 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Hybrid Zoom using Camera Fusion on Mobile Phones
Jan 02, 2024DSLR cameras can achieve multiple zoom levels via shifting lens distances or swapping lens types. However, these techniques are not possible on smartphone devices due to space constraints. Most smartphone manufacturers adopt a hybrid zoom system: commonly a Wide (W) camera at a low zoom level and a Telephoto (T) camera at a high zoom level. To simulate zoom levels between W and T, these systems crop and digitally upsample images from W, leading to significant detail loss. In this paper, we propose an efficient system for hybrid zoom super-resolution on mobile devices, which captures a synchronous pair of W and T shots and leverages machine learning models to align and transfer details from T to W. We further develop an adaptive blending method that accounts for depth-of-field mismatches, scene occlusion, flow uncertainty, and alignment errors. To minimize the domain gap, we design a dual-phone camera rig to capture real-world inputs and ground-truths for supervised training. Our method generates a 12-megapixel image in 500ms on a mobile platform and compares favorably against state-of-the-art methods under extensive evaluation on real-world scenarios.
Face Deblurring using Dual Camera Fusion on Mobile Phones
Jul 23, 2022
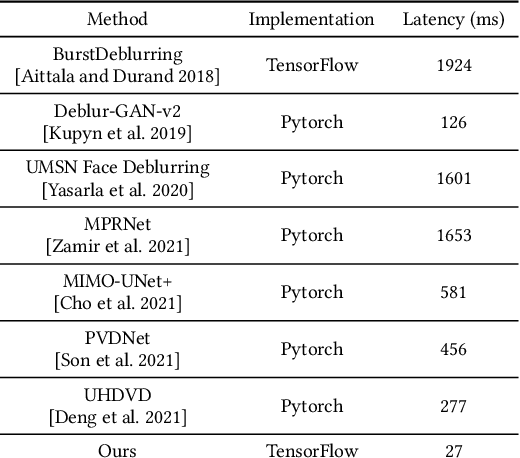

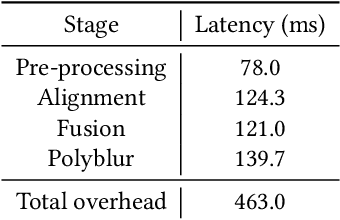
Motion blur of fast-moving subjects is a longstanding problem in photography and very common on mobile phones due to limited light collection efficiency, particularly in low-light conditions. While we have witnessed great progress in image deblurring in recent years, most methods require significant computational power and have limitations in processing high-resolution photos with severe local motions. To this end, we develop a novel face deblurring system based on the dual camera fusion technique for mobile phones. The system detects subject motion to dynamically enable a reference camera, e.g., ultrawide angle camera commonly available on recent premium phones, and captures an auxiliary photo with faster shutter settings. While the main shot is low noise but blurry, the reference shot is sharp but noisy. We learn ML models to align and fuse these two shots and output a clear photo without motion blur. Our algorithm runs efficiently on Google Pixel 6, which takes 463 ms overhead per shot. Our experiments demonstrate the advantage and robustness of our system against alternative single-image, multi-frame, face-specific, and video deblurring algorithms as well as commercial products. To the best of our knowledge, our work is the first mobile solution for face motion deblurring that works reliably and robustly over thousands of images in diverse motion and lighting conditions.
Correcting Face Distortion in Wide-Angle Videos
Nov 18, 2021
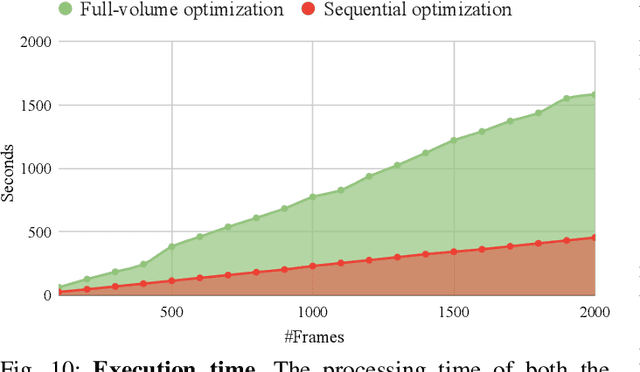


Video blogs and selfies are popular social media formats, which are often captured by wide-angle cameras to show human subjects and expanded background. Unfortunately, due to perspective projection, faces near corners and edges exhibit apparent distortions that stretch and squish the facial features, resulting in poor video quality. In this work, we present a video warping algorithm to correct these distortions. Our key idea is to apply stereographic projection locally on the facial regions. We formulate a mesh warp problem using spatial-temporal energy minimization and minimize background deformation using a line-preservation term to maintain the straight edges in the background. To address temporal coherency, we constrain the temporal smoothness on the warping meshes and facial trajectories through the latent variables. For performance evaluation, we develop a wide-angle video dataset with a wide range of focal lengths. The user study shows that 83.9% of users prefer our algorithm over other alternatives based on perspective projection.
