalization in language models depends critically on the diversity of their training data. Yet existing diversity metrics often fall short of this goal, relying on surface-level heuristics that are decoupled from model behavior. This motivates us to ask: What kind of diversity in training data actually drives generalization in language models -- and how can we measure and amplify it? Through large-scale empirical analyses spanning over 300 training runs, carefully controlled for data scale and quality, we show that data diversity can be a strong predictor of generalization in LLM reasoning -- as measured by average model performance on unseen out-of-distribution benchmarks. We introduce G-Vendi, a metric that quantifies diversity via the entropy of model-induced gradients. Despite using a small off-the-shelf proxy model for gradients, G-Vendi consistently outperforms alternative measures, achieving strong correlation (Spearman's $\rho \approx 0.9$) with out-of-distribution (OOD) performance on both natural language inference (NLI) and math reasoning tasks. Building on this insight, we present Prismatic Synthesis, a framework for generating diverse synthetic data by targeting underrepresented regions in gradient space. Experimental results show that Prismatic Synthesis consistently improves model performance as we scale synthetic data -- not just on in-distribution test but across unseen, out-of-distribution benchmarks -- significantly outperforming state-of-the-art models that rely on 20 times larger data generator than ours. For example, PrismMath-7B, our model distilled from a 32B LLM, outperforms R1-Distill-Qwen-7B -- the same base model trained on proprietary data generated by 671B R1 -- on 6 out of 7 challenging benchmarks.
LongPerceptualThoughts: Distilling System-2 Reasoning for System-1 Perception
Apr 21, 2025Recent reasoning models through test-time scaling have demonstrated that long chain-of-thoughts can unlock substantial performance boosts in hard reasoning tasks such as math and code. However, the benefit of such long thoughts for system-2 reasoning is relatively less explored in other domains such as perceptual tasks where shallower, system-1 reasoning seems sufficient. In this paper, we introduce LongPerceptualThoughts, a new synthetic dataset with 30K long-thought traces for perceptual tasks. The key challenges in synthesizing elaborate reasoning thoughts for perceptual tasks are that off-the-shelf models are not yet equipped with such thinking behavior and that it is not straightforward to build a reliable process verifier for perceptual tasks. Thus, we propose a novel three-stage data synthesis framework that first synthesizes verifiable multiple-choice questions from dense image descriptions, then extracts simple CoTs from VLMs for those verifiable problems, and finally expands those simple thoughts to elaborate long thoughts via frontier reasoning models. In controlled experiments with a strong instruction-tuned 7B model, we demonstrate notable improvements over existing visual reasoning data-generation methods. Our model, trained on the generated dataset, achieves an average +3.4 points improvement over 5 vision-centric benchmarks, including +11.8 points on V$^*$ Bench. Notably, despite being tuned for vision tasks, it also improves performance on the text reasoning benchmark, MMLU-Pro, by +2 points.
Retro-Search: Exploring Untaken Paths for Deeper and Efficient Reasoning
Apr 06, 2025



Large reasoning models exhibit remarkable reasoning capabilities via long, elaborate reasoning trajectories. Supervised fine-tuning on such reasoning traces, also known as distillation, can be a cost-effective way to boost reasoning capabilities of student models. However, empirical observations reveal that these reasoning trajectories are often suboptimal, switching excessively between different lines of thought, resulting in under-thinking, over-thinking, and even degenerate responses. We introduce Retro-Search, an MCTS-inspired search algorithm, for distilling higher quality reasoning paths from large reasoning models. Retro-Search retrospectively revises reasoning paths to discover better, yet shorter traces, which can then lead to student models with enhanced reasoning capabilities with shorter, thus faster inference. Our approach can enable two use cases: self-improvement, where models are fine-tuned on their own Retro-Search-ed thought traces, and weak-to-strong improvement, where a weaker model revises stronger model's thought traces via Retro-Search. For self-improving, R1-distill-7B, fine-tuned on its own Retro-Search-ed traces, reduces the average reasoning length by 31.2% while improving performance by 7.7% across seven math benchmarks. For weak-to-strong improvement, we retrospectively revise R1-671B's traces from the OpenThoughts dataset using R1-distill-32B as the Retro-Search-er, a model 20x smaller. Qwen2.5-32B, fine-tuned on this refined data, achieves performance comparable to R1-distill-32B, yielding an 11.3% reduction in reasoning length and a 2.4% performance improvement compared to fine-tuning on the original OpenThoughts data. Our work counters recently emergent viewpoints that question the relevance of search algorithms in the era of large reasoning models, by demonstrating that there are still opportunities for algorithmic advancements, even for frontier models.
Reasoning Paths with Reference Objects Elicit Quantitative Spatial Reasoning in Large Vision-Language Models
Sep 15, 2024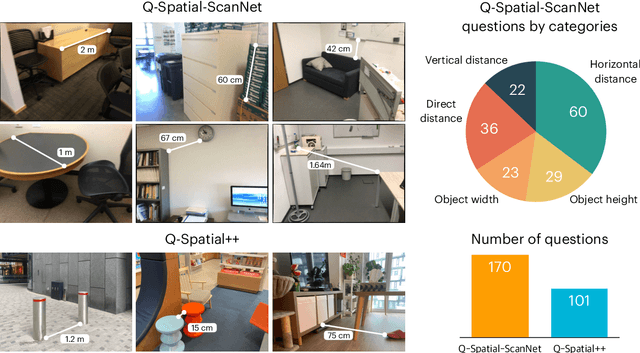
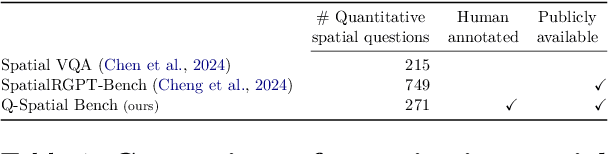
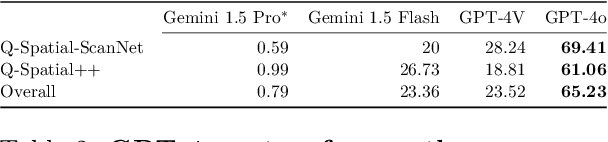

