 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-resource Hallucination Detection for Text Generation via Graph-based Contextual Knowledge Triples Modeling
Sep 18, 2024



LLMs obtain remarkable performance but suffer from hallucinations. Most research on detecting hallucination focuses on the questions with short and concrete correct answers that are easy to check the faithfulness. Hallucination detections for text generation with open-ended answers are more challenging. Some researchers use external knowledge to detect hallucinations in generated texts, but external resources for specific scenarios are hard to access. Recent studies on detecting hallucinations in long text without external resources conduct consistency comparison among multiple sampled outputs. To handle long texts, researchers split long texts into multiple facts and individually compare the consistency of each pairs of facts. However, these methods (1) hardly achieve alignment among multiple facts; (2) overlook dependencies between multiple contextual facts. In this paper, we propose a graph-based context-aware (GCA) hallucination detection for text generations, which aligns knowledge facts and considers the dependencies between contextual knowledge triples in consistency comparison. Particularly, to align multiple facts, we conduct a triple-oriented response segmentation to extract multiple knowledge triples. To model dependencies among contextual knowledge triple (facts), we construct contextual triple into a graph and enhance triples' interactions via message passing and aggregating via RGCN. To avoid the omission of knowledge triples in long text, we conduct a LLM-based reverse verification via reconstructing the knowledge triples. Experiments show that our model enhances hallucination detection and excels all baselines.
Perception of Knowledge Boundary for Large Language Models through Semi-open-ended Question Answering
May 23, 2024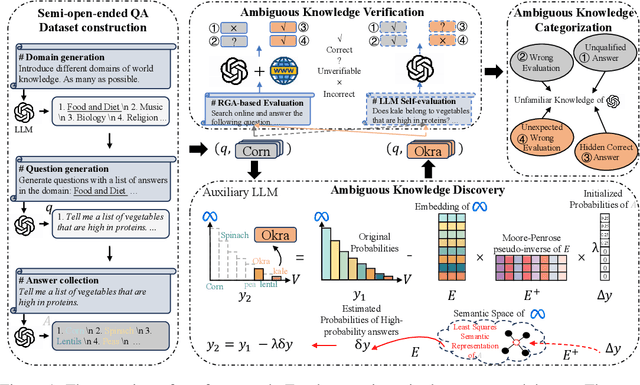
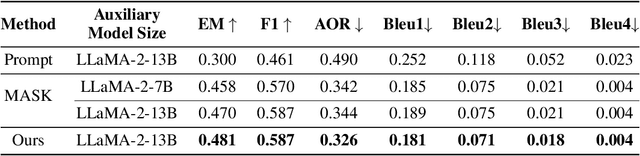
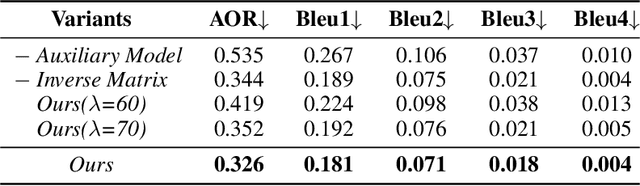
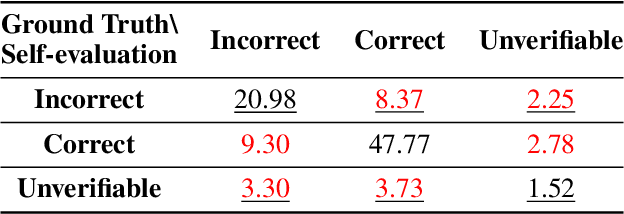
Large Language Models (LLMs) are widely used for knowledge-seeking yet suffer from hallucinations. The knowledge boundary (KB) of an LLM limits its factual understanding, beyond which it may begin to hallucinate. Investigating the perception of LLMs' KB is crucial for detecting hallucinations and LLMs' reliable generation. Current studies perceive LLMs' KB on questions with a concrete answer (close-ended questions) while paying limited attention to semi-open-ended questions (SoeQ) that correspond to many potential answers. Some researchers achieve it by judging whether the question is answerable or not. However, this paradigm is unsuitable for SoeQ, which are usually partially answerable, containing both answerable and ambiguous (unanswerable) answers. Ambiguous answers are essential for knowledge-seeking, but they may go beyond the KB of LLMs. In this paper, we perceive the LLMs' KB with SoeQ by discovering more ambiguous answers. First, we apply an LLM-based approach to construct SoeQ and obtain answers from a target LLM. Unfortunately, the output probabilities of mainstream black-box LLMs are inaccessible to sample for low-probability ambiguous answers. Therefore, we apply an open-sourced auxiliary model to explore ambiguous answers for the target LLM. We calculate the nearest semantic representation for existing answers to estimate their probabilities, with which we reduce the generation probability of high-probability answers to achieve a more effective generation. Finally, we compare the results from the RAG-based evaluation and LLM self-evaluation to categorize four types of ambiguous answers that are beyond the KB of the target LLM. Following our method, we construct a dataset to perceive the KB for GPT-4. We find that GPT-4 performs poorly on SoeQ and is often unaware of its KB. Besides, our auxiliary model, LLaMA-2-13B, is effective in discovering more ambiguous answers.
