 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLINGUAL: Language-INtegrated GUidance in Active Learning for Medical Image Segmentation
Nov 18, 2025Although active learning (AL) in segmentation tasks enables experts to annotate selected regions of interest (ROIs) instead of entire images, it remains highly challenging, labor-intensive, and cognitively demanding due to the blurry and ambiguous boundaries commonly observed in medical images. Also, in conventional AL, annotation effort is a function of the ROI- larger regions make the task cognitively easier but incur higher annotation costs, whereas smaller regions demand finer precision and more attention from the expert. In this context, language guidance provides an effective alternative, requiring minimal expert effort while bypassing the cognitively demanding task of precise boundary delineation in segmentation. Towards this goal, we introduce LINGUAL: a framework that receives natural language instructions from an expert, translates them into executable programs through in-context learning, and automatically performs the corresponding sequence of sub-tasks without any human intervention. We demonstrate the effectiveness of LINGUAL in active domain adaptation (ADA) achieving comparable or superior performance to AL baselines while reducing estimated annotation time by approximately 80%.
C2P-GCN: Cell-to-Patch Graph Convolutional Network for Colorectal Cancer Grading
Mar 08, 2024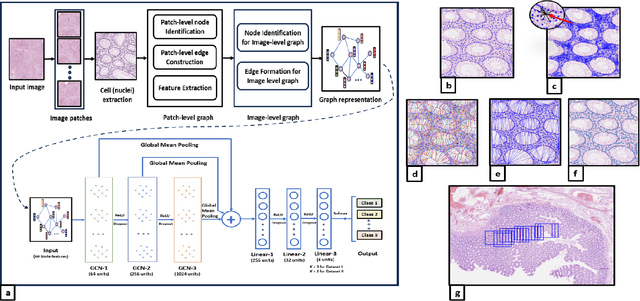
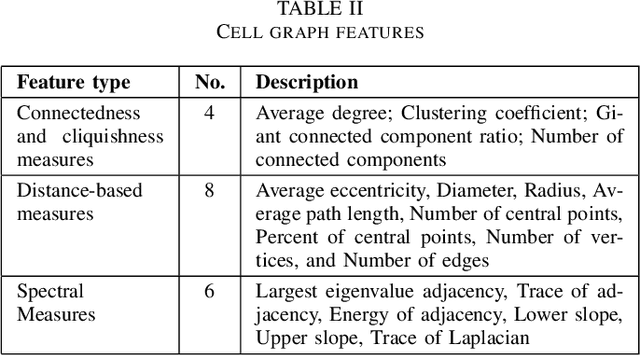

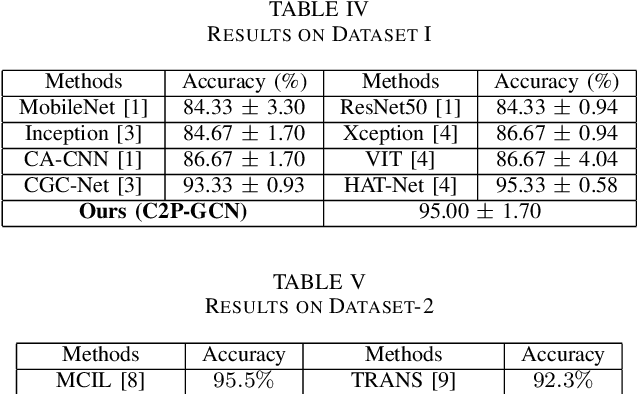
Graph-based learning approaches, due to their ability to encode tissue/organ structure information, are increasingly favored for grading colorectal cancer histology images. Recent graph-based techniques involve dividing whole slide images (WSIs) into smaller or medium-sized patches, and then building graphs on each patch for direct use in training. This method, however, fails to capture the tissue structure information present in an entire WSI and relies on training from a significantly large dataset of image patches. In this paper, we propose a novel cell-to-patch graph convolutional network (C2P-GCN), which is a two-stage graph formation-based approach. In the first stage, it forms a patch-level graph based on the cell organization on each patch of a WSI. In the second stage, it forms an image-level graph based on a similarity measure between patches of a WSI considering each patch as a node of a graph. This graph representation is then fed into a multi-layer GCN-based classification network. Our approach, through its dual-phase graph construction, effectively gathers local structural details from individual patches and establishes a meaningful connection among all patches across a WSI. As C2P-GCN integrates the structural data of an entire WSI into a single graph, it allows our model to work with significantly fewer training data compared to the latest models for colorectal cancer. Experimental validation of C2P-GCN on two distinct colorectal cancer datasets demonstrates the effectiveness of our method.
Towards Granularity-adjusted Pixel-level Semantic Annotation
Dec 05, 2023



