 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCube: A Roblox View of 3D Intelligence
Mar 19, 2025



Foundation models trained on vast amounts of data have demonstrated remarkable reasoning and generation capabilities in the domains of text, images, audio and video. Our goal at Roblox is to build such a foundation model for 3D intelligence, a model that can support developers in producing all aspects of a Roblox experience, from generating 3D objects and scenes to rigging characters for animation to producing programmatic scripts describing object behaviors. We discuss three key design requirements for such a 3D foundation model and then present our first step towards building such a model. We expect that 3D geometric shapes will be a core data type and describe our solution for 3D shape tokenizer. We show how our tokenization scheme can be used in applications for text-to-shape generation, shape-to-text generation and text-to-scene generation. We demonstrate how these applications can collaborate with existing large language models (LLMs) to perform scene analysis and reasoning. We conclude with a discussion outlining our path to building a fully unified foundation model for 3D intelligence.
Playground v3: Improving Text-to-Image Alignment with Deep-Fusion Large Language Models
Sep 16, 2024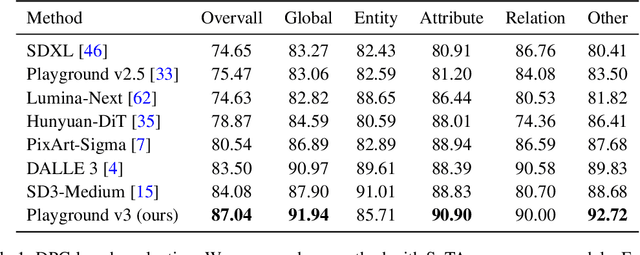
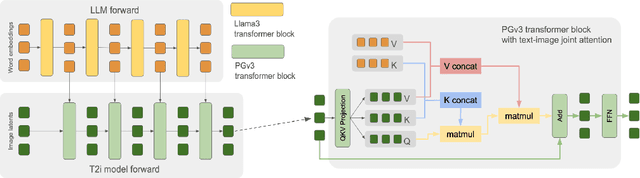
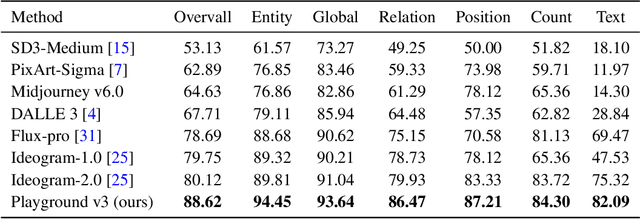

We introduce Playground v3 (PGv3), our latest text-to-image model that achieves state-of-the-art (SoTA) performance across multiple testing benchmarks, excels in graphic design abilities and introduces new capabilities. Unlike traditional text-to-image generative models that rely on pre-trained language models like T5 or CLIP text encoders, our approach fully integrates Large Language Models (LLMs) with a novel structure that leverages text conditions exclusively from a decoder-only LLM. Additionally, to enhance image captioning quality-we developed an in-house captioner, capable of generating captions with varying levels of detail, enriching the diversity of text structures. We also introduce a new benchmark CapsBench to evaluate detailed image captioning performance. Experimental results demonstrate that PGv3 excels in text prompt adherence, complex reasoning, and accurate text rendering. User preference studies indicate the super-human graphic design ability of our model for common design applications, such as stickers, posters, and logo designs. Furthermore, PGv3 introduces new capabilities, including precise RGB color control and robust multilingual understanding.
Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation
Feb 27, 2024In this work, we share three insights for achieving state-of-the-art aesthetic quality in text-to-image generative models. We focus on three critical aspects for model improvement: enhancing color and contrast, improving generation across multiple aspect ratios, and improving human-centric fine details. First, we delve into the significance of the noise schedule in training a diffusion model, demonstrating its profound impact on realism and visual fidelity. Second, we address the challenge of accommodating various aspect ratios in image generation, emphasizing the importance of preparing a balanced bucketed dataset. Lastly, we investigate the crucial role of aligning model outputs with human preferences, ensuring that generated images resonate with human perceptual expectations. Through extensive analysis and experiments, Playground v2.5 demonstrates state-of-the-art performance in terms of aesthetic quality under various conditions and aspect ratios, outperforming both widely-used open-source models like SDXL and Playground v2, and closed-source commercial systems such as DALLE 3 and Midjourney v5.2. Our model is open-source, and we hope the development of Playground v2.5 provides valuable guidelines for researchers aiming to elevate the aesthetic quality of diffusion-based image generation models.
RadImageGAN -- A Multi-modal Dataset-Scale Generative AI for Medical Imaging
Dec 10, 2023



Deep learning in medical imaging often requires large-scale, high-quality data or initiation with suitably pre-trained weights. However, medical datasets are limited by data availability, domain-specific knowledge, and privacy concerns, and the creation of large and diverse radiologic databases like RadImageNet is highly resource-intensive. To address these limitations, we introduce RadImageGAN, the first multi-modal radiologic data generator, which was developed by training StyleGAN-XL on the real RadImageNet dataset of 102,774 patients. RadImageGAN can generate high-resolution synthetic medical imaging datasets across 12 anatomical regions and 130 pathological classes in 3 modalities. Furthermore, we demonstrate that RadImageGAN generators can be utilized with BigDatasetGAN to generate multi-class pixel-wise annotated paired synthetic images and masks for diverse downstream segmentation tasks with minimal manual annotation. We showed that using synthetic auto-labeled data from RadImageGAN can significantly improve performance on four diverse downstream segmentation datasets by augmenting real training data and/or developing pre-trained weights for fine-tuning. This shows that RadImageGAN combined with BigDatasetGAN can improve model performance and address data scarcity while reducing the resources needed for annotations for segmentation tasks.
DreamTeacher: Pretraining Image Backbones with Deep Generative Models
Jul 14, 2023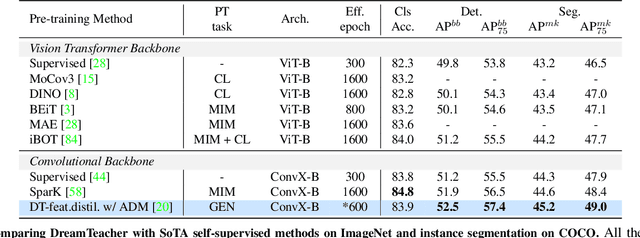
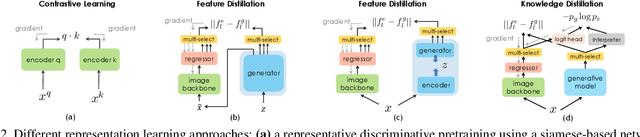
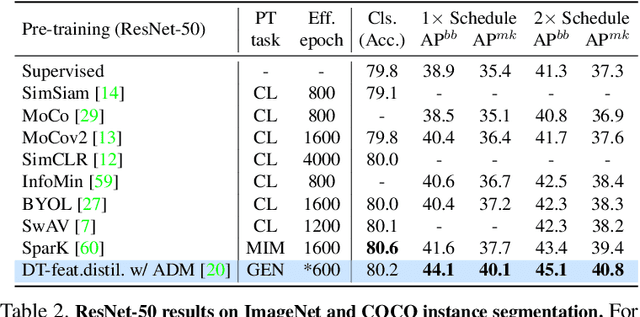
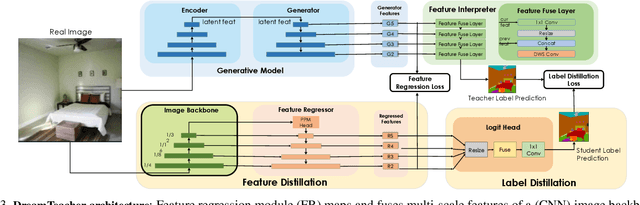
In this work, we introduce a self-supervised feature representation learning framework DreamTeacher that utilizes generative networks for pre-training downstream image backbones. We propose to distill knowledge from a trained generative model into standard image backbones that have been well engineered for specific perception tasks. We investigate two types of knowledge distillation: 1) distilling learned generative features onto target image backbones as an alternative to pretraining these backbones on large labeled datasets such as ImageNet, and 2) distilling labels obtained from generative networks with task heads onto logits of target backbones. We perform extensive analyses on multiple generative models, dense prediction benchmarks, and several pre-training regimes. We empirically find that our DreamTeacher significantly outperforms existing self-supervised representation learning approaches across the board. Unsupervised ImageNet pre-training with DreamTeacher leads to significant improvements over ImageNet classification pre-training on downstream datasets, showcasing generative models, and diffusion generative models specifically, as a promising approach to representation learning on large, diverse datasets without requiring manual annotation.
NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models
Apr 19, 2023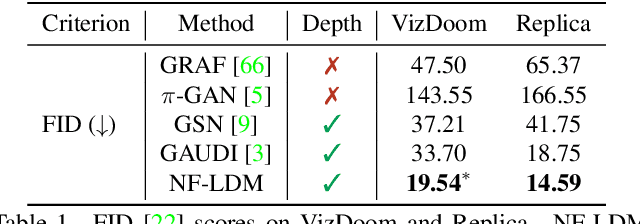
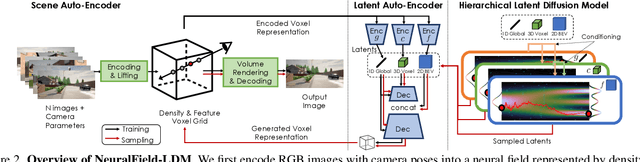

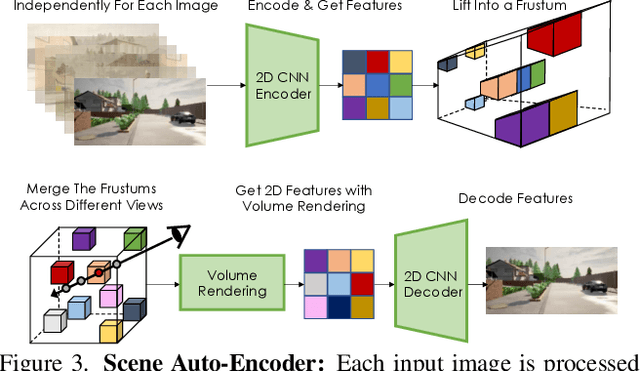
Automatically generating high-quality real world 3D scenes is of enormous interest for applications such as virtual reality and robotics simulation. Towards this goal, we introduce NeuralField-LDM, a generative model capable of synthesizing complex 3D environments. We leverage Latent Diffusion Models that have been successfully utilized for efficient high-quality 2D content creation. We first train a scene auto-encoder to express a set of image and pose pairs as a neural field, represented as density and feature voxel grids that can be projected to produce novel views of the scene. To further compress this representation, we train a latent-autoencoder that maps the voxel grids to a set of latent representations. A hierarchical diffusion model is then fit to the latents to complete the scene generation pipeline. We achieve a substantial improvement over existing state-of-the-art scene generation models. Additionally, we show how NeuralField-LDM can be used for a variety of 3D content creation applications, including conditional scene generation, scene inpainting and scene style manipulation.
GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images
Sep 22, 2022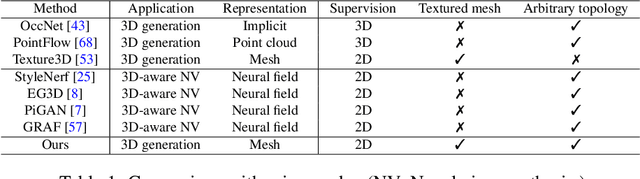

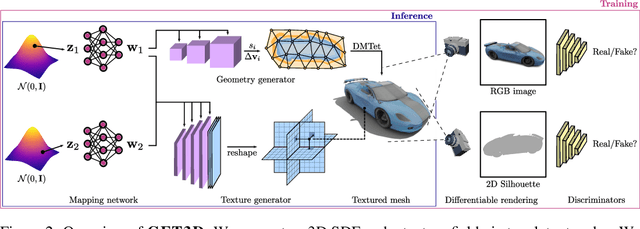
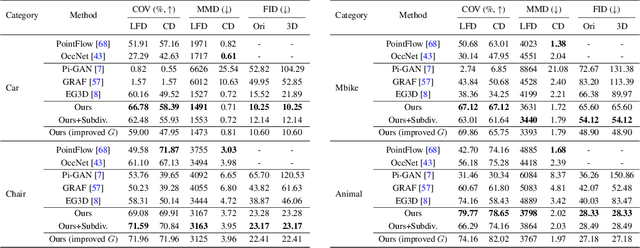
As several industries are moving towards modeling massive 3D virtual worlds, the need for content creation tools that can scale in terms of the quantity, quality, and diversity of 3D content is becoming evident. In our work, we aim to train performant 3D generative models that synthesize textured meshes which can be directly consumed by 3D rendering engines, thus immediately usable in downstream applications. Prior works on 3D generative modeling either lack geometric details, are limited in the mesh topology they can produce, typically do not support textures, or utilize neural renderers in the synthesis process, which makes their use in common 3D software non-trivial. In this work, we introduce GET3D, a Generative model that directly generates Explicit Textured 3D meshes with complex topology, rich geometric details, and high-fidelity textures. We bridge recent success in the differentiable surface modeling, differentiable rendering as well as 2D Generative Adversarial Networks to train our model from 2D image collections. GET3D is able to generate high-quality 3D textured meshes, ranging from cars, chairs, animals, motorbikes and human characters to buildings, achieving significant improvements over previous methods.
How Much More Data Do I Need? Estimating Requirements for Downstream Tasks
Jul 13, 2022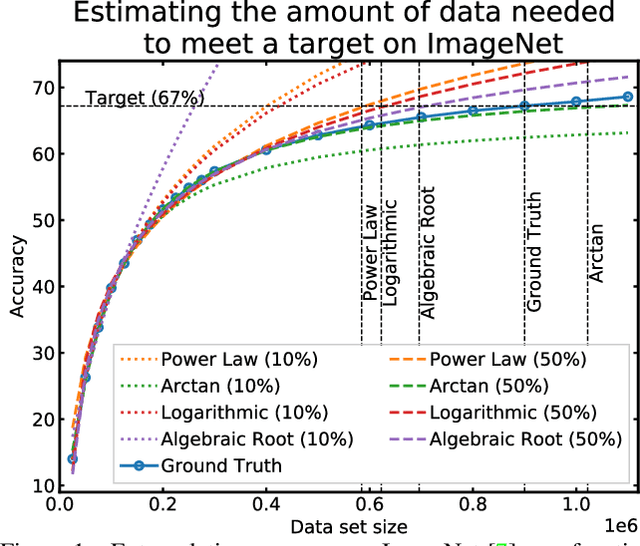

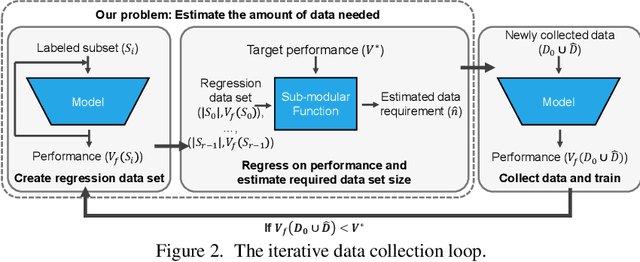
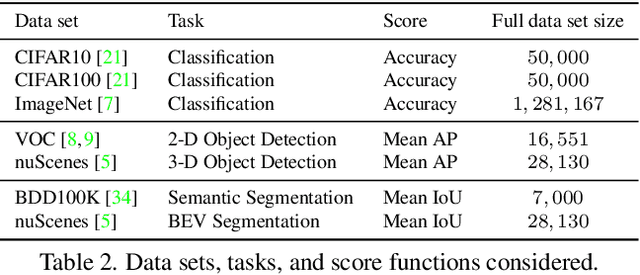
Given a small training data set and a learning algorithm, how much more data is necessary to reach a target validation or test performance? This question is of critical importance in applications such as autonomous driving or medical imaging where collecting data is expensive and time-consuming. Overestimating or underestimating data requirements incurs substantial costs that could be avoided with an adequate budget. Prior work on neural scaling laws suggest that the power-law function can fit the validation