Two-stage Generative Question Answering on Temporal Knowledge Graph Using Large Language Models
Feb 26, 2024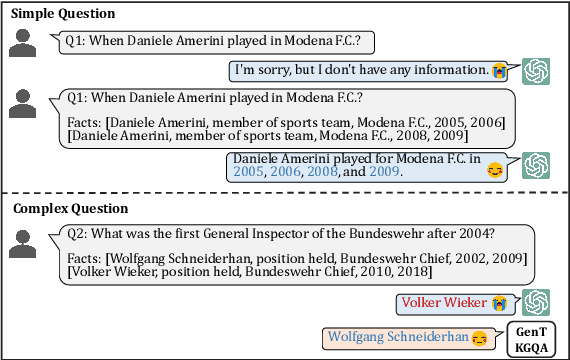
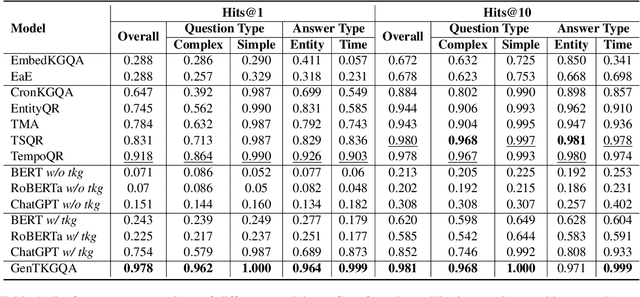
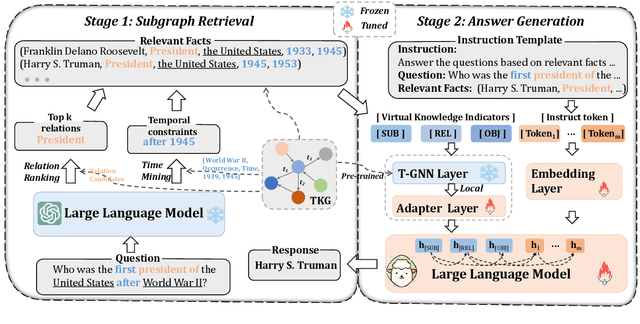
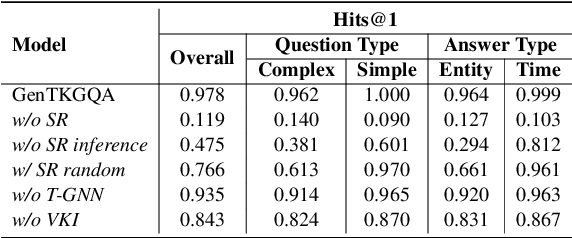
Temporal knowledge graph question answering (TKGQA) poses a significant challenge task, due to the temporal constraints hidden in questions and the answers sought from dynamic structured knowledge. Although large language models (LLMs) have made considerable progress in their reasoning ability over structured data, their application to the TKGQA task is a relatively unexplored area. This paper first proposes a novel generative temporal knowledge graph question answering framework, GenTKGQA, which guides LLMs to answer temporal questions through two phases: Subgraph Retrieval and Answer Generation. First, we exploit LLM's intrinsic knowledge to mine temporal constraints and structural links in the questions without extra training, thus narrowing down the subgraph search space in both temporal and structural dimensions. Next, we design virtual knowledge indicators to fuse the graph neural network signals of the subgraph and the text representations of the LLM in a non-shallow way, which helps the open-source LLM deeply understand the temporal order and structural dependencies among the retrieved facts through instruction tuning. Experimental results demonstrate that our model outperforms state-of-the-art baselines, even achieving 100\% on the metrics for the simple question type.
