 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Stochastic Texture Filtering Through Sample Reuse
Apr 07, 2025Stochastic texture filtering (STF) has re-emerged as a technique that can bring down the cost of texture filtering of advanced texture compression methods, e.g., neural texture compression. However, during texture magnification, the swapped order of filtering and shading with STF can result in aliasing. The inability to smoothly interpolate material properties stored in textures, such as surface normals, leads to potentially undesirable appearance changes. We present a novel method to improve the quality of stochastically-filtered magnified textures and reduce the image difference compared to traditional texture filtering. When textures are magnified, nearby pixels filter similar sets of texels and we introduce techniques for sharing texel values among pixels with only a small increase in cost (0.04--0.14~ms per frame). We propose an improvement to weighted importance sampling that guarantees that our method never increases error beyond single-sample stochastic texture filtering. Under high magnification, our method has >10 dB higher PSNR than single-sample STF. Our results show greatly improved image quality both with and without spatiotemporal denoising.
* Accepted to 2025 ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games (I3D 2025)
GPU-Friendly Laplacian Texture Blending
Feb 19, 2025Texture and material blending is one of the leading methods for adding variety to rendered virtual worlds, creating composite materials, and generating procedural content. When done naively, it can introduce either visible seams or contrast loss, leading to an unnatural look not representative of blended textures. Earlier work proposed addressing this problem through careful manual parameter tuning, lengthy per-texture statistics precomputation, look-up tables, or training deep neural networks. In this work, we propose an alternative approach based on insights from image processing and Laplacian pyramid blending. Our approach does not require any precomputation or increased memory usage (other than the presence of a regular, non-Laplacian, texture mipmap chain), does not produce ghosting, preserves sharp local features, and can run in real time on the GPU at the cost of a few additional lower mipmap texture taps.
* 19 pages, 13 figures, Journal of Computer Graphics Techniques (JCGT)
Generative Detail Enhancement for Physically Based Materials
Feb 19, 2025We present a tool for enhancing the detail of physically based materials using an off-the-shelf diffusion model and inverse rendering. Our goal is to enhance the visual fidelity of materials with detail that is often tedious to author, by adding signs of wear, aging, weathering, etc. As these appearance details are often rooted in real-world processes, we leverage a generative image model trained on a large dataset of natural images with corresponding visuals in context. Starting with a given geometry, UV mapping, and basic appearance, we render multiple views of the object. We use these views, together with an appearance-defining text prompt, to condition a diffusion model. The details it generates are then backpropagated from the enhanced images to the material parameters via inverse differentiable rendering. For inverse rendering to be successful, the generated appearance has to be consistent across all the images. We propose two priors to address the multi-view consistency of the diffusion model. First, we ensure that the initial noise that seeds the diffusion process is itself consistent across views by integrating it from a view-independent UV space. Second, we enforce geometric consistency by biasing the attention mechanism via a projective constraint so that pixels attend strongly to their corresponding pixel locations in other views. Our approach does not require any training or finetuning of the diffusion model, is agnostic of the material model used, and the enhanced material properties, i.e., 2D PBR textures, can be further edited by artists.
Random-Access Neural Compression of Material Textures
May 26, 2023



The continuous advancement of photorealism in rendering is accompanied by a growth in texture data and, consequently, increasing storage and memory demands. To address this issue, we propose a novel neural compression technique specifically designed for material textures. We unlock two more levels of detail, i.e., 16x more texels, using low bitrate compression, with image quality that is better than advanced image compression techniques, such as AVIF and JPEG XL. At the same time, our method allows on-demand, real-time decompression with random access similar to block texture compression on GPUs, enabling compression on disk and memory. The key idea behind our approach is compressing multiple material textures and their mipmap chains together, and using a small neural network, that is optimized for each material, to decompress them. Finally, we use a custom training implementation to achieve practical compression speeds, whose performance surpasses that of general frameworks, like PyTorch, by an order of magnitude.