performance curve and extrapolate it to larger data set sizes. We find that this does not immediately translate to the more difficult downstream task of estimating the required data set size to meet a target performance. In this work, we consider a broad class of computer vision tasks and systematically investigate a family of functions that generalize the power-law function to allow for better estimation of data requirements. Finally, we show that incorporating a tuned correction factor and collecting over multiple rounds significantly improves the performance of the data estimators. Using our guidelines, practitioners can accurately estimate data requirements of machine learning systems to gain savings in both development time and data acquisition costs.
Polymorphic-GAN: Generating Aligned Samples across Multiple Domains with Learned Morph Maps
Jun 06, 2022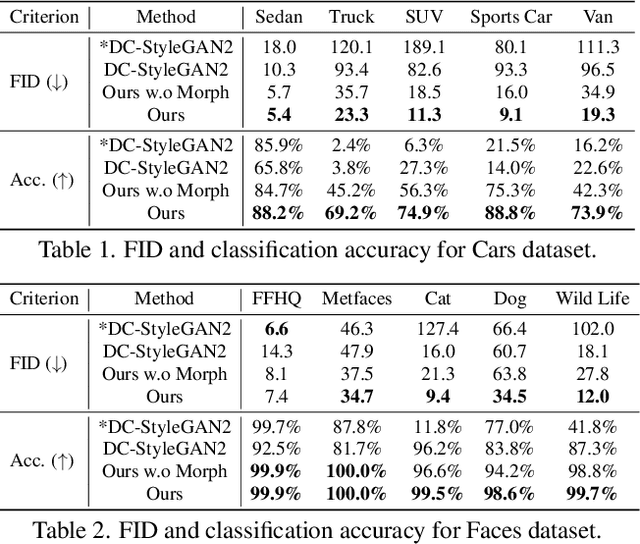
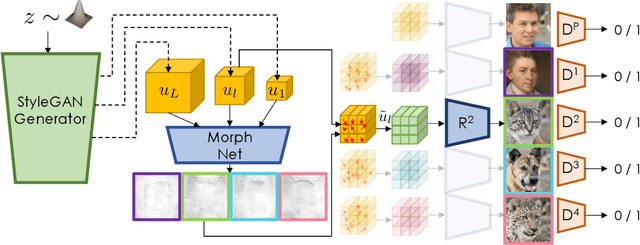

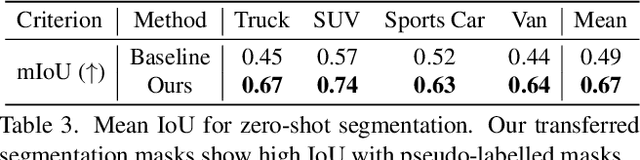
Modern image generative models show remarkable sample quality when trained on a single domain or class of objects. In this work, we introduce a generative adversarial network that can simultaneously generate aligned image samples from multiple related domains. We leverage the fact that a variety of object classes share common attributes, with certain geometric differences. We propose Polymorphic-GAN which learns shared features across all domains and a per-domain morph layer to morph shared features according to each domain. In contrast to previous works, our framework allows simultaneous modelling of images with highly varying geometries, such as images of human faces, painted and artistic faces, as well as multiple different animal faces. We demonstrate that our model produces aligned samples for all domains and show how it can be used for applications such as segmentation transfer and cross-domain image editing, as well as training in low-data regimes. Additionally, we apply our Polymorphic-GAN on image-to-image translation tasks and show that we can greatly surpass previous approaches in cases where the geometric differences between domains are large.
