 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble of CNN classifiers using Sugeno Fuzzy Integral Technique for Cervical Cytology Image Classification
Aug 21, 2021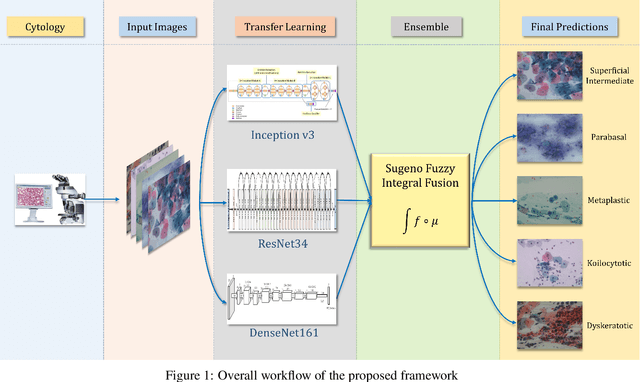
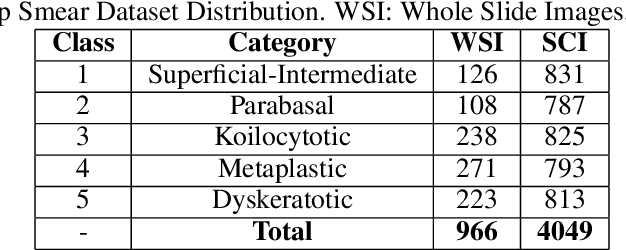
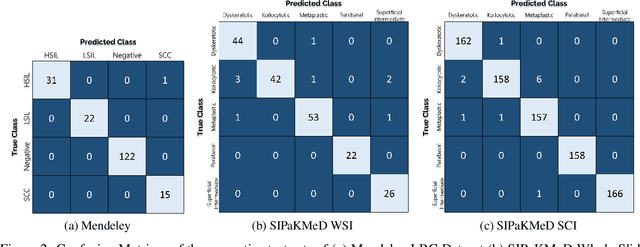
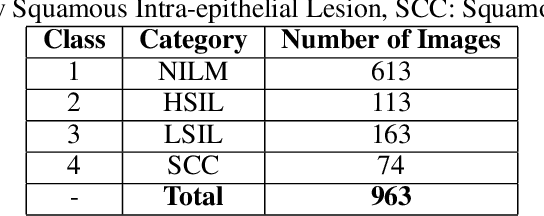
Cervical cancer is the fourth most common category of cancer, affecting more than 500,000 women annually, owing to the slow detection procedure. Early diagnosis can help in treating and even curing cancer, but the tedious, time-consuming testing process makes it impossible to conduct population-wise screening. To aid the pathologists in efficient and reliable detection, in this paper, we propose a fully automated computer-aided diagnosis tool for classifying single-cell and slide images of cervical cancer. The main concern in developing an automatic detection tool for biomedical image classification is the low availability of publicly accessible data. Ensemble Learning is a popular approach for image classification, but simplistic approaches that leverage pre-determined weights to classifiers fail to perform satisfactorily. In this research, we use the Sugeno Fuzzy Integral to ensemble the decision scores from three popular pretrained deep learning models, namely, Inception v3, DenseNet-161 and ResNet-34. The proposed Fuzzy fusion is capable of taking into consideration the confidence scores of the classifiers for each sample, and thus adaptively changing the importance given to each classifier, capturing the complementary information supplied by each, thus leading to superior classification performance. We evaluated the proposed method on three publicly available datasets, the Mendeley Liquid Based Cytology (LBC) dataset, the SIPaKMeD Whole Slide Image (WSI) dataset, and the SIPaKMeD Single Cell Image (SCI) dataset, and the results thus yielded are promising. Analysis of the approach using GradCAM-based visual representations and statistical tests, and comparison of the method with existing and baseline models in literature justify the efficacy of the approach.
