 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Does Vision Meet Language? Understanding and Refining Visual Fusion in MLLMs via Contrastive Attention
Jan 13, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable progress in vision-language understanding, yet how they internally integrate visual and textual information remains poorly understood. To bridge this gap, we perform a systematic layer-wise masking analysis across multiple architectures, revealing how visual-text fusion evolves within MLLMs. The results show that fusion emerges at several specific layers rather than being uniformly distributed across the network, and certain models exhibit a late-stage "review" phenomenon where visual signals are reactivated before output generation. Besides, we further analyze layer-wise attention evolution and observe persistent high-attention noise on irrelevant regions, along with gradually increasing attention on text-aligned areas. Guided by these insights, we introduce a training-free contrastive attention framework that models the transformation between early fusion and final layers to highlight meaningful attention shifts. Extensive experiments across various MLLMs and benchmarks validate our analysis and demonstrate that the proposed approach improves multimodal reasoning performance. Code will be released.
Investigating Self-regulated Learning Sequences within a Generative AI-based Intelligent Tutoring System
Jan 13, 2026There has been a growing trend in employing generative artificial intelligence (GenAI) techniques to support learning. Moreover, scholars have reached a consensus on the critical role of self-regulated learning (SRL) in ensuring learning effectiveness within GenAI-assisted learning environments, making it essential to capture students' dynamic SRL patterns. In this study, we extracted students' interaction patterns with GenAI from trace data as they completed a problem-solving task within a GenAI-assisted intelligent tutoring system. Students' purpose of using GenAI was also analyzed from the perspective of information processing, i.e., information acquisition and information transformation. Using sequential and clustering analysis, this study classified participants into two groups based on their SRL sequences. These two groups differed in the frequency and temporal characteristics of GenAI use. In addition, most students used GenAI for information acquisition rather than information transformation, while the correlation between the purpose of using GenAI and learning performance was not statistically significant. Our findings inform both pedagogical design and the development of GenAI-assisted learning environments.
Seeing Right but Saying Wrong: Inter- and Intra-Layer Refinement in MLLMs without Training
Jan 12, 2026Multimodal Large Language Models (MLLMs) have demonstrated strong capabilities across a variety of vision-language tasks. However, their internal reasoning often exhibits a critical inconsistency: although deeper layers may attend to the correct visual regions, final predictions are frequently misled by noisy attention from earlier layers. This results in a disconnect between what the model internally understands and what it ultimately expresses, a phenomenon we describe as seeing it right but saying it wrong. To address this issue, we propose DualPD, a dual-perspective decoding refinement strategy that enhances the visual understanding without any additional training. DualPD consists of two components. (1) The layer-wise attention-guided contrastive logits module captures how the belief in the correct answer evolves by comparing output logits between layers that exhibit the largest attention shift. (2) The head-wise information filtering module suppresses low-contribution attention heads that focus on irrelevant regions, thereby improving attention quality within each layer. Experiments conducted on both the LLaVA and Qwen-VL model families across multiple multimodal benchmarks demonstrate that DualPD consistently improves accuracy without training, confirming its effectiveness and generalizability. The code will be released upon publication.
JPU: Bridging Jailbreak Defense and Unlearning via On-Policy Path Rectification
Jan 06, 2026Despite extensive safety alignment, Large Language Models (LLMs) often fail against jailbreak attacks. While machine unlearning has emerged as a promising defense by erasing specific harmful parameters, current methods remain vulnerable to diverse jailbreaks. We first conduct an empirical study and discover that this failure mechanism is caused by jailbreaks primarily activating non-erased parameters in the intermediate layers. Further, by probing the underlying mechanism through which these circumvented parameters reassemble into the prohibited output, we verify the persistent existence of dynamic $\textbf{jailbreak paths}$ and show that the inability to rectify them constitutes the fundamental gap in existing unlearning defenses. To bridge this gap, we propose $\textbf{J}$ailbreak $\textbf{P}$ath $\textbf{U}$nlearning (JPU), which is the first to rectify dynamic jailbreak paths towards safety anchors by dynamically mining on-policy adversarial samples to expose vulnerabilities and identify jailbreak paths. Extensive experiments demonstrate that JPU significantly enhances jailbreak resistance against dynamic attacks while preserving the model's utility.
