 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionRenderer: Neural Inverse and Forward Rendering with Video Diffusion Models
Jan 30, 2025



Understanding and modeling lighting effects are fundamental tasks in computer vision and graphics. Classic physically-based rendering (PBR) accurately simulates the light transport, but relies on precise scene representations--explicit 3D geometry, high-quality material properties, and lighting conditions--that are often impractical to obtain in real-world scenarios. Therefore, we introduce DiffusionRenderer, a neural approach that addresses the dual problem of inverse and forward rendering within a holistic framework. Leveraging powerful video diffusion model priors, the inverse rendering model accurately estimates G-buffers from real-world videos, providing an interface for image editing tasks, and training data for the rendering model. Conversely, our rendering model generates photorealistic images from G-buffers without explicit light transport simulation. Experiments demonstrate that DiffusionRenderer effectively approximates inverse and forwards rendering, consistently outperforming the state-of-the-art. Our model enables practical applications from a single video input--including relighting, material editing, and realistic object insertion.
AutoVFX: Physically Realistic Video Editing from Natural Language Instructions
Nov 04, 2024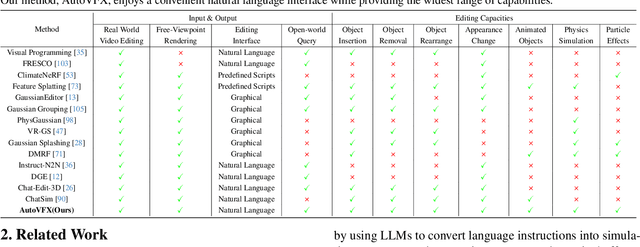
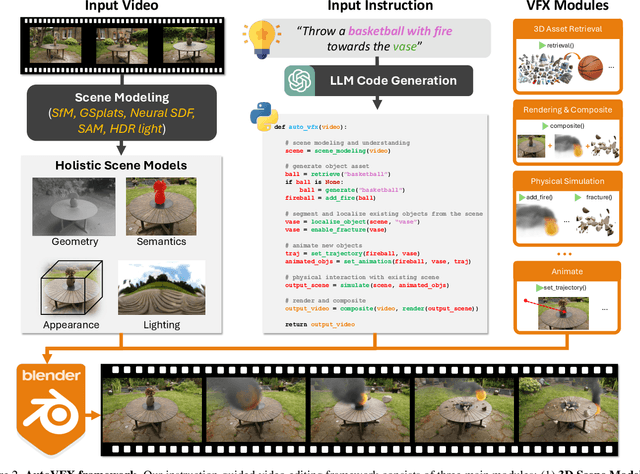


Modern visual effects (VFX) software has made it possible for skilled artists to create imagery of virtually anything. However, the creation process remains laborious, complex, and largely inaccessible to everyday users. In this work, we present AutoVFX, a framework that automatically creates realistic and dynamic VFX videos from a single video and natural language instructions. By carefully integrating neural scene modeling, LLM-based code generation, and physical simulation, AutoVFX is able to provide physically-grounded, photorealistic editing effects that can be controlled directly using natural language instructions. We conduct extensive experiments to validate AutoVFX's efficacy across a diverse spectrum of videos and instructions. Quantitative and qualitative results suggest that AutoVFX outperforms all competing methods by a large margin in generative quality, instruction alignment, editing versatility, and physical plausibility.
Video2Game: Real-time, Interactive, Realistic and Browser-Compatible Environment from a Single Video
Apr 15, 2024Creating high-quality and interactive virtual environments, such as games and simulators, often involves complex and costly manual modeling processes. In this paper, we present Video2Game, a novel approach that automatically converts videos of real-world scenes into realistic and interactive game environments. At the heart of our system are three core components:(i) a neural radiance fields (NeRF) module that effectively captures the geometry and visual appearance of the scene; (ii) a mesh module that distills the knowledge from NeRF for faster rendering; and (iii) a physics module that models the interactions and physical dynamics among the objects. By following the carefully designed pipeline, one can construct an interactable and actionable digital replica of the real world. We benchmark our system on both indoor and large-scale outdoor scenes. We show that we can not only produce highly-realistic renderings in real-time, but also build interactive games on top.
IRIS: Inverse Rendering of Indoor Scenes from Low Dynamic Range Images
Jan 23, 2024While numerous 3D reconstruction and novel-view synthesis methods allow for photorealistic rendering of a scene from multi-view images easily captured with consumer cameras, they bake illumination in their representations and fall short of supporting advanced applications like material editing, relighting, and virtual object insertion. The reconstruction of physically based material properties and lighting via inverse rendering promises to enable such applications. However, most inverse rendering techniques require high dynamic range (HDR) images as input, a setting that is inaccessible to most users. We present a method that recovers the physically based material properties and spatially-varying HDR lighting of a scene from multi-view, low-dynamic-range (LDR) images. We model the LDR image formation process in our inverse rendering pipeline and propose a novel optimization strategy for material, lighting, and a camera response model. We evaluate our approach with synthetic and real scenes compared to the state-of-the-art inverse rendering methods that take either LDR or HDR input. Our method outperforms existing methods taking LDR images as input, and allows for highly realistic relighting and object insertion.
UrbanIR: Large-Scale Urban Scene Inverse Rendering from a Single Video
Jun 16, 2023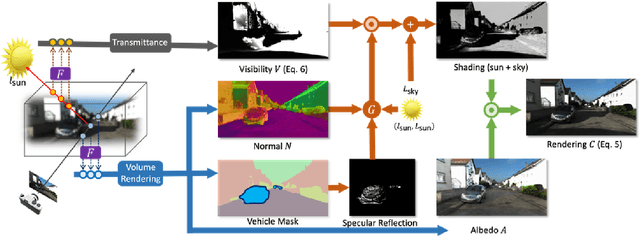
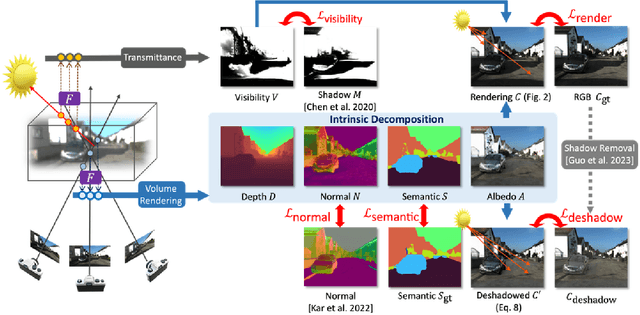


