 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexFusion: Synthesizing 3D Textures with Text-Guided Image Diffusion Models
Oct 20, 2023

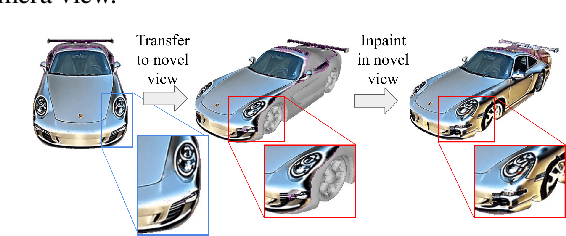

We present TexFusion (Texture Diffusion), a new method to synthesize textures for given 3D geometries, using large-scale text-guided image diffusion models. In contrast to recent works that leverage 2D text-to-image diffusion models to distill 3D objects using a slow and fragile optimization process, TexFusion introduces a new 3D-consistent generation technique specifically designed for texture synthesis that employs regular diffusion model sampling on different 2D rendered views. Specifically, we leverage latent diffusion models, apply the diffusion model's denoiser on a set of 2D renders of the 3D object, and aggregate the different denoising predictions on a shared latent texture map. Final output RGB textures are produced by optimizing an intermediate neural color field on the decodings of 2D renders of the latent texture. We thoroughly validate TexFusion and show that we can efficiently generate diverse, high quality and globally coherent textures. We achieve state-of-the-art text-guided texture synthesis performance using only image diffusion models, while avoiding the pitfalls of previous distillation-based methods. The text-conditioning offers detailed control and we also do not rely on any ground truth 3D textures for training. This makes our method versatile and applicable to a broad range of geometry and texture types. We hope that TexFusion will advance AI-based texturing of 3D assets for applications in virtual reality, game design, simulation, and more.
* Videos and more results on https://research.nvidia.com/labs/toronto-ai/texfusion/
Flexible Isosurface Extraction for Gradient-Based Mesh Optimization
Aug 10, 2023This work considers gradient-based mesh optimization, where we iteratively optimize for a 3D surface mesh by representing it as the isosurface of a scalar field, an increasingly common paradigm in applications including photogrammetry, generative modeling, and inverse physics. Existing implementations adapt classic isosurface extraction algorithms like Marching Cubes or Dual Contouring; these techniques were designed to extract meshes from fixed, known fields, and in the optimization setting they lack the degrees of freedom to represent high-quality feature-preserving meshes, or suffer from numerical instabilities. We introduce FlexiCubes, an isosurface representation specifically designed for optimizing an unknown mesh with respect to geometric, visual, or even physical objectives. Our main insight is to introduce additional carefully-chosen parameters into the representation, which allow local flexible adjustments to the extracted mesh geometry and connectivity. These parameters are updated along with the underlying scalar field via automatic differentiation when optimizing for a downstream task. We base our extraction scheme on Dual Marching Cubes for improved topological properties, and present extensions to optionally generate tetrahedral and hierarchically-adaptive meshes. Extensive experiments validate FlexiCubes on both synthetic benchmarks and real-world applications, showing that it offers significant improvements in mesh quality and geometric fidelity.
* SIGGRAPH 2023. Project page: https://research.nvidia.com/labs/toronto-ai/flexicubes/
NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models
Apr 19, 2023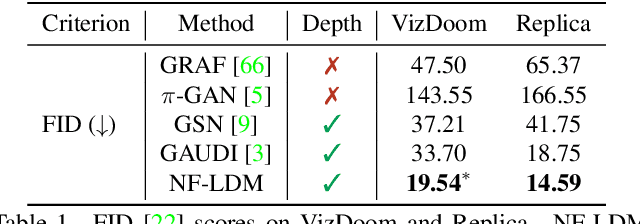
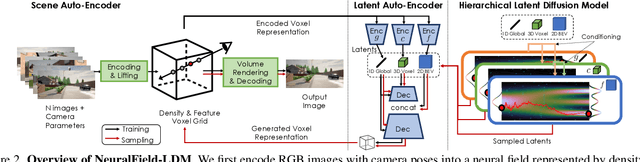

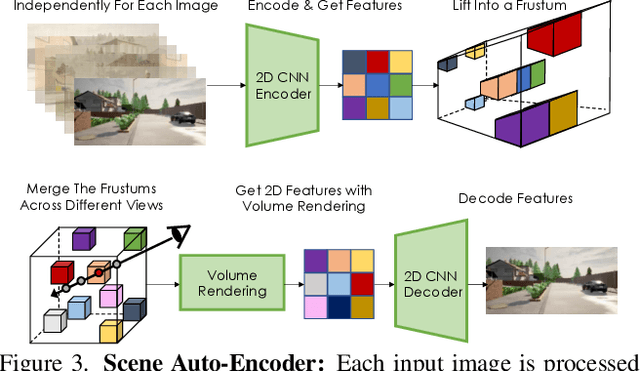
Automatically generating high-quality real world 3D scenes is of enormous interest for applications such as virtual reality and robotics simulation. Towards this goal, we introduce NeuralField-LDM, a generative model capable of synthesizing complex 3D environments. We leverage Latent Diffusion Models that have been successfully utilized for efficient high-quality 2D content creation. We first train a scene auto-encoder to express a set of image and pose pairs as a neural field, represented as density and feature voxel grids that can be projected to produce novel views of the scene. To further compress this representation, we train a latent-autoencoder that maps the voxel grids to a set of latent representations. A hierarchical diffusion model is then fit to the latents to complete the scene generation pipeline. We achieve a substantial improvement over existing state-of-the-art scene generation models. Additionally, we show how NeuralField-LDM can be used for a variety of 3D content creation applications, including conditional scene generation, scene inpainting and scene style manipulation.
GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images
Sep 22, 2022

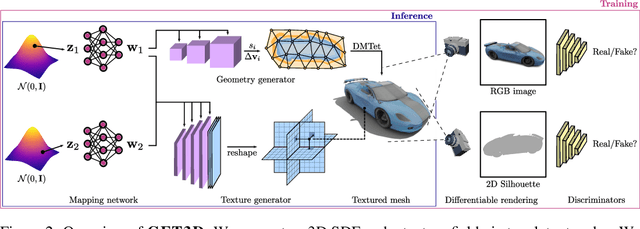
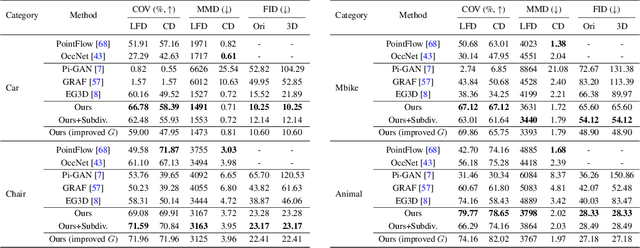
As several industries are moving towards modeling massive 3D virtual worlds, the need for content creation tools that can scale in terms of the quantity, quality, and diversity of 3D content is becoming evident. In our work, we aim to train performant 3D generative models that synthesize textured meshes which can be directly consumed by 3D rendering engines, thus immediately usable in downstream applications. Prior works on 3D generative modeling either lack geometric details, are limited in the mesh topology they can produce, typically do not support textures, or utilize neural renderers in the synthesis process, which makes their use in common 3D software non-trivial. In this work, we introduce GET3D, a Generative model that directly generates Explicit Textured 3D meshes with complex topology, rich geometric details, and high-fidelity textures. We bridge recent success in the differentiable surface modeling, differentiable rendering as well as 2D Generative Adversarial Networks to train our model from 2D image collections. GET3D is able to generate high-quality 3D textured meshes, ranging from cars, chairs, animals, motorbikes and human characters to buildings, achieving significant improvements over previous methods.
MvDeCor: Multi-view Dense Correspondence Learning for Fine-grained 3D Segmentation
Aug 18, 2022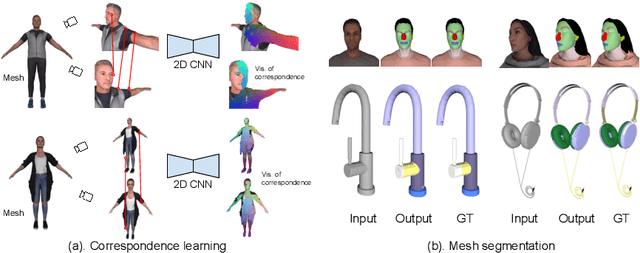
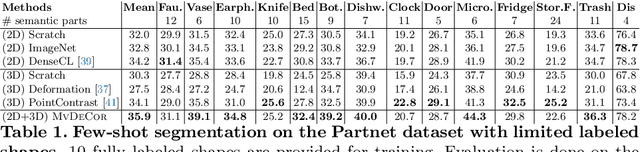
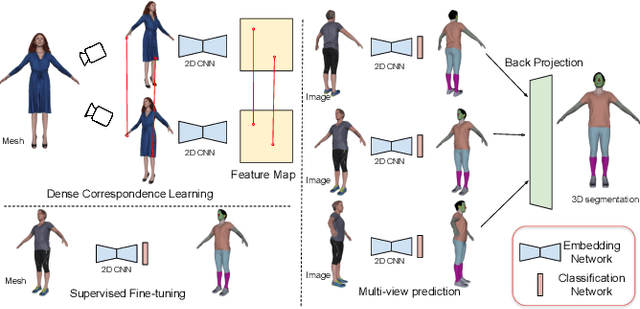
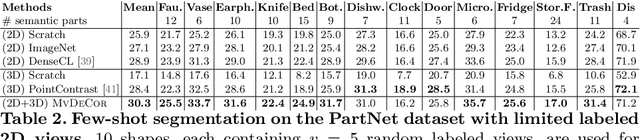
We propose to utilize self-supervised techniques in the 2D domain for fine-grained 3D shape segmentation tasks. This is inspired by the observation that view-based surface representations are more effective at modeling high-resolution surface details and texture than their 3D counterparts based on point clouds or voxel occupancy. Specifically, given a 3D shape, we render it from multiple views, and set up a dense correspondence learning task within the contrastive learning framework. As a result, the learned 2D representations are view-invariant and geometrically consistent, leading to better generalization when trained on a limited number of labeled shapes compared to alternatives that utilize self-supervision in 2D or 3D alone. Experiments on textured (RenderPeople) and untextured (PartNet) 3D datasets show that our method outperforms state-of-the-art alternatives in fine-grained part segmentation. The improvements over baselines are greater when only a sparse set of views is available for training or when shapes are textured, indicating that MvDeCor benefits from both 2D processing and 3D geometric reasoning.
