 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGA: Source Attribution of Generative AI Videos
Nov 16, 2025The proliferation of generative AI has led to hyper-realistic synthetic videos, escalating misuse risks and outstripping binary real/fake detectors. We introduce SAGA (Source Attribution of Generative AI videos), the first comprehensive framework to address the urgent need for AI-generated video source attribution at a large scale. Unlike traditional detection, SAGA identifies the specific generative model used. It uniquely provides multi-granular attribution across five levels: authenticity, generation task (e.g., T2V/I2V), model version, development team, and the precise generator, offering far richer forensic insights. Our novel video transformer architecture, leveraging features from a robust vision foundation model, effectively captures spatio-temporal artifacts. Critically, we introduce a data-efficient pretrain-and-attribute strategy, enabling SAGA to achieve state-of-the-art attribution using only 0.5\% of source-labeled data per class, matching fully supervised performance. Furthermore, we propose Temporal Attention Signatures (T-Sigs), a novel interpretability method that visualizes learned temporal differences, offering the first explanation for why different video generators are distinguishable. Extensive experiments on public datasets, including cross-domain scenarios, demonstrate that SAGA sets a new benchmark for synthetic video provenance, providing crucial, interpretable insights for forensic and regulatory applications.
Towards Source-Free Machine Unlearning
Aug 20, 2025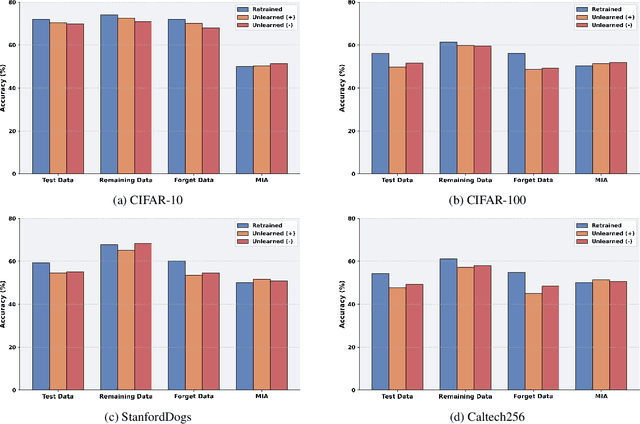
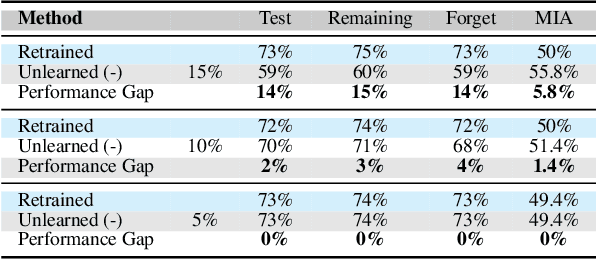
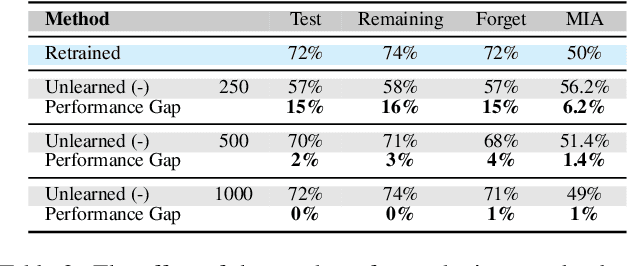
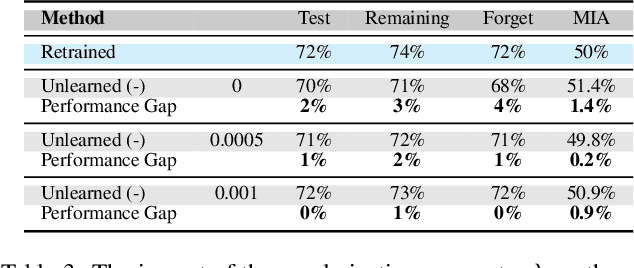
As machine learning becomes more pervasive and data privacy regulations evolve, the ability to remove private or copyrighted information from trained models is becoming an increasingly critical requirement. Existing unlearning methods often rely on the assumption of having access to the entire training dataset during the forgetting process. However, this assumption may not hold true in practical scenarios where the original training data may not be accessible, i.e., the source-free setting. To address this challenge, we focus on the source-free unlearning scenario, where an unlearning algorithm must be capable of removing specific data from a trained model without requiring access to the original training dataset. Building on recent work, we present a method that can estimate the Hessian of the unknown remaining training data, a crucial component required for efficient unlearning. Leveraging this estimation technique, our method enables efficient zero-shot unlearning while providing robust theoretical guarantees on the unlearning performance, while maintaining performance on the remaining data. Extensive experiments over a wide range of datasets verify the efficacy of our method.