Despite recent advances demonstrating vision-language models' (VLMs) abilities to describe complex relationships in images using natural language, their capability to quantitatively reason about object sizes and distances remains underexplored. In this work, we introduce a manually annotated benchmark, Q-Spatial Bench, with 271 questions across five categories designed for quantitative spatial reasoning and systematically investigate the performance of state-of-the-art VLMs on this task. Our analysis reveals that reasoning about distances between objects is particularly challenging for SoTA VLMs; however, some VLMs significantly outperform others, with an over 40-point gap between the two best performing models. We also make the surprising observation that the success rate of the top-performing VLM increases by 19 points when a reasoning path using a reference object emerges naturally in the response. Inspired by this observation, we develop a zero-shot prompting technique, SpatialPrompt, that encourages VLMs to answer quantitative spatial questions using reference objects as visual cues. By instructing VLMs to use reference objects in their reasoning paths via SpatialPrompt, Gemini 1.5 Pro, Gemini 1.5 Flash, and GPT-4V improve their success rates by over 40, 20, and 30 points, respectively. We emphasize that these significant improvements are obtained without needing more data, model architectural modifications, or fine-tuning.
Photorealistic Object Insertion with Diffusion-Guided Inverse Rendering
Aug 19, 2024
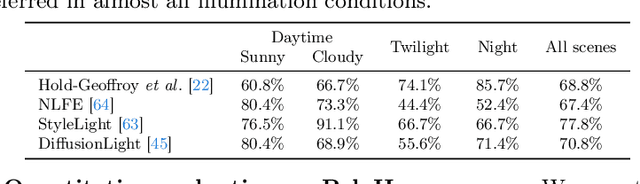
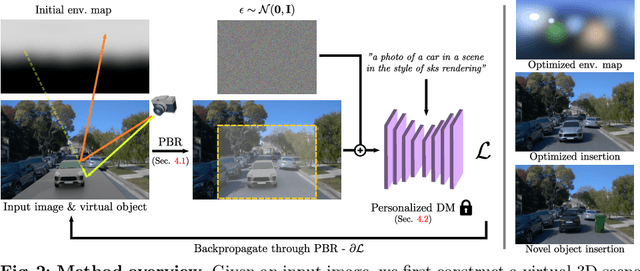
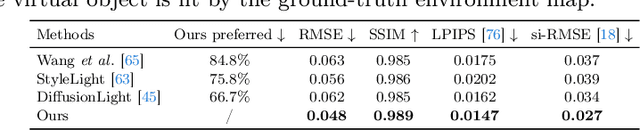
The correct insertion of virtual objects in images of real-world scenes requires a deep understanding of the scene's lighting, geometry and materials, as well as the image formation process. While recent large-scale diffusion models have shown strong generative and inpainting capabilities, we find that current models do not sufficiently "understand" the scene shown in a single picture to generate consistent lighting effects (shadows, bright reflections, etc.) while preserving the identity and details of the composited object. We propose using a personalized large diffusion model as guidance to a physically based inverse rendering process. Our method recovers scene lighting and tone-mapping parameters, allowing the photorealistic composition of arbitrary virtual objects in single frames or videos of indoor or outdoor scenes. Our physically based pipeline further enables automatic materials and tone-mapping refinement.
RefFusion: Reference Adapted Diffusion Models for 3D Scene Inpainting
Apr 16, 2024


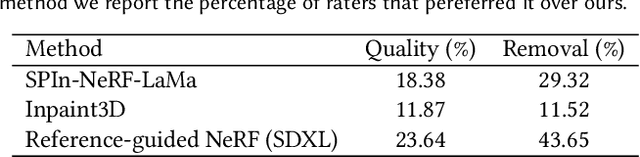
Neural reconstruction approaches are rapidly emerging as the preferred representation for 3D scenes, but their limited editability is still posing a challenge. In this work, we propose an approach for 3D scene inpainting -- the task of coherently replacing parts of the reconstructed scene with desired content. Scene inpainting is an inherently ill-posed task as there exist many solutions that plausibly replace the missing content. A good inpainting method should therefore not only enable high-quality synthesis but also a high degree of control. Based on this observation, we focus on enabling explicit control over the inpainted content and leverage a reference image as an efficient means to achieve this goal. Specifically, we introduce RefFusion, a novel 3D inpainting method based on a multi-scale personalization of an image inpainting diffusion model to the given reference view. The personalization effectively adapts the prior distribution to the target scene, resulting in a lower variance of score distillation objective and hence significantly sharper details. Our framework achieves state-of-the-art results for object removal while maintaining high controllability. We further demonstrate the generality of our formulation on other downstream tasks such as object insertion, scene outpainting, and sparse view reconstruction.