Recent advancements in computer vision predominantly rely on learning-based systems, leveraging annotations as the driving force to develop specialized models. However, annotating pixel-level information, particularly in semantic segmentation, presents a challenging and labor-intensive task, prompting the need for autonomous processes. In this work, we propose GranSAM which distinguishes itself by providing semantic segmentation at the user-defined granularity level on unlabeled data without the need for any manual supervision, offering a unique contribution in the realm of semantic mask annotation method. Specifically, we propose an approach to enable the Segment Anything Model (SAM) with semantic recognition capability to generate pixel-level annotations for images without any manual supervision. For this, we accumulate semantic information from synthetic images generated by the Stable Diffusion model or web crawled images and employ this data to learn a mapping function between SAM mask embeddings and object class labels. As a result, SAM, enabled with granularity-adjusted mask recognition, can be used for pixel-level semantic annotation purposes. We conducted experiments on the PASCAL VOC 2012 and COCO-80 datasets and observed a +17.95% and +5.17% increase in mIoU, respectively, compared to existing state-of-the-art methods when evaluated under our problem setting.
Active Sparse Conversations for Improved Audio-Visual Embodied Navigation
Jun 06, 2023



Efficient navigation towards an audio-goal necessitates an embodied agent to not only possess the ability to use audio-visual cues effectively, but also be equipped to actively (but occasionally) seek human/oracle assistance without sacrificing autonomy, e.g., when it is uncertain of where to navigate towards locating a noisy or sporadic audio goal. To this end, we present CAVEN -- a conversational audio-visual embodied navigation agent that is capable of posing navigation questions to a human/oracle and processing the oracle responses; both in free-form natural language. At the core of CAVEN is a multimodal hierarchical reinforcement learning (RL) setup that is equipped with a high-level policy that is trained to choose from one of three low-level policies (at every step), namely: (i) to navigate using audio-visual cues, or (ii) to frame a question to the oracle and receive a short or detailed response, or (iii) ask generic questions (when unsure of what to ask) and receive instructions. Key to generating the agent's questions is our novel TrajectoryNet that forecasts the most likely next steps to the goal and a QuestionNet that uses these steps to produce a question. All the policies are learned end-to-end via the RL setup, with penalties to enforce sparsity in receiving navigation instructions from the oracle. To evaluate the performance of CAVEN, we present extensive experiments on the SoundSpaces framework for the task of semantic audio-visual navigation. Our results show that CAVEN achieves upto 12% gain in performance over competing methods, especially in localizing new sound sources, even in the presence of auditory distractions.
AVLEN: Audio-Visual-Language Embodied Navigation in 3D Environments
Oct 14, 2022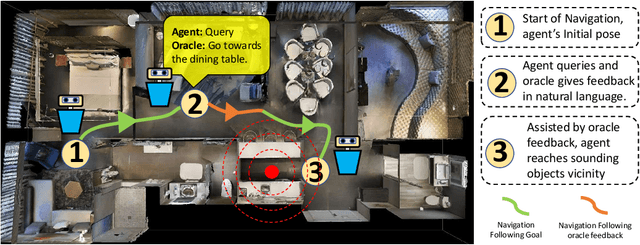
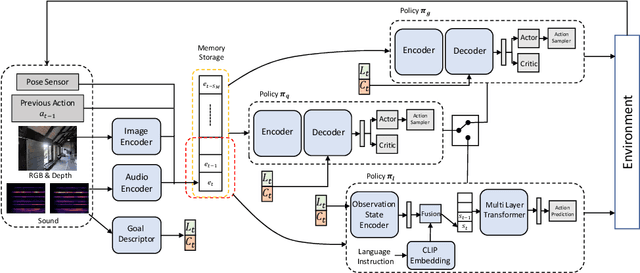


