 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRON: Tracing Rays to Orchestrate a Neural Renderer for 3D Gaussian Reconstructions
Jun 09, 2026We introduce TRON, a rendering framework that combines 3D Gaussian ray tracing with neural rendering to enable realistic and controllable rendering of real-world 3D scenes under novel lighting, dynamic object motion, object insertion, and material editing. Prior approaches that rely solely on physically based rendering (PBR) of Gaussian representations struggle to achieve realistic relighting due to imperfections in reconstructed geometry, material estimates, and light transport estimation. At the same time, neural rendering methods often lack an explicit scene representation, limiting their ability to support interactive editing with fine-grained manipulation. TRON bridges these two paradigms. We use intrinsic decomposition priors from a learned inverse rendering model to regularize the material properties of a Gaussian field, and repurpose a ray tracer to provide radiometric guidance rather than final pixels. By treating this output as a structured 3D scaffold, we empower a lightweight neural renderer to bridge the domain gap between shading-model constrained estimates and photorealistic output. Our key insight is that the combination of explicit 3D knowledge with robust material priors provides speed and controllability, while neural rendering enables the synthesis of photorealistic images. To support real-world scenarios, we train our neural renderer with a multi-stage strategy consisting of large-scale pretraining and targeted fine-tuning on a newly constructed dataset of 2.1M rendered synthetic and real-world frames from 3D reconstructions. TRON outperforms Gaussian-based relighting methods in realism, and prior neural renderers in editability and speed. To the best of our knowledge, TRON is the first method to enable practical interactive applications in captured 3D environments, offering realistic appearance under dynamic geometric, lighting and material conditions.
AlbedoEdit: Unified Instance-Level Video Editing with Albedo Guidance
May 31, 2026Video generative models have achieved remarkable progress in synthesizing photorealistic video sequences. However, enabling broader and more creative downstream applications requires fine-grained instance-level video editing, including object insertion, object removal, and texture editing, which has emerged as a prominent yet challenging problem. Existing approaches either propose unified generative frameworks with only coarse semantic control, or design task-specific frameworks for individual editing tasks, limiting their flexibility and applicability across diverse real-world scenarios. To address these limitations, we propose AlbedoEdit, a unified generative video editing framework that jointly supports object insertion, object removal, and texture editing. Our key insight is that the intrinsic albedo map, which is invariant to lighting and contains no specularity, shadowing and inter-reflection effects, provides an effective and user-friendly mechanism for specifying fine-grained appearance edits. Built upon video foundation models, AlbedoEdit is fine-tuned to translate source RGB videos into edited RGB videos, conditioned on a user-edited first-frame albedo. Trained on a new paired synthetic dataset covering all three editing tasks, AlbedoEdit implicitly learns to harmonize edited contents and simulate complex real-world visual effects triggered by editing operations, including specular highlights, soft shadows, and mirror reflections. AlbedoEdit demonstrates superior performance over state-of-the-art video editing approaches, both qualitatively and quantitatively. Project webpage is https://vcai.mpi-inf.mpg.de/projects/AlbedoEdit/.
VideoMatGen: PBR Materials through Joint Generative Modeling
Mar 17, 2026We present a method for generating physically-based materials for 3D shapes based on a video diffusion transformer architecture. Our method is conditioned on input geometry and a text description, and jointly models multiple material properties (base color, roughness, metallicity, height map) to form physically plausible materials. We further introduce a custom variational auto-encoder which encodes multiple material modalities into a compact latent space, which enables joint generation of multiple modalities without increasing the number of tokens. Our pipeline generates high-quality materials for 3D shapes given a text prompt, compatible with common content creation tools.
UniRelight: Learning Joint Decomposition and Synthesis for Video Relighting
Jun 18, 2025We address the challenge of relighting a single image or video, a task that demands precise scene intrinsic understanding and high-quality light transport synthesis. Existing end-to-end relighting models are often limited by the scarcity of paired multi-illumination data, restricting their ability to generalize across diverse scenes. Conversely, two-stage pipelines that combine inverse and forward rendering can mitigate data requirements but are susceptible to error accumulation and often fail to produce realistic outputs under complex lighting conditions or with sophisticated materials. In this work, we introduce a general-purpose approach that jointly estimates albedo and synthesizes relit outputs in a single pass, harnessing the generative capabilities of video diffusion models. This joint formulation enhances implicit scene comprehension and facilitates the creation of realistic lighting effects and intricate material interactions, such as shadows, reflections, and transparency. Trained on synthetic multi-illumination data and extensive automatically labeled real-world videos, our model demonstrates strong generalization across diverse domains and surpasses previous methods in both visual fidelity and temporal consistency.
