 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoVFX: Physically Realistic Video Editing from Natural Language Instructions
Nov 04, 2024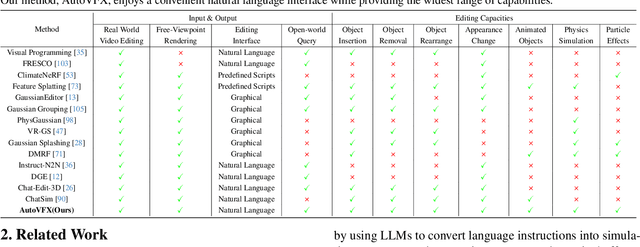
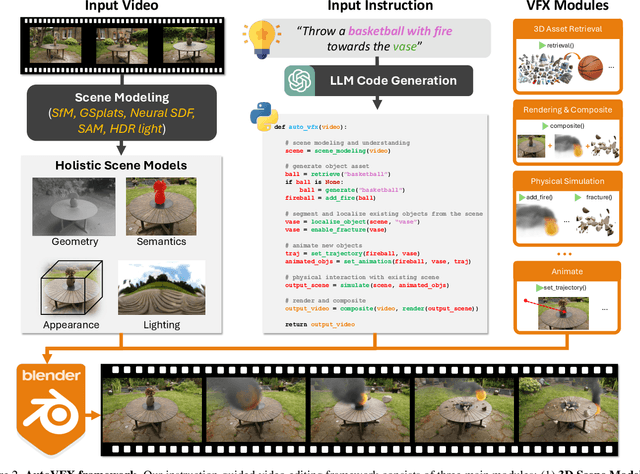


Modern visual effects (VFX) software has made it possible for skilled artists to create imagery of virtually anything. However, the creation process remains laborious, complex, and largely inaccessible to everyday users. In this work, we present AutoVFX, a framework that automatically creates realistic and dynamic VFX videos from a single video and natural language instructions. By carefully integrating neural scene modeling, LLM-based code generation, and physical simulation, AutoVFX is able to provide physically-grounded, photorealistic editing effects that can be controlled directly using natural language instructions. We conduct extensive experiments to validate AutoVFX's efficacy across a diverse spectrum of videos and instructions. Quantitative and qualitative results suggest that AutoVFX outperforms all competing methods by a large margin in generative quality, instruction alignment, editing versatility, and physical plausibility.
EarthGen: Generating the World from Top-Down Views
Sep 02, 2024

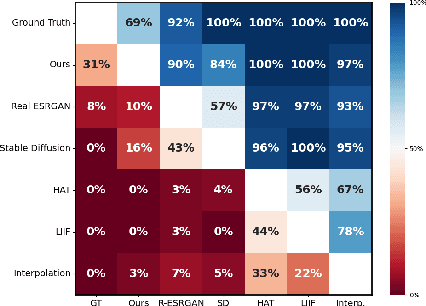

In this work, we present a novel method for extensive multi-scale generative terrain modeling. At the core of our model is a cascade of superresolution diffusion models that can be combined to produce consistent images across multiple resolutions. Pairing this concept with a tiled generation method yields a scalable system that can generate thousands of square kilometers of realistic Earth surfaces at high resolution. We evaluate our method on a dataset collected from Bing Maps and show that it outperforms super-resolution baselines on the extreme super-resolution task of 1024x zoom. We also demonstrate its ability to create diverse and coherent scenes via an interactive gigapixel-scale generated map. Finally, we demonstrate how our system can be extended to enable novel content creation applications including controllable world generation and 3D scene generation.
On the Overconfidence Problem in Semantic 3D Mapping
Nov 16, 2023Semantic 3D mapping, the process of fusing depth and image segmentation information between multiple views to build 3D maps annotated with object classes in real-time, is a recent topic of interest. This paper highlights the fusion overconfidence problem, in which conventional mapping methods assign high confidence to the entire map even when they are incorrect, leading to miscalibrated outputs. Several methods to improve uncertainty calibration at different stages in the fusion pipeline are presented and compared on the ScanNet dataset. We show that the most widely used Bayesian fusion strategy is among the worst calibrated, and propose a learned pipeline that combines fusion and calibration, GLFS, which achieves simultaneously higher accuracy and 3D map calibration while retaining real-time capability. We further illustrate the importance of map calibration on a downstream task by showing that incorporating proper semantic fusion on a modular ObjectNav agent improves its success rates. Our code will be provided on Github for reproducibility upon acceptance.
Sim-on-Wheels: Physical World in the Loop Simulation for Self-Driving
Jun 15, 2023We present Sim-on-Wheels, a safe, realistic, and vehicle-in-loop framework to test autonomous vehicles' performance in the real world under safety-critical scenarios. Sim-on-wheels runs on a self-driving vehicle operating in the physical world. It creates virtual traffic participants with risky behaviors and seamlessly inserts the virtual events into images perceived from the physical world in real-time. The manipulated images are fed into autonomy, allowing the self-driving vehicle to react to such virtual events. The full pipeline runs on the actual vehicle and interacts with the physical world, but the safety-critical events it sees are virtual. Sim-on-Wheels is safe, interactive, realistic, and easy to use. The experiments demonstrate the potential of Sim-on-Wheels to facilitate the process of testing autonomous driving in challenging real-world scenes with high fidelity and low risk.