Beyond Plain Demos: A Demo-centric Anchoring Paradigm for In-Context Learning in Alzheimer's Disease Detection
Nov 10, 2025Detecting Alzheimer's disease (AD) from narrative transcripts challenges large language models (LLMs): pre-training rarely covers this out-of-distribution task, and all transcript demos describe the same scene, producing highly homogeneous contexts. These factors cripple both the model's built-in task knowledge (\textbf{task cognition}) and its ability to surface subtle, class-discriminative cues (\textbf{contextual perception}). Because cognition is fixed after pre-training, improving in-context learning (ICL) for AD detection hinges on enriching perception through better demonstration (demo) sets. We demonstrate that standard ICL quickly saturates, its demos lack diversity (context width) and fail to convey fine-grained signals (context depth), and that recent task vector (TV) approaches improve broad task adaptation by injecting TV into the LLMs' hidden states (HSs), they are ill-suited for AD detection due to the mismatch of injection granularity, strength and position. To address these bottlenecks, we introduce \textbf{DA4ICL}, a demo-centric anchoring framework that jointly expands context width via \emph{\textbf{Diverse and Contrastive Retrieval}} (DCR) and deepens each demo's signal via \emph{\textbf{Projected Vector Anchoring}} (PVA) at every Transformer layer. Across three AD benchmarks, DA4ICL achieves large, stable gains over both ICL and TV baselines, charting a new paradigm for fine-grained, OOD and low-resource LLM adaptation.
Explicit Knowledge-Guided In-Context Learning for Early Detection of Alzheimer's Disease
Nov 09, 2025Detecting Alzheimer's Disease (AD) from narrative transcripts remains a challenging task for large language models (LLMs), particularly under out-of-distribution (OOD) and data-scarce conditions. While in-context learning (ICL) provides a parameter-efficient alternative to fine-tuning, existing ICL approaches often suffer from task recognition failure, suboptimal demonstration selection, and misalignment between label words and task objectives, issues that are amplified in clinical domains like AD detection. We propose Explicit Knowledge In-Context Learners (EK-ICL), a novel framework that integrates structured explicit knowledge to enhance reasoning stability and task alignment in ICL. EK-ICL incorporates three knowledge components: confidence scores derived from small language models (SLMs) to ground predictions in task-relevant patterns, parsing feature scores to capture structural differences and improve demo selection, and label word replacement to resolve semantic misalignment with LLM priors. In addition, EK-ICL employs a parsing-based retrieval strategy and ensemble prediction to mitigate the effects of semantic homogeneity in AD transcripts. Extensive experiments across three AD datasets demonstrate that EK-ICL significantly outperforms state-of-the-art fine-tuning and ICL baselines. Further analysis reveals that ICL performance in AD detection is highly sensitive to the alignment of label semantics and task-specific context, underscoring the importance of explicit knowledge in clinical reasoning under low-resource conditions.
Step More: Going Beyond Single Backpropagation in Meta Learning Based Model Editing
Aug 06, 2025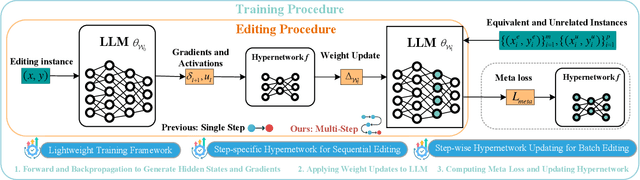

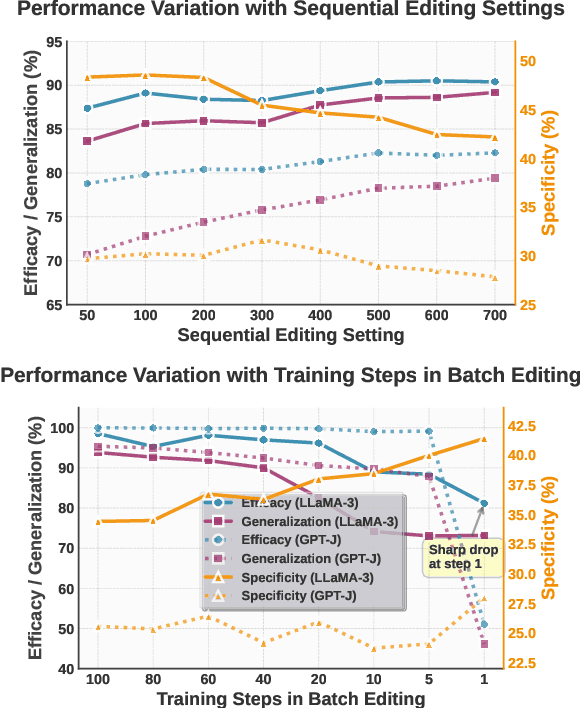

Large Language Models (LLMs) underpin many AI applications, but their static nature makes updating knowledge costly. Model editing offers an efficient alternative by injecting new information through targeted parameter modifications. In particular, meta-learning-based model editing (MLBME) methods have demonstrated notable advantages in both editing effectiveness and efficiency. Despite this, we find that MLBME exhibits suboptimal performance in low-data scenarios, and its training efficiency is bottlenecked by the computation of KL divergence. To address these, we propose $\textbf{S}$tep $\textbf{M}$ore $\textbf{Edit}$ ($\textbf{SMEdit}$), a novel MLBME method that adopts $\textbf{M}$ultiple $\textbf{B}$ackpro$\textbf{P}$agation $\textbf{S}$teps ($\textbf{MBPS}$) to improve editing performance under limited supervision and a norm regularization on weight updates to improve training efficiency. Experimental results on two datasets and two LLMs demonstrate that SMEdit outperforms prior MLBME baselines and the MBPS strategy can be seamlessly integrated into existing methods to further boost their performance. Our code will be released soon.