AUV-Net: Learning Aligned UV Maps for Texture Transfer and Synthesis
Apr 06, 2022



In this paper, we address the problem of texture representation for 3D shapes for the challenging and underexplored tasks of texture transfer and synthesis. Previous works either apply spherical texture maps which may lead to large distortions, or use continuous texture fields that yield smooth outputs lacking details. We argue that the traditional way of representing textures with images and linking them to a 3D mesh via UV mapping is more desirable, since synthesizing 2D images is a well-studied problem. We propose AUV-Net which learns to embed 3D surfaces into a 2D aligned UV space, by mapping the corresponding semantic parts of different 3D shapes to the same location in the UV space. As a result, textures are aligned across objects, and can thus be easily synthesized by generative models of images. Texture alignment is learned in an unsupervised manner by a simple yet effective texture alignment module, taking inspiration from traditional works on linear subspace learning. The learned UV mapping and aligned texture representations enable a variety of applications including texture transfer, texture synthesis, and textured single view 3D reconstruction. We conduct experiments on multiple datasets to demonstrate the effectiveness of our method. Project page: https://nv-tlabs.github.io/AUV-NET.
Hierarchical Neural Implicit Pose Network for Animation and Motion Retargeting
Dec 02, 2021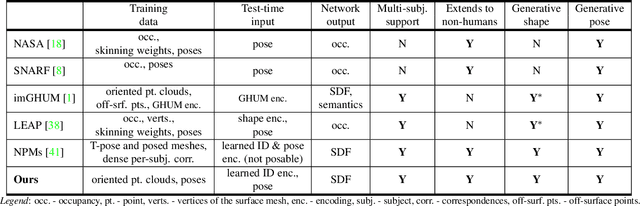
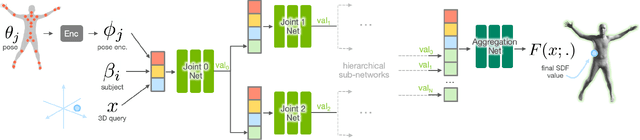
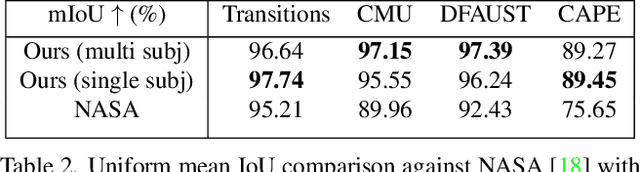
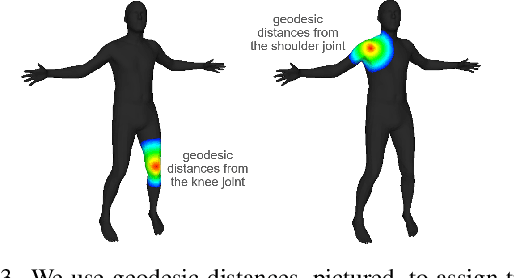
We present HIPNet, a neural implicit pose network trained on multiple subjects across many poses. HIPNet can disentangle subject-specific details from pose-specific details, effectively enabling us to retarget motion from one subject to another or to animate between keyframes through latent space interpolation. To this end, we employ a hierarchical skeleton-based representation to learn a signed distance function on a canonical unposed space. This joint-based decomposition enables us to represent subtle details that are local to the space around the body joint. Unlike previous neural implicit method that requires ground-truth SDF for training, our model we only need a posed skeleton and the point cloud for training, and we have no dependency on a traditional parametric model or traditional skinning approaches. We achieve state-of-the-art results on various single-subject and multi-subject benchmarks.
