 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Instructive Information from Ranked Multiple Candidates for Multi-Document Scientific Summarization
Apr 16, 2024



Automatically condensing multiple topic-related scientific papers into a succinct and concise summary is referred to as Multi-Document Scientific Summarization (MDSS). Currently, while commonly used abstractive MDSS methods can generate flexible and coherent summaries, the difficulty in handling global information and the lack of guidance during decoding still make it challenging to generate better summaries. To alleviate these two shortcomings, this paper introduces summary candidates into MDSS, utilizing the global information of the document set and additional guidance from the summary candidates to guide the decoding process. Our insights are twofold: Firstly, summary candidates can provide instructive information from both positive and negative perspectives, and secondly, selecting higher-quality candidates from multiple options contributes to producing better summaries. Drawing on the insights, we propose a summary candidates fusion framework -- Disentangling Instructive information from Ranked candidates (DIR) for MDSS. Specifically, DIR first uses a specialized pairwise comparison method towards multiple candidates to pick out those of higher quality. Then DIR disentangles the instructive information of summary candidates into positive and negative latent variables with Conditional Variational Autoencoder. These variables are further incorporated into the decoder to guide generation. We evaluate our approach with three different types of Transformer-based models and three different types of candidates, and consistently observe noticeable performance improvements according to automatic and human evaluation. More analyses further demonstrate the effectiveness of our model in handling global information and enhancing decoding controllability.
Recommending Missed Citations Identified by Reviewers: A New Task, Dataset and Baselines
Mar 04, 2024



Citing comprehensively and appropriately has become a challenging task with the explosive growth of scientific publications. Current citation recommendation systems aim to recommend a list of scientific papers for a given text context or a draft paper. However, none of the existing work focuses on already included citations of full papers, which are imperfect and still have much room for improvement. In the scenario of peer reviewing, it is a common phenomenon that submissions are identified as missing vital citations by reviewers. This may lead to a negative impact on the credibility and validity of the research presented. To help improve citations of full papers, we first define a novel task of Recommending Missed Citations Identified by Reviewers (RMC) and construct a corresponding expert-labeled dataset called CitationR. We conduct an extensive evaluation of several state-of-the-art methods on CitationR. Furthermore, we propose a new framework RMCNet with an Attentive Reference Encoder module mining the relevance between papers, already-made citations, and missed citations. Empirical results prove that RMC is challenging, with the proposed architecture outperforming previous methods in all metrics. We release our dataset and benchmark models to motivate future research on this challenging new task.
A Case-Based Reasoning Framework for Adaptive Prompting in Cross-Domain Text-to-SQL
Apr 26, 2023



Recent advancements in Large Language Models (LLMs), such as Codex, ChatGPT and GPT-4 have significantly impacted the AI community, including Text-to-SQL tasks. Some evaluations and analyses on LLMs show their potential to generate SQL queries but they point out poorly designed prompts (e.g. simplistic construction or random sampling) limit LLMs' performance and may cause unnecessary or irrelevant outputs. To address these issues, we propose CBR-ApSQL, a Case-Based Reasoning (CBR)-based framework combined with GPT-3.5 for precise control over case-relevant and case-irrelevant knowledge in Text-to-SQL tasks. We design adaptive prompts for flexibly adjusting inputs for GPT-3.5, which involves (1) adaptively retrieving cases according to the question intention by de-semantizing the input question, and (2) an adaptive fallback mechanism to ensure the informativeness of the prompt, as well as the relevance between cases and the prompt. In the de-semanticization phase, we designed Semantic Domain Relevance Evaluator(SDRE), combined with Poincar\'e detector(mining implicit semantics in hyperbolic space), TextAlign(discovering explicit matches), and Positector (part-of-speech detector). SDRE semantically and syntactically generates in-context exemplar annotations for the new case. On the three cross-domain datasets, our framework outperforms the state-of-the-art(SOTA) model in execution accuracy by 3.7\%, 2.5\%, and 8.2\%, respectively.
Multi-Document Scientific Summarization from a Knowledge Graph-Centric View
Sep 09, 2022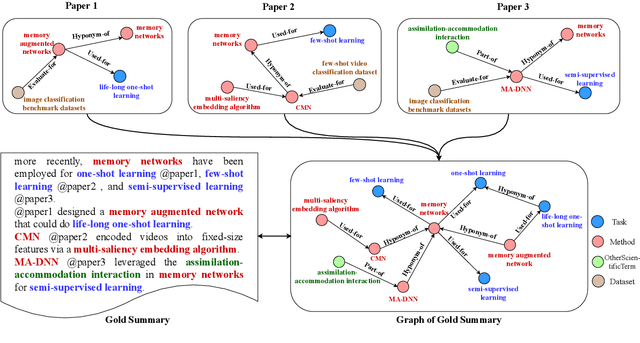

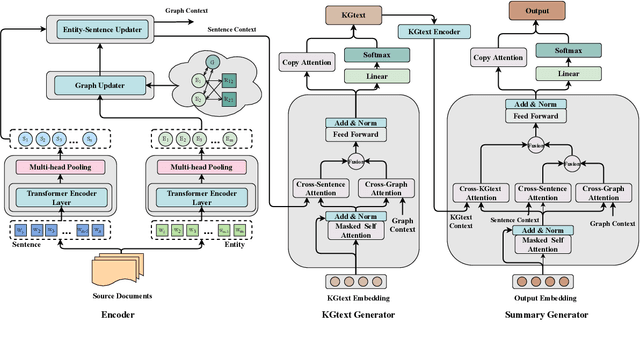

Multi-Document Scientific Summarization (MDSS) aims to produce coherent and concise summaries for clusters of topic-relevant scientific papers. This task requires precise understanding of paper content and accurate modeling of cross-paper relationships. Knowledge graphs convey compact and interpretable structured information for documents, which makes them ideal for content modeling and relationship modeling. In this paper, we present KGSum, an MDSS model centred on knowledge graphs during both the encoding and decoding process. Specifically, in the encoding process, two graph-based modules are proposed to incorporate knowledge graph information into paper encoding, while in the decoding process, we propose a two-stage decoder by first generating knowledge graph information of summary in the form of descriptive sentences, followed by generating the final summary. Empirical results show that the proposed architecture brings substantial improvements over baselines on the Multi-Xscience dataset.