Recent years have seen embodied visual navigation advance in two distinct directions: (i) in equipping the AI agent to follow natural language instructions, and (ii) in making the navigable world multimodal, e.g., audio-visual navigation. However, the real world is not only multimodal, but also often complex, and thus in spite of these advances, agents still need to understand the uncertainty in their actions and seek instructions to navigate. To this end, we present AVLEN~ -- an interactive agent for Audio-Visual-Language Embodied Navigation. Similar to audio-visual navigation tasks, the goal of our embodied agent is to localize an audio event via navigating the 3D visual world; however, the agent may also seek help from a human (oracle), where the assistance is provided in free-form natural language. To realize these abilities, AVLEN uses a multimodal hierarchical reinforcement learning backbone that learns: (a) high-level policies to choose either audio-cues for navigation or to query the oracle, and (b) lower-level policies to select navigation actions based on its audio-visual and language inputs. The policies are trained via rewarding for the success on the navigation task while minimizing the number of queries to the oracle. To empirically evaluate AVLEN, we present experiments on the SoundSpaces framework for semantic audio-visual navigation tasks. Our results show that equipping the agent to ask for help leads to a clear improvement in performance, especially in challenging cases, e.g., when the sound is unheard during training or in the presence of distractor sounds.
Exploiting Context for Robustness to Label Noise in Active Learning
Oct 18, 2020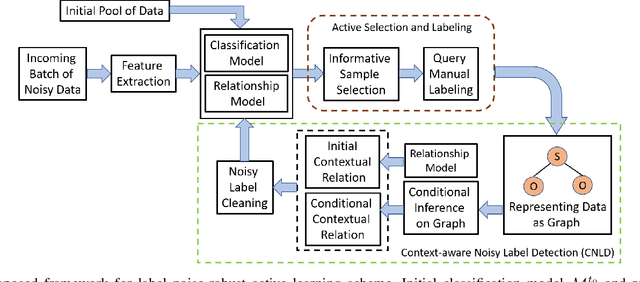

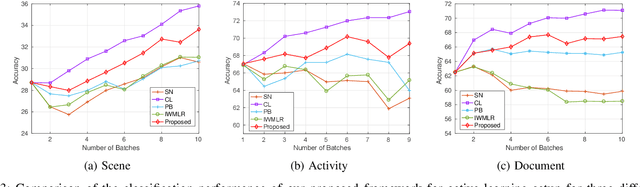
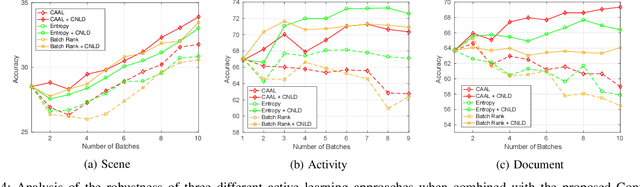
Several works in computer vision have demonstrated the effectiveness of active learning for adapting the recognition model when new unlabeled data becomes available. Most of these works consider that labels obtained from the annotator are correct. However, in a practical scenario, as the quality of the labels depends on the annotator, some of the labels might be wrong, which results in degraded recognition performance. In this paper, we address the problems of i) how a system can identify which of the queried labels are wrong and ii) how a multi-class active learning system can be adapted to minimize the negative impact of label noise. Towards solving the problems, we propose a noisy label filtering based learning approach where the inter-relationship (context) that is quite common in natural data is utilized to detect the wrong labels. We construct a graphical representation of the unlabeled data to encode these relationships and obtain new beliefs on the graph when noisy labels are available. Comparing the new beliefs with the prior relational information, we generate a dissimilarity score to detect the incorrect labels and update the recognition model with correct labels which result in better recognition performance. This is demonstrated in three different applications: scene classification, activity classification, and document classification.
FLaPS: Federated Learning and Privately Scaling
Sep 13, 2020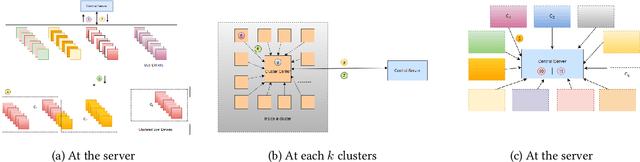