POMP: Probability-driven Meta-graph Prompter for LLMs in Low-resource Unsupervised Neural Machine Translation
Jan 16, 2024



Low-resource languages (LRLs) face challenges in supervised neural machine translation due to limited parallel data, prompting research into unsupervised methods. Unsupervised neural machine translation (UNMT) methods, including back-translation, transfer learning, and pivot-based translation, offer practical solutions for LRL translation, but they are hindered by issues like synthetic data noise, language bias, and error propagation, which can potentially be mitigated by Large Language Models (LLMs). LLMs have advanced NMT with in-context learning (ICL) and supervised fine-tuning methods, but insufficient training data results in poor performance in LRLs. We argue that LLMs can mitigate the linguistic noise with auxiliary languages to improve translations in LRLs. In this paper, we propose Probability-driven Meta-graph Prompter (POMP), a novel approach employing a dynamic, sampling-based graph of multiple auxiliary languages to enhance LLMs' translation capabilities for LRLs. POMP involves constructing a directed acyclic meta-graph for each source language, from which we dynamically sample multiple paths to prompt LLMs to mitigate the linguistic noise and improve translations during training. We use the BLEURT metric to evaluate the translations and back-propagate rewards, estimated by scores, to update the probabilities of auxiliary languages in the paths. Our experiments show significant improvements in the translation quality of three LRLs, demonstrating the effectiveness of our approach.
GROVE: A Retrieval-augmented Complex Story Generation Framework with A Forest of Evidence
Oct 24, 2023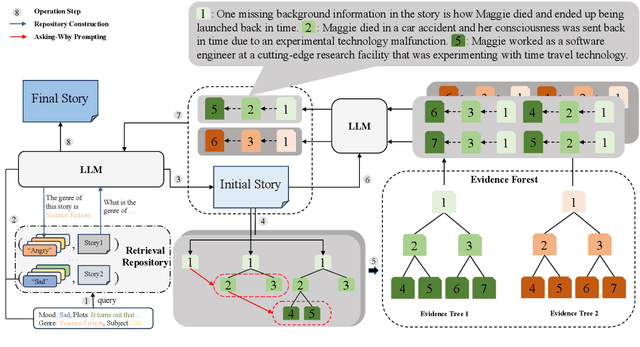
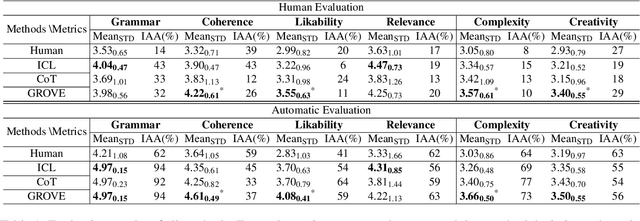


Conditional story generation is significant in human-machine interaction, particularly in producing stories with complex plots. While Large language models (LLMs) perform well on multiple NLP tasks, including story generation, it is challenging to generate stories with both complex and creative plots. Existing methods often rely on detailed prompts to guide LLMs to meet target conditions, which inadvertently restrict the creative potential of the generated stories. We argue that leveraging information from exemplary human-written stories facilitates generating more diverse plotlines. Delving deeper into story details helps build complex and credible plots. In this paper, we propose a retrieval-au\textbf{G}mented sto\textbf{R}y generation framework with a f\textbf{O}rest of e\textbf{V}id\textbf{E}nce (GROVE) to enhance stories' complexity. We build a retrieval repository for target conditions to produce few-shot examples to prompt LLMs. Additionally, we design an ``asking-why'' prompting scheme that extracts a forest of evidence, providing compensation for the ambiguities that may occur in the generated story. This iterative process uncovers underlying story backgrounds. Finally, we select the most fitting chains of evidence from the evidence forest and integrate them into the generated story, thereby enhancing the narrative's complexity and credibility. Experimental results and numerous examples verify the effectiveness of our method.