VideoMat: Extracting PBR Materials from Video Diffusion Models
Jun 11, 2025We leverage finetuned video diffusion models, intrinsic decomposition of videos, and physically-based differentiable rendering to generate high quality materials for 3D models given a text prompt or a single image. We condition a video diffusion model to respect the input geometry and lighting condition. This model produces multiple views of a given 3D model with coherent material properties. Secondly, we use a recent model to extract intrinsics (base color, roughness, metallic) from the generated video. Finally, we use the intrinsics alongside the generated video in a differentiable path tracer to robustly extract PBR materials directly compatible with common content creation tools.
Generative Detail Enhancement for Physically Based Materials
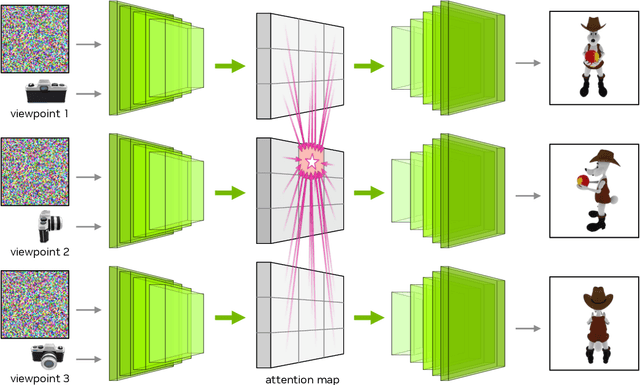
Feb 19, 2025We present a tool for enhancing the detail of physically based materials using an off-the-shelf diffusion model and inverse rendering. Our goal is to enhance the visual fidelity of materials with detail that is often tedious to author, by adding signs of wear, aging, weathering, etc. As these appearance details are often rooted in real-world processes, we leverage a generative image model trained on a large dataset of natural images with corresponding visuals in context. Starting with a given geometry, UV mapping, and basic appearance, we render multiple views of the object. We use these views, together with an appearance-defining text prompt, to condition a diffusion model. The details it generates are then backpropagated from the enhanced images to the material parameters via inverse differentiable rendering. For inverse rendering to be successful, the generated appearance has to be consistent across all the images. We propose two priors to address the multi-view consistency of the diffusion model. First, we ensure that the initial noise that seeds the diffusion process is itself consistent across views by integrating it from a view-independent UV space. Second, we enforce geometric consistency by biasing the attention mechanism via a projective constraint so that pixels attend strongly to their corresponding pixel locations in other views. Our approach does not require any training or finetuning of the diffusion model, is agnostic of the material model used, and the enhanced material properties, i.e., 2D PBR textures, can be further edited by artists.
DiffusionRenderer: Neural Inverse and Forward Rendering with Video Diffusion Models
Jan 30, 2025



Understanding and modeling lighting effects are fundamental tasks in computer vision and graphics. Classic physically-based rendering (PBR) accurately simulates the light transport, but relies on precise scene representations--explicit 3D geometry, high-quality material properties, and lighting conditions--that are often impractical to obtain in real-world scenarios. Therefore, we introduce DiffusionRenderer, a neural approach that addresses the dual problem of inverse and forward rendering within a holistic framework. Leveraging powerful video diffusion model priors, the inverse rendering model accurately estimates G-buffers from real-world videos, providing an interface for image editing tasks, and training data for the rendering model. Conversely, our rendering model generates photorealistic images from G-buffers without explicit light transport simulation. Experiments demonstrate that DiffusionRenderer effectively approximates inverse and forwards rendering, consistently outperforming the state-of-the-art. Our model enables practical applications from a single video input--including relighting, material editing, and realistic object insertion.