TruthLens: Explainable DeepFake Detection for Face Manipulated and Fully Synthetic Data
Mar 20, 2025



Detecting DeepFakes has become a crucial research area as the widespread use of AI image generators enables the effortless creation of face-manipulated and fully synthetic content, yet existing methods are often limited to binary classification (real vs. fake) and lack interpretability. To address these challenges, we propose TruthLens, a novel and highly generalizable framework for DeepFake detection that not only determines whether an image is real or fake but also provides detailed textual reasoning for its predictions. Unlike traditional methods, TruthLens effectively handles both face-manipulated DeepFakes and fully AI-generated content while addressing fine-grained queries such as "Does the eyes/nose/mouth look real or fake?" The architecture of TruthLens combines the global contextual understanding of multimodal large language models like PaliGemma2 with the localized feature extraction capabilities of vision-only models like DINOv2. This hybrid design leverages the complementary strengths of both models, enabling robust detection of subtle manipulations while maintaining interpretability. Extensive experiments on diverse datasets demonstrate that TruthLens outperforms state-of-the-art methods in detection accuracy (by 2-14%) and explainability, in both in-domain and cross-data settings, generalizing effectively across traditional and emerging manipulation techniques.
Towards a Universal Synthetic Video Detector: From Face or Background Manipulations to Fully AI-Generated Content
Dec 16, 2024



Existing DeepFake detection techniques primarily focus on facial manipulations, such as face-swapping or lip-syncing. However, advancements in text-to-video (T2V) and image-to-video (I2V) generative models now allow fully AI-generated synthetic content and seamless background alterations, challenging face-centric detection methods and demanding more versatile approaches. To address this, we introduce the \underline{U}niversal \underline{N}etwork for \underline{I}dentifying \underline{T}ampered and synth\underline{E}tic videos (\texttt{UNITE}) model, which, unlike traditional detectors, captures full-frame manipulations. \texttt{UNITE} extends detection capabilities to scenarios without faces, non-human subjects, and complex background modifications. It leverages a transformer-based architecture that processes domain-agnostic features extracted from videos via the SigLIP-So400M foundation model. Given limited datasets encompassing both facial/background alterations and T2V/I2V content, we integrate task-irrelevant data alongside standard DeepFake datasets in training. We further mitigate the model's tendency to over-focus on faces by incorporating an attention-diversity (AD) loss, which promotes diverse spatial attention across video frames. Combining AD loss with cross-entropy improves detection performance across varied contexts. Comparative evaluations demonstrate that \texttt{UNITE} outperforms state-of-the-art detectors on datasets (in cross-data settings) featuring face/background manipulations and fully synthetic T2V/I2V videos, showcasing its adaptability and generalizable detection capabilities.