Deep Online Fused Video Stabilization
Feb 02, 2021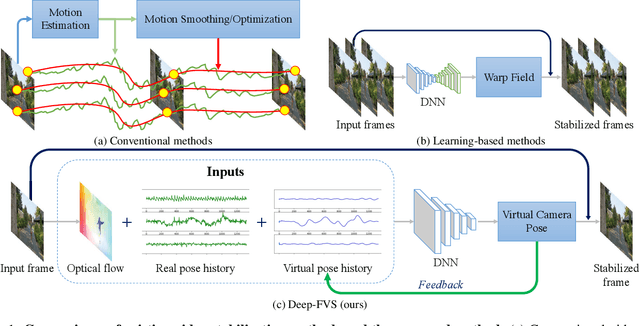

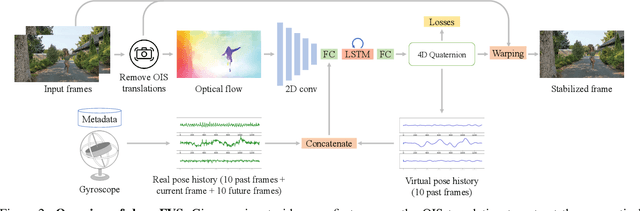
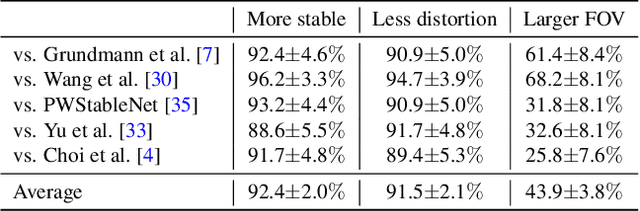
We present a deep neural network (DNN) that uses both sensor data (gyroscope) and image content (optical flow) to stabilize videos through unsupervised learning. The network fuses optical flow with real/virtual camera pose histories into a joint motion representation. Next, the LSTM block infers the new virtual camera pose, and this virtual pose is used to generate a warping grid that stabilizes the frame. Novel relative motion representation as well as a multi-stage training process are presented to optimize our model without any supervision. To the best of our knowledge, this is the first DNN solution that adopts both sensor data and image for stabilization. We validate the proposed framework through ablation studies and demonstrated the proposed method outperforms the state-of-art alternative solutions via quantitative evaluations and a user study.
Portrait Neural Radiance Fields from a Single Image
Dec 10, 2020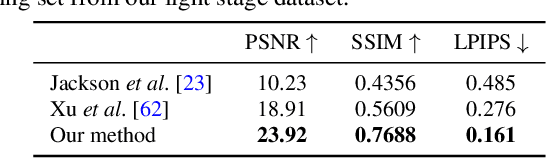
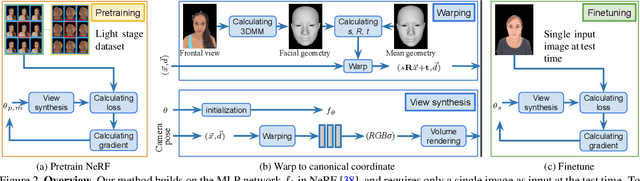
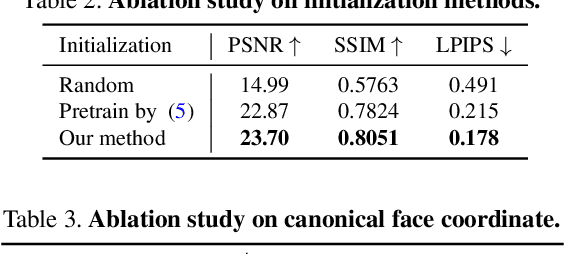
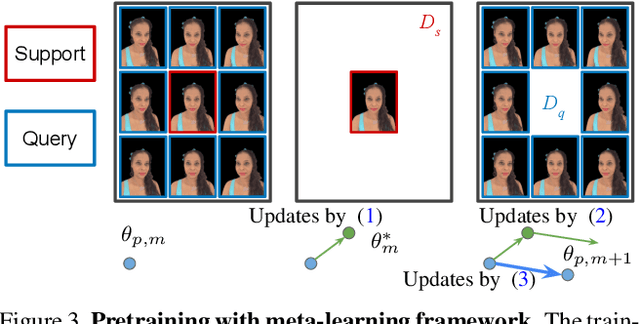
We present a method for estimating Neural Radiance Fields (NeRF) from a single headshot portrait. While NeRF has demonstrated high-quality view synthesis, it requires multiple images of static scenes and thus impractical for casual captures and moving subjects. In this work, we propose to pretrain the weights of a multilayer perceptron (MLP), which implicitly models the volumetric density and colors, with a meta-learning framework using a light stage portrait dataset. To improve the generalization to unseen faces, we train the MLP in the canonical coordinate space approximated by 3D face morphable models. We quantitatively evaluate the method using controlled captures and demonstrate the generalization to real portrait images, showing favorable results against state-of-the-arts.