Federated learning (FL) is a distributed learning process where the model (weights and checkpoints) is transferred to the devices that posses data rather than the classical way of transferring and aggregating the data centrally. In this way, sensitive data does not leave the user devices. FL uses the FedAvg algorithm, which is trained in the iterative model averaging way, on the non-iid and unbalanced distributed data, without depending on the data quantity. Some issues with the FL are, 1) no scalability, as the model is iteratively trained over all the devices, which amplifies with device drops; 2) security and privacy trade-off of the learning process still not robust enough and 3) overall communication efficiency and the cost are higher. To mitigate these challenges we present Federated Learning and Privately Scaling (FLaPS) architecture, which improves scalability as well as the security and privacy of the system. The devices are grouped into clusters which further gives better privacy scaled turn around time to finish a round of training. Therefore, even if a device gets dropped in the middle of training, the whole process can be started again after a definite amount of time. The data and model both are communicated using differentially private reports with iterative shuffling which provides a better privacy-utility trade-off. We evaluated FLaPS on MNIST, CIFAR10, and TINY-IMAGENET-200 dataset using various CNN models. Experimental results prove FLaPS to be an improved, time and privacy scaled environment having better and comparable after-learning-parameters with respect to the central and FL models.
Text-based Localization of Moments in a Video Corpus
Aug 20, 2020
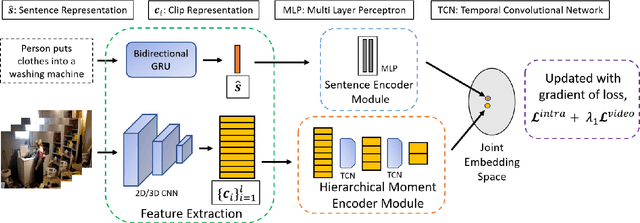
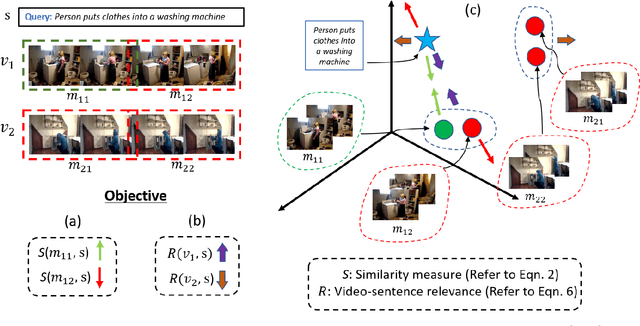

Prior works on text-based video moment localization focus on temporally grounding the textual query in an untrimmed video. These works assume that the relevant video is already known and attempt to localize the moment on that relevant video only. Different from such works, we relax this assumption and address the task of localizing moments in a corpus of videos for a given sentence query. This task poses a unique challenge as the system is required to perform: (i) retrieval of the relevant video where only a segment of the video corresponds with the queried sentence, and (ii) temporal localization of moment in the relevant video based on sentence query. Towards overcoming this challenge, we propose Hierarchical Moment Alignment Network (HMAN) which learns an effective joint embedding space for moments and sentences. In addition to learning subtle differences between intra-video moments, HMAN focuses on distinguishing inter-video global semantic concepts based on sentence queries. Qualitative and quantitative results on three benchmark text-based video moment retrieval datasets - Charades-STA, DiDeMo, and ActivityNet Captions - demonstrate that our method achieves promising performance on the proposed task of temporal localization of moments in a corpus of videos.
LAC : LSTM AUTOENCODER with Community for Insider Threat Detection
Aug 13, 2020