We show how to build a model that allows realistic, free-viewpoint renderings of a scene under novel lighting conditions from video. Our method -- UrbanIR: Urban Scene Inverse Rendering -- computes an inverse graphics representation from the video. UrbanIR jointly infers shape, albedo, visibility, and sun and sky illumination from a single video of unbounded outdoor scenes with unknown lighting. UrbanIR uses videos from cameras mounted on cars (in contrast to many views of the same points in typical NeRF-style estimation). As a result, standard methods produce poor geometry estimates (for example, roofs), and there are numerous ''floaters''. Errors in inverse graphics inference can result in strong rendering artifacts. UrbanIR uses novel losses to control these and other sources of error. UrbanIR uses a novel loss to make very good estimates of shadow volumes in the original scene. The resulting representations facilitate controllable editing, delivering photorealistic free-viewpoint renderings of relit scenes and inserted objects. Qualitative evaluation demonstrates strong improvements over the state-of-the-art.
ClimateNeRF: Physically-based Neural Rendering for Extreme Climate Synthesis
Nov 26, 2022



Physical simulations produce excellent predictions of weather effects. Neural radiance fields produce SOTA scene models. We describe a novel NeRF-editing procedure that can fuse physical simulations with NeRF models of scenes, producing realistic movies of physical phenomena inthose scenes. Our application -- Climate NeRF -- allows people to visualize what climate change outcomes will do to them. ClimateNeRF allows us to render realistic weather effects, including smog, snow, and flood. Results can be controlled with physically meaningful variables like water level. Qualitative and quantitative studies show that our simulated results are significantly more realistic than those from state-of-the-art 2D image editing and 3D NeRF stylization.
NeurMiPs: Neural Mixture of Planar Experts for View Synthesis
Apr 28, 2022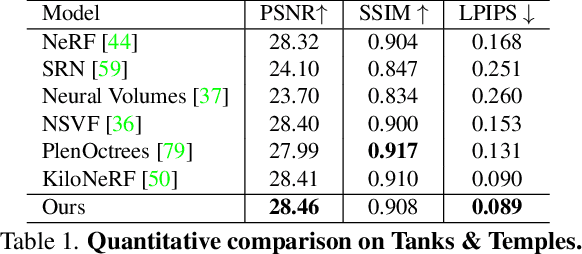
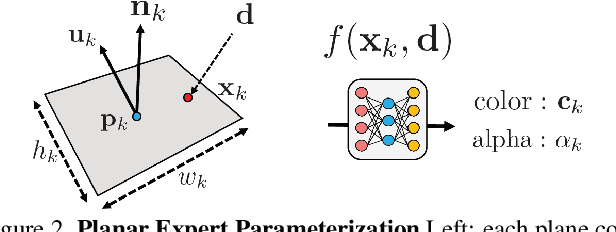
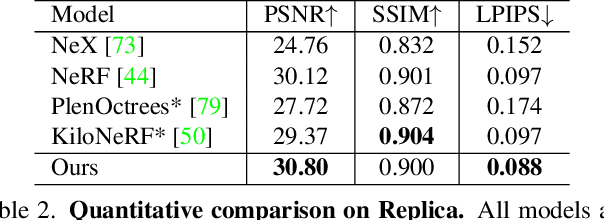
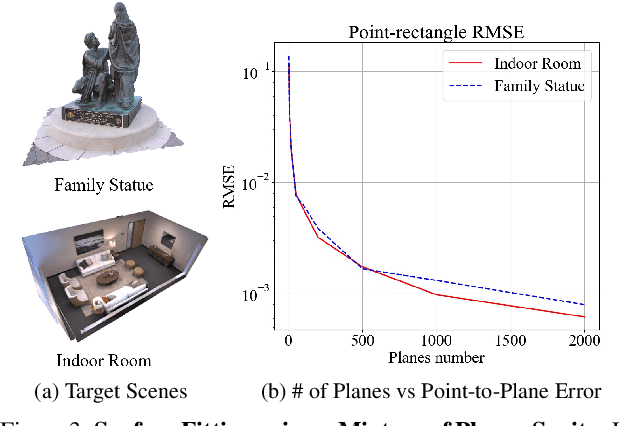
We present Neural Mixtures of Planar Experts (NeurMiPs), a novel planar-based scene representation for modeling geometry and appearance. NeurMiPs leverages a collection of local planar experts in 3D space as the scene representation. Each planar expert consists of the parameters of the local rectangular shape representing geometry and a neural radiance field modeling the color and opacity. We render novel views by calculating ray-plane intersections and composite output colors and densities at intersected points to the image. NeurMiPs blends the efficiency of explicit mesh rendering and flexibility of the neural radiance field. Experiments demonstrate superior performance and speed of our proposed method, compared to other 3D representations in novel view synthesis.