Stochastic Texture Filtering
May 15, 20232D texture maps and 3D voxel arrays are widely used to add rich detail to the surfaces and volumes of rendered scenes, and filtered texture lookups are integral to producing high-quality imagery. We show that filtering textures after evaluating lighting, rather than before BSDF evaluation as is current practice, gives a more accurate solution to the rendering equation. These benefits are not merely theoretical, but are apparent in common cases. We further show that stochastically sampling texture filters is crucial for enabling this approach, which has not been possible previously except in limited cases. Stochastic texture filtering offers additional benefits, including efficient implementation of high-quality texture filters and efficient filtering of textures stored in compressed and sparse data structures, including neural representations. We demonstrate applications in both real-time and offline rendering and show that the additional stochastic error is minimal. Furthermore, this error is handled well by either spatiotemporal denoising or moderate pixel sampling rates.
Procedural Kernel Networks
Dec 17, 2021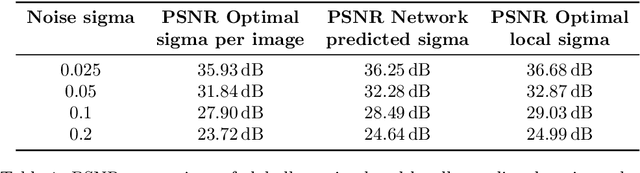

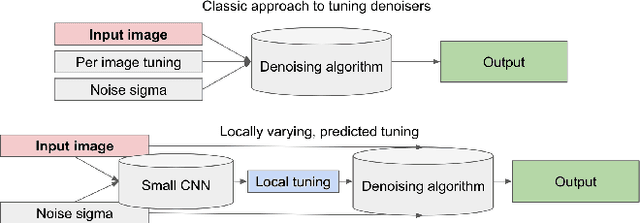

In the last decade Convolutional Neural Networks (CNNs) have defined the state of the art for many low level image processing and restoration tasks such as denoising, demosaicking, upscaling, or inpainting. However, on-device mobile photography is still dominated by traditional image processing techniques, and uses mostly simple machine learning techniques or limits the neural network processing to producing low resolution masks. High computational and memory requirements of CNNs, limited processing power and thermal constraints of mobile devices, combined with large output image resolutions (typically 8--12 MPix) prevent their wider application. In this work, we introduce Procedural Kernel Networks (PKNs), a family of machine learning models which generate parameters of image filter kernels or other traditional algorithms. A lightweight CNN processes the input image at a lower resolution, which yields a significant speedup compared to other kernel-based machine learning methods and allows for new applications. The architecture is learned end-to-end and is especially well suited for a wide range of low-level image processing tasks, where it improves the performance of many traditional algorithms. We also describe how this framework unifies some previous work applying machine learning for common image restoration tasks.
Image Stylization: From Predefined to Personalized
Feb 22, 2020