Edify 3D: Scalable High-Quality 3D Asset Generation
Nov 11, 2024
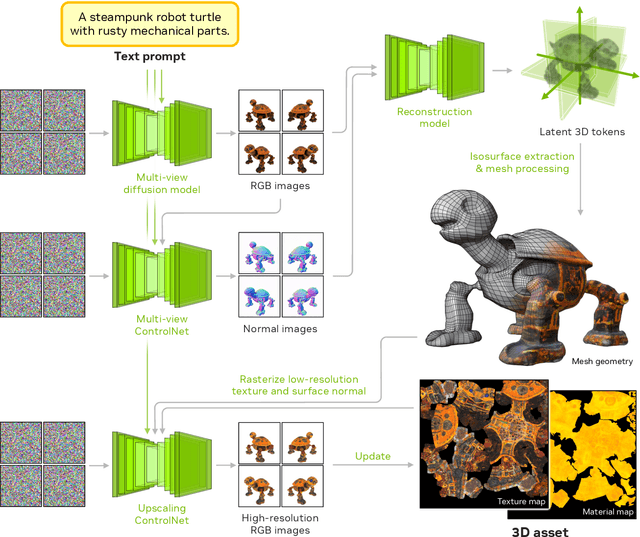

We introduce Edify 3D, an advanced solution designed for high-quality 3D asset generation. Our method first synthesizes RGB and surface normal images of the described object at multiple viewpoints using a diffusion model. The multi-view observations are then used to reconstruct the shape, texture, and PBR materials of the object. Our method can generate high-quality 3D assets with detailed geometry, clean shape topologies, high-resolution textures, and materials within 2 minutes of runtime.
Flexible Isosurface Extraction for Gradient-Based Mesh Optimization
Aug 10, 2023



This work considers gradient-based mesh optimization, where we iteratively optimize for a 3D surface mesh by representing it as the isosurface of a scalar field, an increasingly common paradigm in applications including photogrammetry, generative modeling, and inverse physics. Existing implementations adapt classic isosurface extraction algorithms like Marching Cubes or Dual Contouring; these techniques were designed to extract meshes from fixed, known fields, and in the optimization setting they lack the degrees of freedom to represent high-quality feature-preserving meshes, or suffer from numerical instabilities. We introduce FlexiCubes, an isosurface representation specifically designed for optimizing an unknown mesh with respect to geometric, visual, or even physical objectives. Our main insight is to introduce additional carefully-chosen parameters into the representation, which allow local flexible adjustments to the extracted mesh geometry and connectivity. These parameters are updated along with the underlying scalar field via automatic differentiation when optimizing for a downstream task. We base our extraction scheme on Dual Marching Cubes for improved topological properties, and present extensions to optionally generate tetrahedral and hierarchically-adaptive meshes. Extensive experiments validate FlexiCubes on both synthetic benchmarks and real-world applications, showing that it offers significant improvements in mesh quality and geometric fidelity.
* SIGGRAPH 2023. Project page: https://research.nvidia.com/labs/toronto-ai/flexicubes/
Neural Fields meet Explicit Geometric Representation for Inverse Rendering of Urban Scenes
Apr 06, 2023



Reconstruction and intrinsic decomposition of scenes from captured imagery would enable many applications such as relighting and virtual object insertion. Recent NeRF based methods achieve impressive fidelity of 3D reconstruction, but bake the lighting and shadows into the radiance field, while mesh-based methods that facilitate intrinsic decomposition through differentiable rendering have not yet scaled to the complexity and scale of outdoor scenes. We present a novel inverse rendering framework for large urban scenes capable of jointly reconstructing the scene geometry, spatially-varying materials, and HDR lighting from a set of posed RGB images with optional depth. Specifically, we use a neural field to account for the primary rays, and use an explicit mesh (reconstructed from the underlying neural field) for modeling secondary rays that produce higher-order lighting effects such as cast shadows. By faithfully disentangling complex geometry and materials from lighting effects, our method enables photorealistic relighting with specular and shadow effects on several outdoor datasets. Moreover, it supports physics-based scene manipulations such as virtual object insertion with ray-traced shadow casting.