Deep Marching Tetrahedra: a Hybrid Representation for High-Resolution 3D Shape Synthesis
Nov 08, 2021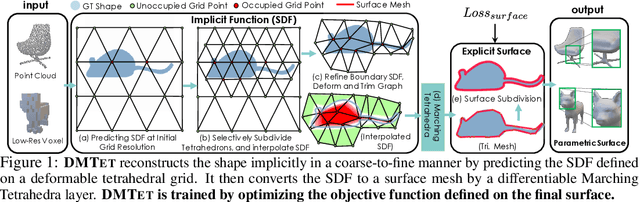

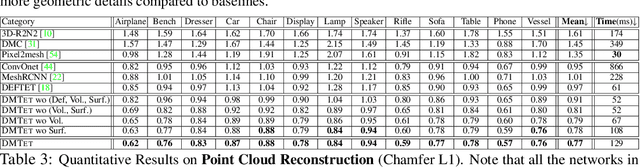
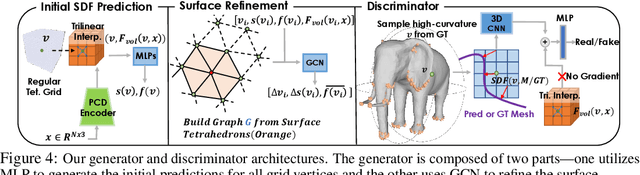
We introduce DMTet, a deep 3D conditional generative model that can synthesize high-resolution 3D shapes using simple user guides such as coarse voxels. It marries the merits of implicit and explicit 3D representations by leveraging a novel hybrid 3D representation. Compared to the current implicit approaches, which are trained to regress the signed distance values, DMTet directly optimizes for the reconstructed surface, which enables us to synthesize finer geometric details with fewer artifacts. Unlike deep 3D generative models that directly generate explicit representations such as meshes, our model can synthesize shapes with arbitrary topology. The core of DMTet includes a deformable tetrahedral grid that encodes a discretized signed distance function and a differentiable marching tetrahedra layer that converts the implicit signed distance representation to the explicit surface mesh representation. This combination allows joint optimization of the surface geometry and topology as well as generation of the hierarchy of subdivisions using reconstruction and adversarial losses defined explicitly on the surface mesh. Our approach significantly outperforms existing work on conditional shape synthesis from coarse voxel inputs, trained on a dataset of complex 3D animal shapes. Project page: https://nv-tlabs.github.io/DMTet/.
3DStyleNet: Creating 3D Shapes with Geometric and Texture Style Variations
Aug 30, 2021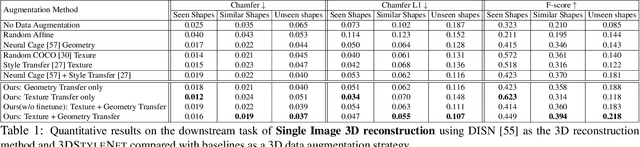
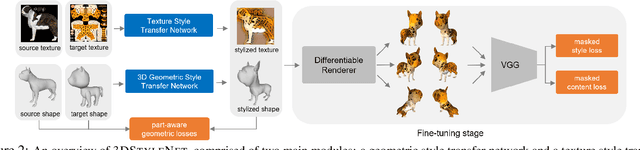
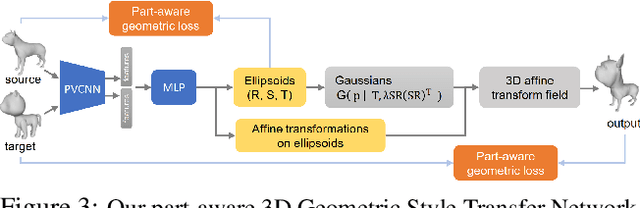
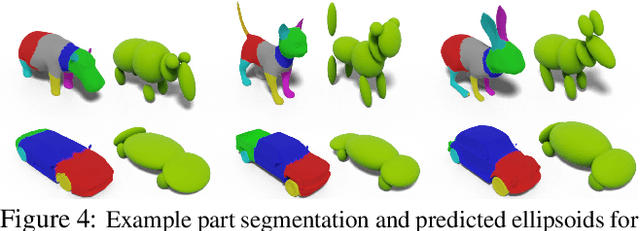
We propose a method to create plausible geometric and texture style variations of 3D objects in the quest to democratize 3D content creation. Given a pair of textured source and target objects, our method predicts a part-aware affine transformation field that naturally warps the source shape to imitate the overall geometric style of the target. In addition, the texture style of the target is transferred to the warped source object with the help of a multi-view differentiable renderer. Our model, 3DStyleNet, is composed of two sub-networks trained in two stages. First, the geometric style network is trained on a large set of untextured 3D shapes. Second, we jointly optimize our geometric style network and a pre-trained image style transfer network with losses defined over both the geometry and the rendering of the result. Given a small set of high-quality textured objects, our method can create many novel stylized shapes, resulting in effortless 3D content creation and style-ware data augmentation. We showcase our approach qualitatively on 3D content stylization, and provide user studies to validate the quality of our results. In addition, our method can serve as a valuable tool to create 3D data augmentations for computer vision tasks. Extensive quantitative analysis shows that 3DStyleNet outperforms alternative data augmentation techniques for the downstream task of single-image 3D reconstruction.
DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort
Apr 20, 2021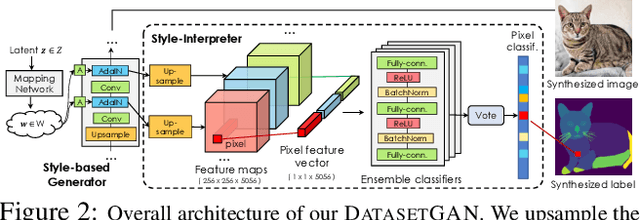
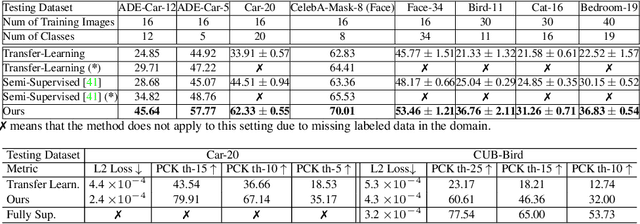
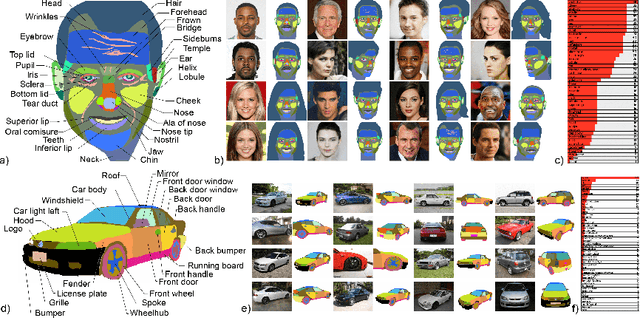
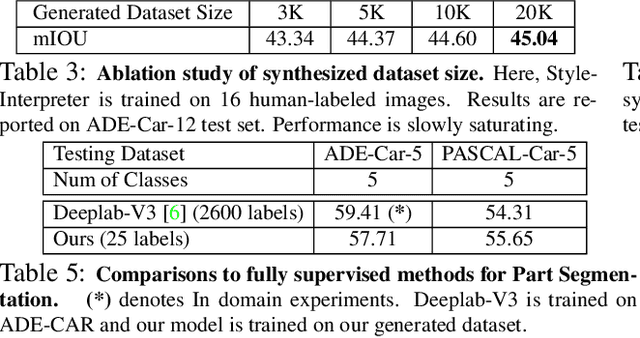
We introduce DatasetGAN: an automatic procedure to generate massive datasets of high-quality semantically segmented images requiring minimal human effort. Current deep networks are extremely data-hungry, benefiting from training on large-scale datasets, which are time consuming to annotate. Our method relies on the power of recent GANs to generate realistic images. We show how the GAN latent code can be decoded to produce a semantic segmentation of the image. Training the decoder only needs a few labeled examples to generalize to the rest of the latent space, resulting in an infinite annotated dataset generator! These generated datasets can then be used for training any computer vision architecture just as real datasets are. As only a few images need to be manually segmented, it becomes possible to annotate images in extreme detail and generate datasets with rich object and part segmentations. To showcase the power of our approach, we generated datasets for 7 image segmentation tasks which include pixel-level labels for 34 human face parts, and 32 car parts. Our approach outperforms all semi-supervised baselines significantly and is on par with fully supervised methods, which in some cases require as much as 100x more annotated data as our method.