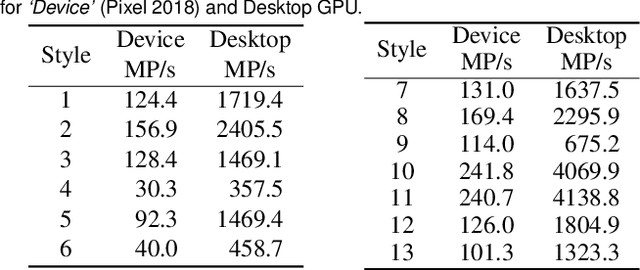
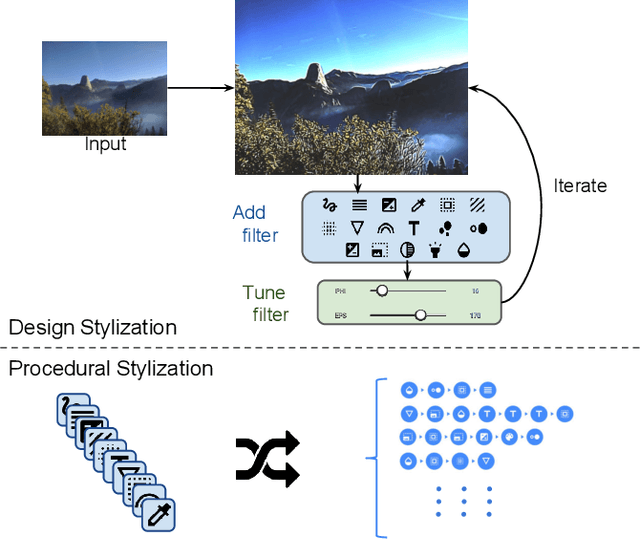
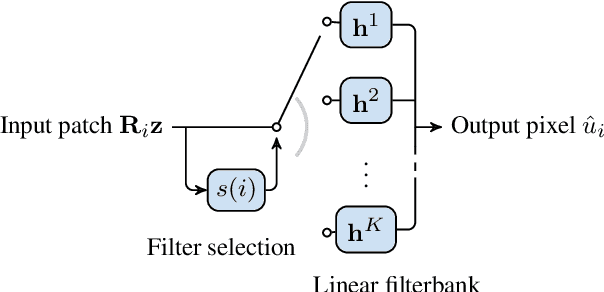
We present a framework for interactive design of new image stylizations using a wide range of predefined filter blocks. Both novel and off-the-shelf image filtering and rendering techniques are extended and combined to allow the user to unleash their creativity to intuitively invent, modify, and tune new styles from a given set of filters. In parallel to this manual design, we propose a novel procedural approach that automatically assembles sequences of filters, leading to unique and novel styles. An important aim of our framework is to allow for interactive exploration and design, as well as to enable videos and camera streams to be stylized on the fly. In order to achieve this real-time performance, we use the \textit{Best Linear Adaptive Enhancement} (BLADE) framework -- an interpretable shallow machine learning method that simulates complex filter blocks in real time. Our representative results include over a dozen styles designed using our interactive tool, a set of styles created procedurally, and new filters trained with our BLADE approach.
Handheld Multi-Frame Super-Resolution
May 08, 2019
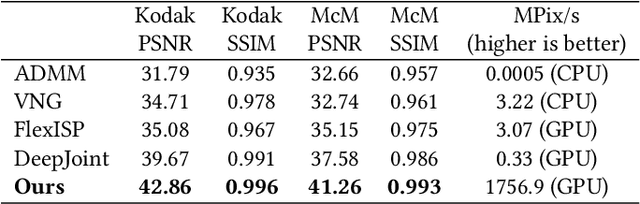
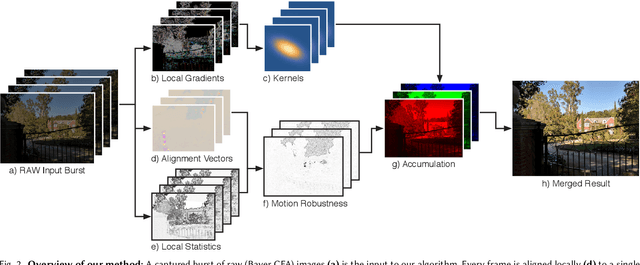
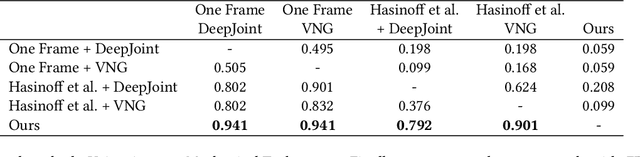
Compared to DSLR cameras, smartphone cameras have smaller sensors, which limits their spatial resolution; smaller apertures, which limits their light gathering ability; and smaller pixels, which reduces their signal-to noise ratio. The use of color filter arrays (CFAs) requires demosaicing, which further degrades resolution. In this paper, we supplant the use of traditional demosaicing in single-frame and burst photography pipelines with a multiframe super-resolution algorithm that creates a complete RGB image directly from a burst of CFA raw images. We harness natural hand tremor, typical in handheld photography, to acquire a burst of raw frames with small offsets. These frames are then aligned and merged to form a single image with red, green, and blue values at every pixel site. This approach, which includes no explicit demosaicing step, serves to both increase image resolution and boost signal to noise ratio. Our algorithm is robust to challenging scene conditions: local motion, occlusion, or scene changes. It runs at 100 milliseconds per 12-megapixel RAW input burst frame on mass-produced mobile phones. Specifically, the algorithm is the basis of the Super-Res Zoom feature, as well as the default merge method in Night Sight mode (whether zooming or not) on Google's flagship phone.