Multi-modal Pose Diffuser: A Multimodal Generative Conditional Pose Prior
Oct 18, 2024The Skinned Multi-Person Linear (SMPL) model plays a crucial role in 3D human pose estimation, providing a streamlined yet effective representation of the human body. However, ensuring the validity of SMPL configurations during tasks such as human mesh regression remains a significant challenge , highlighting the necessity for a robust human pose prior capable of discerning realistic human poses. To address this, we introduce MOPED: \underline{M}ulti-m\underline{O}dal \underline{P}os\underline{E} \underline{D}iffuser. MOPED is the first method to leverage a novel multi-modal conditional diffusion model as a prior for SMPL pose parameters. Our method offers powerful unconditional pose generation with the ability to condition on multi-modal inputs such as images and text. This capability enhances the applicability of our approach by incorporating additional context often overlooked in traditional pose priors. Extensive experiments across three distinct tasks-pose estimation, pose denoising, and pose completion-demonstrate that our multi-modal diffusion model-based prior significantly outperforms existing methods. These results indicate that our model captures a broader spectrum of plausible human poses.
EarthGen: Generating the World from Top-Down Views
Sep 02, 2024


In this work, we present a novel method for extensive multi-scale generative terrain modeling. At the core of our model is a cascade of superresolution diffusion models that can be combined to produce consistent images across multiple resolutions. Pairing this concept with a tiled generation method yields a scalable system that can generate thousands of square kilometers of realistic Earth surfaces at high resolution. We evaluate our method on a dataset collected from Bing Maps and show that it outperforms super-resolution baselines on the extreme super-resolution task of 1024x zoom. We also demonstrate its ability to create diverse and coherent scenes via an interactive gigapixel-scale generated map. Finally, we demonstrate how our system can be extended to enable novel content creation applications including controllable world generation and 3D scene generation.
Towards Granularity-adjusted Pixel-level Semantic Annotation
Dec 05, 2023



Recent advancements in computer vision predominantly rely on learning-based systems, leveraging annotations as the driving force to develop specialized models. However, annotating pixel-level information, particularly in semantic segmentation, presents a challenging and labor-intensive task, prompting the need for autonomous processes. In this work, we propose GranSAM which distinguishes itself by providing semantic segmentation at the user-defined granularity level on unlabeled data without the need for any manual supervision, offering a unique contribution in the realm of semantic mask annotation method. Specifically, we propose an approach to enable the Segment Anything Model (SAM) with semantic recognition capability to generate pixel-level annotations for images without any manual supervision. For this, we accumulate semantic information from synthetic images generated by the Stable Diffusion model or web crawled images and employ this data to learn a mapping function between SAM mask embeddings and object class labels. As a result, SAM, enabled with granularity-adjusted mask recognition, can be used for pixel-level semantic annotation purposes. We conducted experiments on the PASCAL VOC 2012 and COCO-80 datasets and observed a +17.95% and +5.17% increase in mIoU, respectively, compared to existing state-of-the-art methods when evaluated under our problem setting.