Handheld Multi-Frame Super-Resolution
May 08, 2019
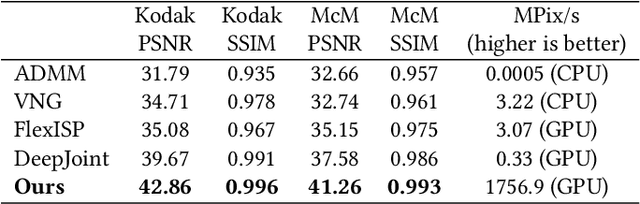
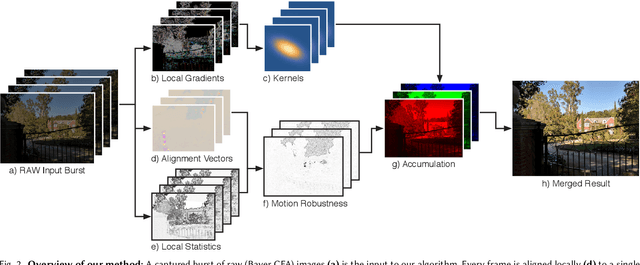
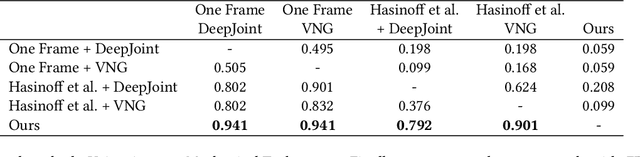
Compared to DSLR cameras, smartphone cameras have smaller sensors, which limits their spatial resolution; smaller apertures, which limits their light gathering ability; and smaller pixels, which reduces their signal-to noise ratio. The use of color filter arrays (CFAs) requires demosaicing, which further degrades resolution. In this paper, we supplant the use of traditional demosaicing in single-frame and burst photography pipelines with a multiframe super-resolution algorithm that creates a complete RGB image directly from a burst of CFA raw images. We harness natural hand tremor, typical in handheld photography, to acquire a burst of raw frames with small offsets. These frames are then aligned and merged to form a single image with red, green, and blue values at every pixel site. This approach, which includes no explicit demosaicing step, serves to both increase image resolution and boost signal to noise ratio. Our algorithm is robust to challenging scene conditions: local motion, occlusion, or scene changes. It runs at 100 milliseconds per 12-megapixel RAW input burst frame on mass-produced mobile phones. Specifically, the algorithm is the basis of the Super-Res Zoom feature, as well as the default merge method in Night Sight mode (whether zooming or not) on Google's flagship phone.
Steadiface: Real-Time Face-Centric Stabilization on Mobile Phones
May 03, 2019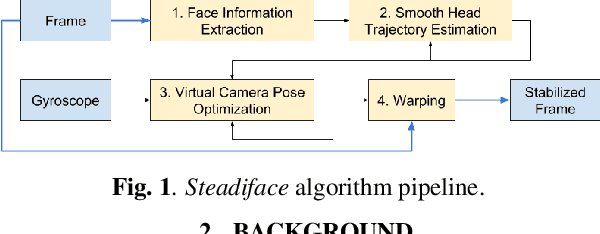

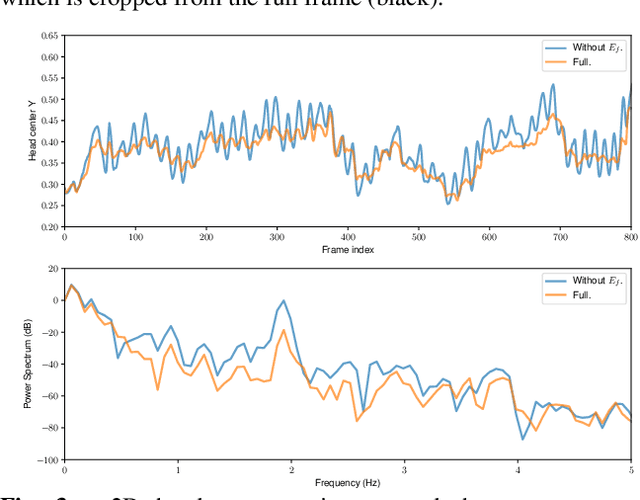
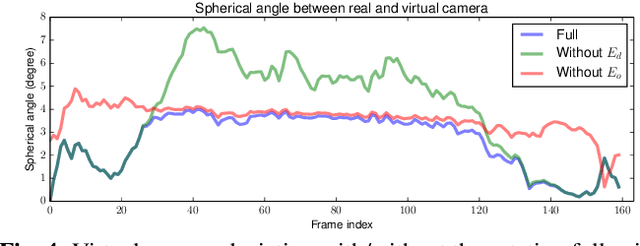
We present Steadiface, a new real-time face-centric video stabilization method that simultaneously removes hand shake and keeps subject's head stable. We use a CNN to estimate the face landmarks and use them to optimize a stabilized head center. We then formulate an optimization problem to find a virtual camera pose that locates the face to the stabilized head center while retains smooth rotation and translation transitions across frames. We test the proposed method on fieldtest videos and show it stabilizes both the head motion and background. It is robust to large head pose, occlusion, facial appearance variations, and different kinds of camera motions. We show our method advances the state of art in selfie video stabilization by comparing against alternative methods. The whole process runs very efficiently on a modern mobile phone (8.1 ms/frame).