BigDatasetGAN: Synthesizing ImageNet with Pixel-wise Annotations
Jan 12, 2022

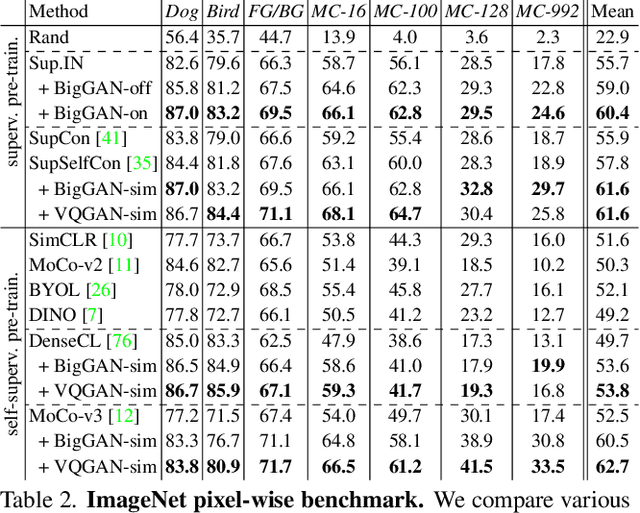
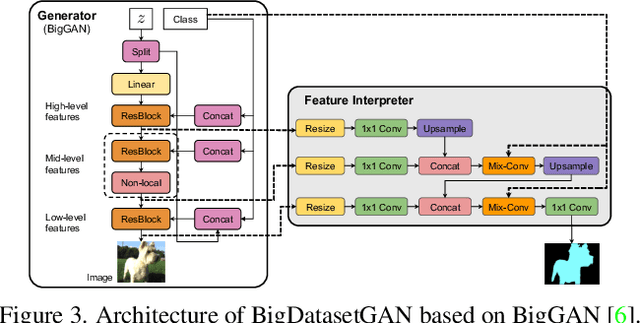
Annotating images with pixel-wise labels is a time-consuming and costly process. Recently, DatasetGAN showcased a promising alternative - to synthesize a large labeled dataset via a generative adversarial network (GAN) by exploiting a small set of manually labeled, GAN-generated images. Here, we scale DatasetGAN to ImageNet scale of class diversity. We take image samples from the class-conditional generative model BigGAN trained on ImageNet, and manually annotate 5 images per class, for all 1k classes. By training an effective feature segmentation architecture on top of BigGAN, we turn BigGAN into a labeled dataset generator. We further show that VQGAN can similarly serve as a dataset generator, leveraging the already annotated data. We create a new ImageNet benchmark by labeling an additional set of 8k real images and evaluate segmentation performance in a variety of settings. Through an extensive ablation study we show big gains in leveraging a large generated dataset to train different supervised and self-supervised backbone models on pixel-wise tasks. Furthermore, we demonstrate that using our synthesized datasets for pre-training leads to improvements over standard ImageNet pre-training on several downstream datasets, such as PASCAL-VOC, MS-COCO, Cityscapes and chest X-ray, as well as tasks (detection, segmentation). Our benchmark will be made public and maintain a leaderboard for this challenging task. Project Page: https://nv-tlabs.github.io/big-datasetgan/