IDEAL: Improved DEnse locAL Contrastive Learning for Semi-Supervised Medical Image Segmentation
Oct 26, 2022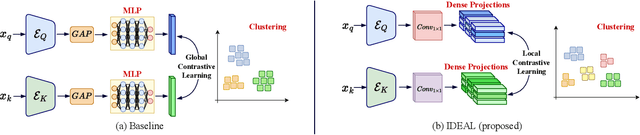
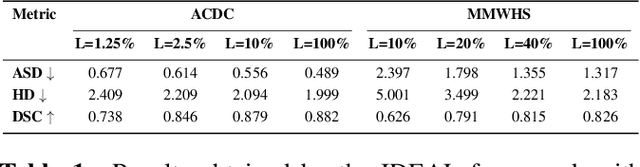
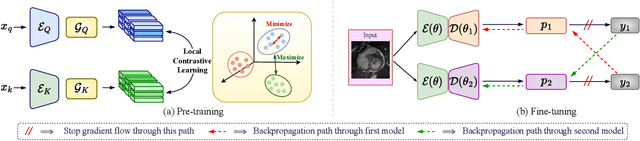
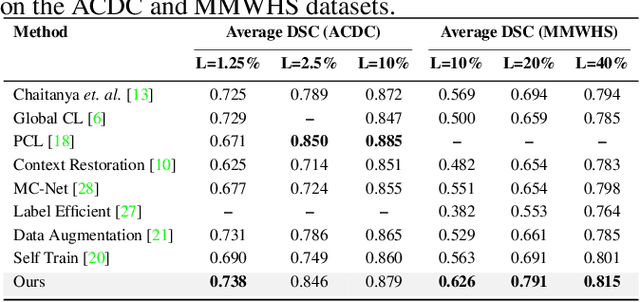
Due to the scarcity of labeled data, Contrastive Self-Supervised Learning (SSL) frameworks have lately shown great potential in several medical image analysis tasks. However, the existing contrastive mechanisms are sub-optimal for dense pixel-level segmentation tasks due to their inability to mine local features. To this end, we extend the concept of metric learning to the segmentation task, using a dense (dis)similarity learning for pre-training a deep encoder network, and employing a semi-supervised paradigm to fine-tune for the downstream task. Specifically, we propose a simple convolutional projection head for obtaining dense pixel-level features, and a new contrastive loss to utilize these dense projections thereby improving the local representations. A bidirectional consistency regularization mechanism involving two-stream model training is devised for the downstream task. Upon comparison, our IDEAL method outperforms the SoTA methods by fair margins on cardiac MRI segmentation.
MFSNet: A Multi Focus Segmentation Network for Skin Lesion Segmentation
Mar 29, 2022
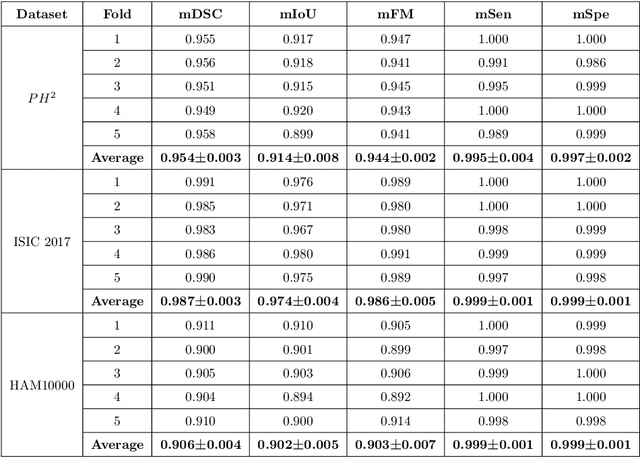

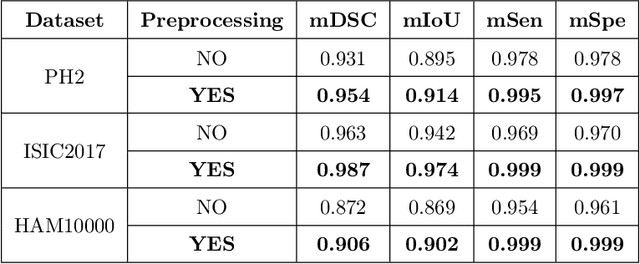
Segmentation is essential for medical image analysis to identify and localize diseases, monitor morphological changes, and extract discriminative features for further diagnosis. Skin cancer is one of the most common types of cancer globally, and its early diagnosis is pivotal for the complete elimination of malignant tumors from the body. This research develops an Artificial Intelligence (AI) framework for supervised skin lesion segmentation employing the deep learning approach. The proposed framework, called MFSNet (Multi-Focus Segmentation Network), uses differently scaled feature maps for computing the final segmentation mask using raw input RGB images of skin lesions. In doing so, initially, the images are preprocessed to remove unwanted artifacts and noises. The