Precise Zero-Shot Pointwise Ranking with LLMs through Post-Aggregated Global Context Information
Jun 12, 2025Recent advancements have successfully harnessed the power of Large Language Models (LLMs) for zero-shot document ranking, exploring a variety of prompting strategies. Comparative approaches like pairwise and listwise achieve high effectiveness but are computationally intensive and thus less practical for larger-scale applications. Scoring-based pointwise approaches exhibit superior efficiency by independently and simultaneously generating the relevance scores for each candidate document. However, this independence ignores critical comparative insights between documents, resulting in inconsistent scoring and suboptimal performance. In this paper, we aim to improve the effectiveness of pointwise methods while preserving their efficiency through two key innovations: (1) We propose a novel Global-Consistent Comparative Pointwise Ranking (GCCP) strategy that incorporates global reference comparisons between each candidate and an anchor document to generate contrastive relevance scores. We strategically design the anchor document as a query-focused summary of pseudo-relevant candidates, which serves as an effective reference point by capturing the global context for document comparison. (2) These contrastive relevance scores can be efficiently Post-Aggregated with existing pointwise methods, seamlessly integrating essential Global Context information in a training-free manner (PAGC). Extensive experiments on the TREC DL and BEIR benchmark demonstrate that our approach significantly outperforms previous pointwise methods while maintaining comparable efficiency. Our method also achieves competitive performance against comparative methods that require substantially more computational resources. More analyses further validate the efficacy of our anchor construction strategy.
Rethinking the Residual Distribution of Locate-then-Editing Methods in Model Editing
Feb 06, 2025Model editing is a powerful technique for updating the knowledge of Large Language Models (LLMs). Locate-then-edit methods are a popular class of approaches that first identify the critical layers storing knowledge, then compute the residual of the last critical layer based on the edited knowledge, and finally perform multi-layer updates using a least-squares solution by evenly distributing the residual from the first critical layer to the last. Although these methods achieve promising results, they have been shown to degrade the original knowledge of LLMs. We argue that residual distribution leads to this issue. To explore this, we conduct a comprehensive analysis of residual distribution in locate-then-edit methods from both empirical and theoretical perspectives, revealing that residual distribution introduces editing errors, leading to inaccurate edits. To address this issue, we propose the Boundary Layer UpdatE (BLUE) strategy to enhance locate-then-edit methods. Sequential batch editing experiments on three LLMs and two datasets demonstrate that BLUE not only delivers an average performance improvement of 35.59\%, significantly advancing the state of the art in model editing, but also enhances the preservation of LLMs' general capabilities. Our code is available at https://github.com/xpq-tech/BLUE.
How to Complete Domain Tuning while Keeping General Ability in LLM: Adaptive Layer-wise and Element-wise Regularization
Jan 23, 2025Large Language Models (LLMs) exhibit strong general-purpose language capabilities. However, fine-tuning these models on domain-specific tasks often leads to catastrophic forgetting, where the model overwrites or loses essential knowledge acquired during pretraining. This phenomenon significantly limits the broader applicability of LLMs. To address this challenge, we propose a novel approach to compute the element-wise importance of model parameters crucial for preserving general knowledge during fine-tuning. Our method utilizes a dual-objective optimization strategy: (1) regularization loss to retain the parameter crucial for general knowledge; (2) cross-entropy loss to adapt to domain-specific tasks. Additionally, we introduce layer-wise coefficients to account for the varying contributions of different layers, dynamically balancing the dual-objective optimization. Extensive experiments on scientific, medical, and physical tasks using GPT-J and LLaMA-3 demonstrate that our approach mitigates catastrophic forgetting while enhancing model adaptability. Compared to previous methods, our solution is approximately 20 times faster and requires only 10%-15% of the storage, highlighting the practical efficiency. The code will be released.