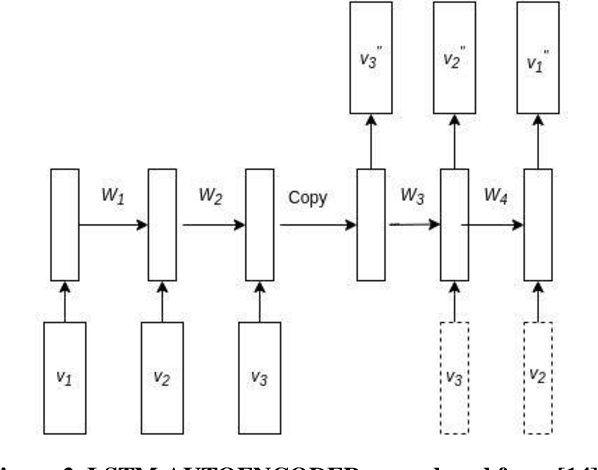
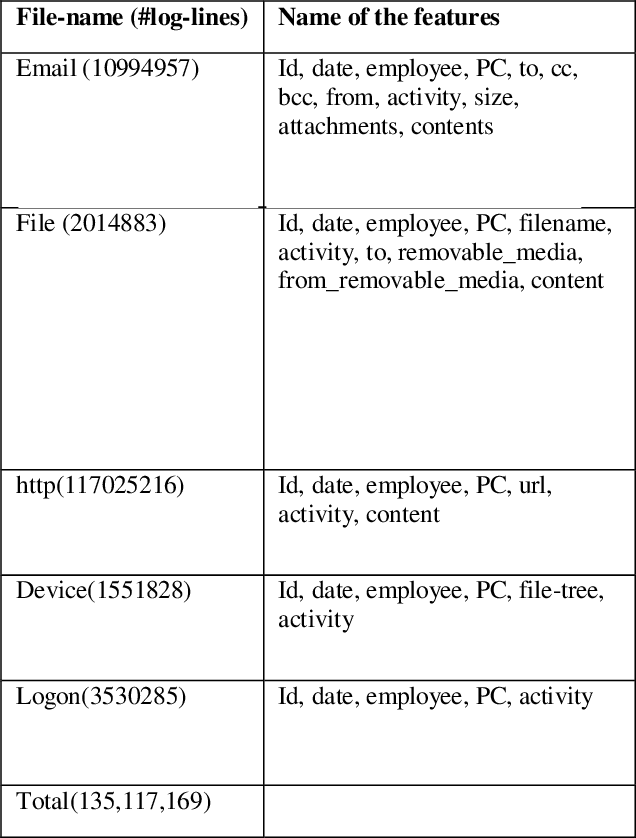
The employees of any organization, institute, or industry, spend a significant amount of time on a computer network, where they develop their own routine of activities in the form of network transactions over a time period. Insider threat detection involves identifying deviations in the routines or anomalies which may cause harm to the organization in the form of data leaks and secrets sharing. If not automated, this process involves feature engineering for modeling human behavior which is a tedious and time-consuming task. Anomalies in human behavior are forwarded to a human analyst for final threat classification. We developed an unsupervised deep neural network model using LSTM AUTOENCODER which learns to mimic the behavior of individual employees from their day-wise time-stamped sequence of activities. It predicts the threat scenario via significant loss from anomalous routine. Employees in a community tend to align their routine with each other rather than the employees outside their communities, this motivates us to explore a variation of the AUTOENCODER, LSTM AUTOENCODER- trained on the interleaved sequences of activities in the Community (LAC). We evaluate the model on the CERT v6.2 dataset and perform analysis on the loss for normal and anomalous routine across 4000 employees. The aim of our paper is to detect the anomalous employees as well as to explore how the surrounding employees are affecting that employees' routine over time.
Connecting the Dots: Detecting Adversarial Perturbations Using Context Inconsistency
Jul 24, 2020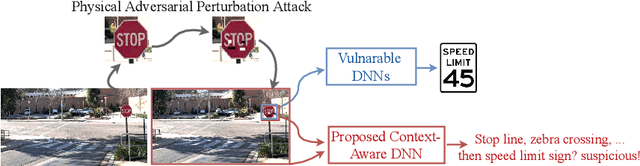
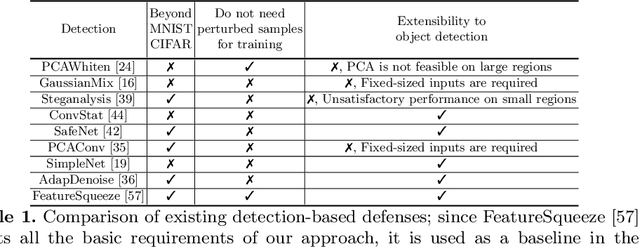
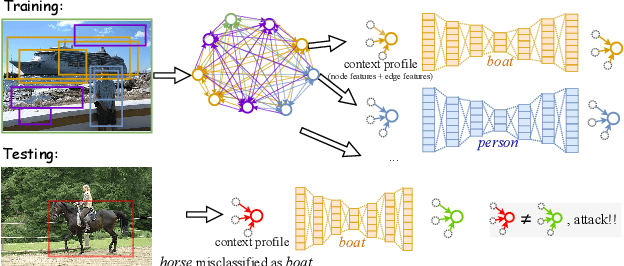

There has been a recent surge in research on adversarial perturbations that defeat Deep Neural Networks (DNNs) in machine vision; most of these perturbation-based attacks target object classifiers. Inspired by the observation that humans are able to recognize objects that appear out of place in a scene or along with other unlikely objects, we augment the DNN with a system that learns context consistency rules during training and checks for the violations of the same during testing. Our approach builds a set of auto-encoders, one for each object class, appropriately trained so as to output a discrepancy between the input and output if an added adversarial perturbation violates context consistency rules. Experiments on PASCAL VOC and MS COCO show that our method effectively detects various adversarial attacks and achieves high ROC-AUC (over 0.95 in most cases); this corresponds to over 20% improvement over a state-of-the-art context-agnostic method.