Retrieval-augmented GPT-3.5-based Text-to-SQL Framework with Sample-aware Prompting and Dynamic Revision Chain
Jul 11, 2023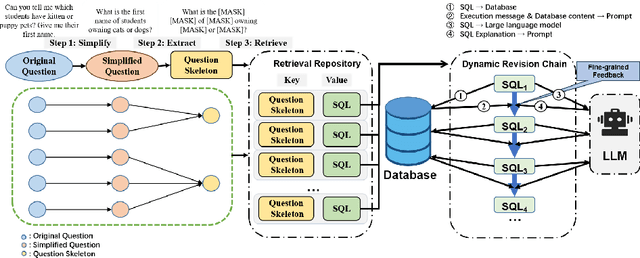
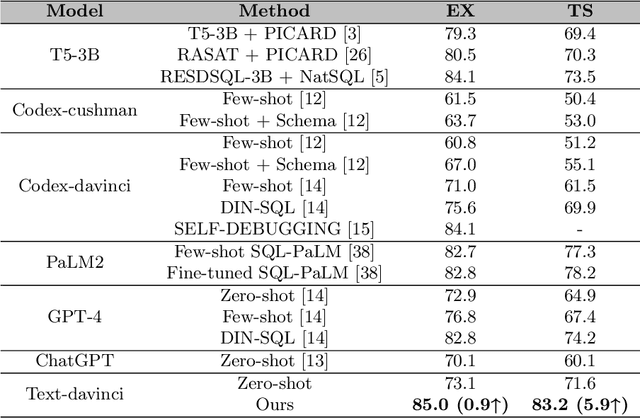


Text-to-SQL aims at generating SQL queries for the given natural language questions and thus helping users to query databases. Prompt learning with large language models (LLMs) has emerged as a recent approach, which designs prompts to lead LLMs to understand the input question and generate the corresponding SQL. However, it faces challenges with strict SQL syntax requirements. Existing work prompts the LLMs with a list of demonstration examples (i.e. question-SQL pairs) to generate SQL, but the fixed prompts can hardly handle the scenario where the semantic gap between the retrieved demonstration and the input question is large. In this paper, we propose a retrieval-augmented prompting method for a LLM-based Text-to-SQL framework, involving sample-aware prompting and a dynamic revision chain. Our approach incorporates sample-aware demonstrations, which include the composition of SQL operators and fine-grained information related to the given question. To retrieve questions sharing similar intents with input questions, we propose two strategies for assisting retrieval. Firstly, we leverage LLMs to simplify the original questions, unifying the syntax and thereby clarifying the users' intentions. To generate executable and accurate SQLs without human intervention, we design a dynamic revision chain which iteratively adapts fine-grained feedback from the previously generated SQL. Experimental results on three Text-to-SQL benchmarks demonstrate the superiority of our method over strong baseline models.
A Case-Based Reasoning Framework for Adaptive Prompting in Cross-Domain Text-to-SQL
Apr 26, 2023



Recent advancements in Large Language Models (LLMs), such as Codex, ChatGPT and GPT-4 have significantly impacted the AI community, including Text-to-SQL tasks. Some evaluations and analyses on LLMs show their potential to generate SQL queries but they point out poorly designed prompts (e.g. simplistic construction or random sampling) limit LLMs' performance and may cause unnecessary or irrelevant outputs. To address these issues, we propose CBR-ApSQL, a Case-Based Reasoning (CBR)-based framework combined with GPT-3.5 for precise control over case-relevant and case-irrelevant knowledge in Text-to-SQL tasks. We design adaptive prompts for flexibly adjusting inputs for GPT-3.5, which involves (1) adaptively retrieving cases according to the question intention by de-semantizing the input question, and (2) an adaptive fallback mechanism to ensure the informativeness of the prompt, as well as the relevance between cases and the prompt. In the de-semanticization phase, we designed Semantic Domain Relevance Evaluator(SDRE), combined with Poincar\'e detector(mining implicit semantics in hyperbolic space), TextAlign(discovering explicit matches), and Positector (part-of-speech detector). SDRE semantically and syntactically generates in-context exemplar annotations for the new case. On the three cross-domain datasets, our framework outperforms the state-of-the-art(SOTA) model in execution accuracy by 3.7\%, 2.5\%, and 8.2\%, respectively.