Optimizing Speech Emotion Recognition using Manta-Ray Based Feature Selection
Sep 18, 2020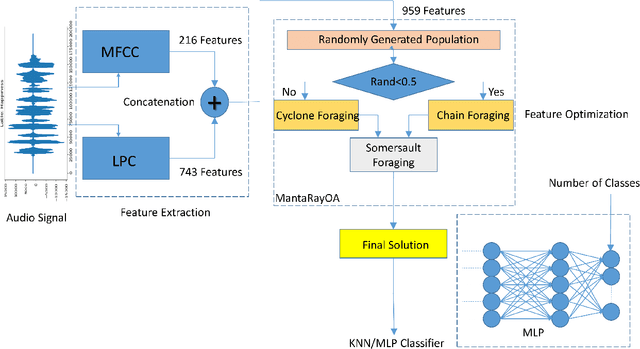


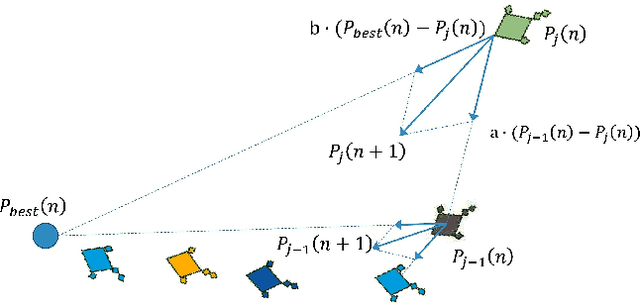
Emotion recognition from audio signals has been regarded as a challenging task in signal processing as it can be considered as a collection of static and dynamic classification tasks. Recognition of emotions from speech data has been heavily relied upon end-to-end feature extraction and classification using machine learning models, though the absence of feature selection and optimization have restrained the performance of these methods. Recent studies have shown that Mel Frequency Cepstral Coefficients (MFCC) have been emerged as one of the most relied feature extraction methods, though it circumscribes the accuracy of classification with a very small feature dimension. In this paper, we propose that the concatenation of features, extracted by using different existing feature extraction methods can not only boost the classification accuracy but also expands the possibility of efficient feature selection. We have used Linear Predictive Coding (LPC) apart from the MFCC feature extraction method, before feature merging. Besides, we have performed a novel application of Manta Ray optimization in speech emotion recognition tasks that resulted in a state-of-the-art result in this field. We have evaluated the performance of our model using SAVEE and Emo-DB, two publicly available datasets. Our proposed method outperformed all the existing methods in speech emotion analysis and resulted in a decent result in these two datasets with a classification accuracy of 97.06% and 97.68% respectively.
Multi-scale Attention U-Net : A Modified U-Net Architecture for Scene Segmentation
Sep 15, 2020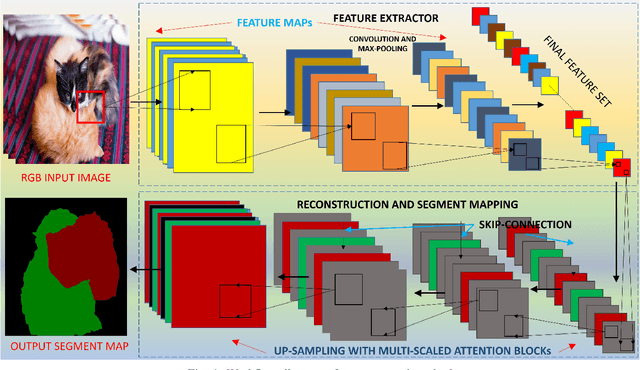
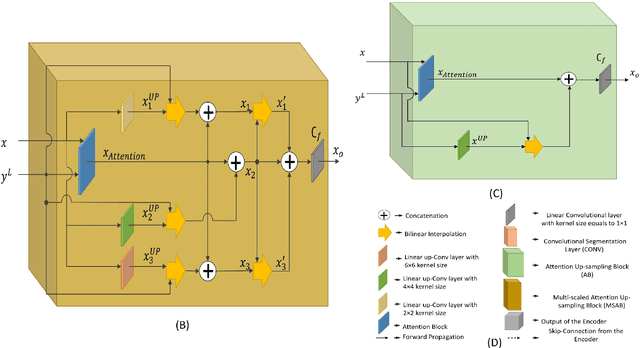
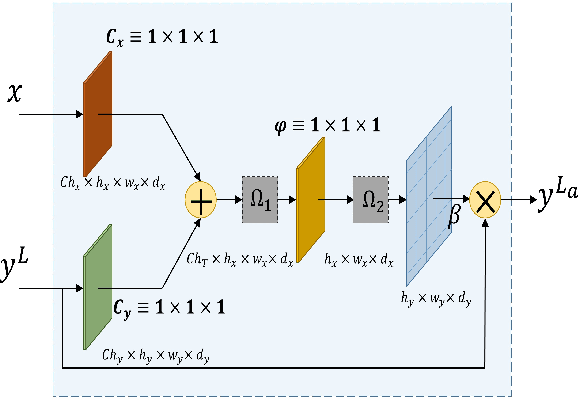

Despite the growing success of Convolution neural networks (CNN) in the recent past in the task of scene segmentation, the standard models lack some of the important features that might result in sub-optimal segmentation outputs. The widely used encoder-decoder architecture extracts and uses several redundant and low-level features at different steps and different scales. Also, these networks fail to map the long-range dependencies of local features, which results in discriminative feature maps corresponding to each semantic class in the resulting segmented image. In this paper, we propose a novel multi-scale attention network for scene segmentation purposes by using the rich contextual information from an image. Different from the original UNet architecture we have used attention gates which take the features from the encoder and the output of the pyramid pool as input and produced out-put is further concatenated with the up-sampled output of the previous pyramid-pool layer and mapped to the next subsequent layer. This network can map local features with their global counterparts with improved accuracy and emphasize on discriminative image regions by focusing on relevant local features only. We also propose a compound loss function by optimizing the IoU loss and fusing Dice Loss and Weighted Cross-entropy loss with it to achieve an optimal solution at a faster convergence rate. We have evaluated our model on two standard datasets named PascalVOC2012 and ADE20k and was able to achieve mean IoU of 79.88% and 44.88% on the two datasets respectively, and compared our result with the widely known models to prove the superiority of our model over them.