MFSNet employs the Res2Net backbone, a recently proposed convolutional neural network (CNN), for obtaining deep features used in a Parallel Partial Decoder (PPD) module to get a global map of the segmentation mask. In different stages of the network, convolution features and multi-scale maps are used in two boundary attention (BA) modules and two reverse attention (RA) modules to generate the final segmentation output. MFSNet, when evaluated on three publicly available datasets: $PH^2$, ISIC 2017, and HAM10000, outperforms state-of-the-art methods, justifying the reliability of the framework. The relevant codes for the proposed approach are accessible at https://github.com/Rohit-Kundu/MFSNet
Doodle It Yourself: Class Incremental Learning by Drawing a Few Sketches
Mar 28, 2022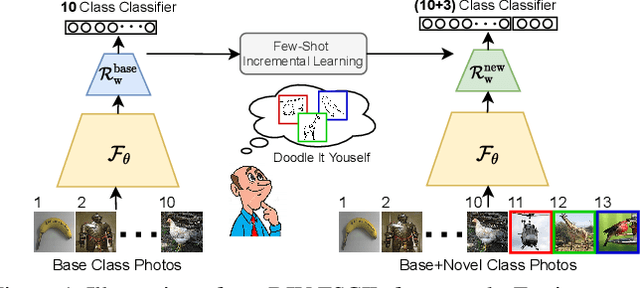
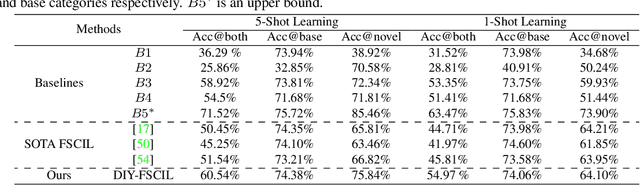
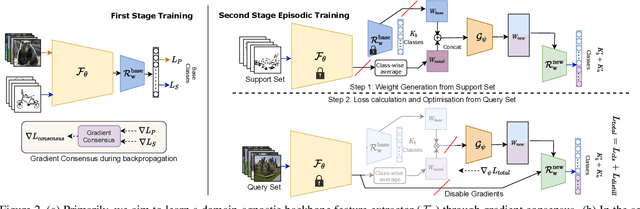
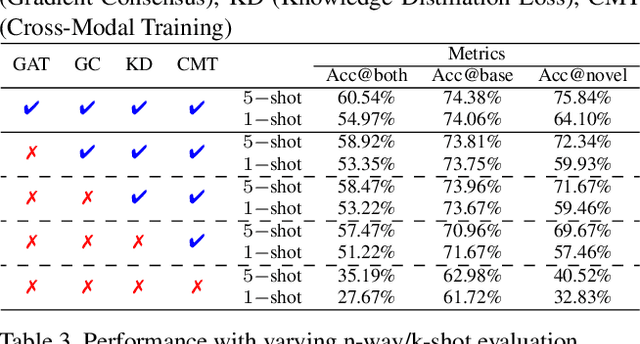
The human visual system is remarkable in learning new visual concepts from just a few examples. This is precisely the goal behind few-shot class incremental learning (FSCIL), where the emphasis is additionally placed on ensuring the model does not suffer from "forgetting". In this paper, we push the boundary further for FSCIL by addressing two key questions that bottleneck its ubiquitous application (i) can the model learn from diverse modalities other than just photo (as humans do), and (ii) what if photos are not readily accessible (due to ethical and privacy constraints). Our key innovation lies in advocating the use of sketches as a new modality for class support. The product is a "Doodle It Yourself" (DIY) FSCIL framework where the users can freely sketch a few examples of a novel class for the model to learn to recognize photos of that class. For that, we present a framework that infuses (i) gradient consensus for domain invariant learning, (ii) knowledge distillation for preserving old class information, and (iii) graph attention networks for message passing between old and novel classes. We experimentally show that sketches are better class support than text in the context of FSCIL, echoing findings elsewhere in the sketching literature.