 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-stage Generative Question Answering on Temporal Knowledge Graph Using Large Language Models
Feb 26, 2024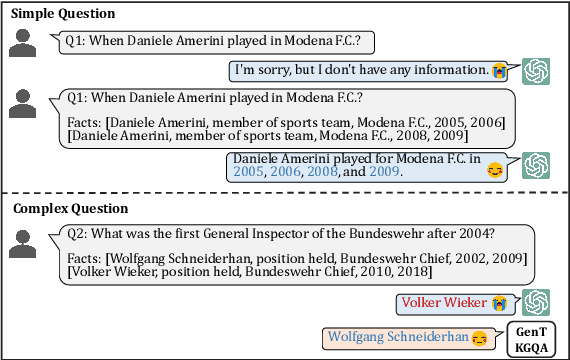
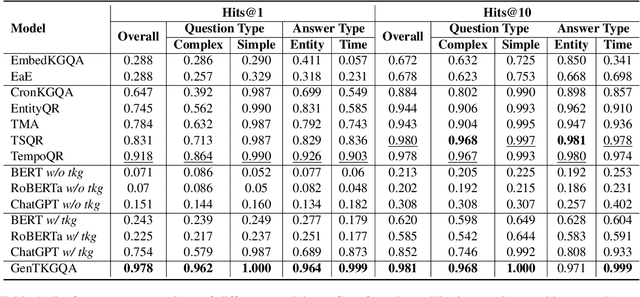
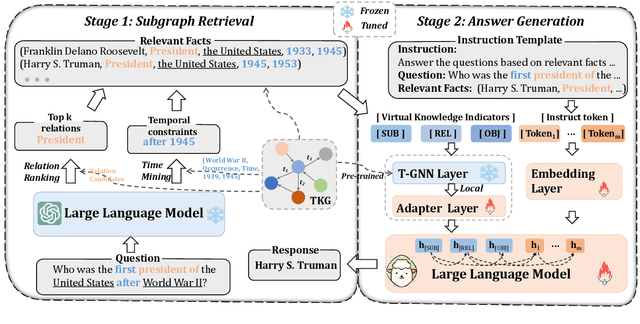
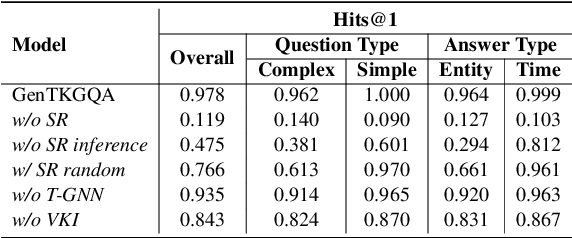
Temporal knowledge graph question answering (TKGQA) poses a significant challenge task, due to the temporal constraints hidden in questions and the answers sought from dynamic structured knowledge. Although large language models (LLMs) have made considerable progress in their reasoning ability over structured data, their application to the TKGQA task is a relatively unexplored area. This paper first proposes a novel generative temporal knowledge graph question answering framework, GenTKGQA, which guides LLMs to answer temporal questions through two phases: Subgraph Retrieval and Answer Generation. First, we exploit LLM's intrinsic knowledge to mine temporal constraints and structural links in the questions without extra training, thus narrowing down the subgraph search space in both temporal and structural dimensions. Next, we design virtual knowledge indicators to fuse the graph neural network signals of the subgraph and the text representations of the LLM in a non-shallow way, which helps the open-source LLM deeply understand the temporal order and structural dependencies among the retrieved facts through instruction tuning. Experimental results demonstrate that our model outperforms state-of-the-art baselines, even achieving 100\% on the metrics for the simple question type.
A Unified Generative Framework based on Prompt Learning for Various Information Extraction Tasks
Sep 23, 2022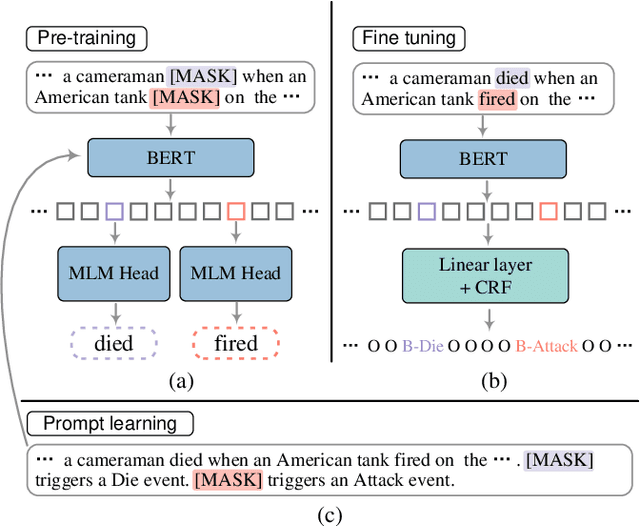
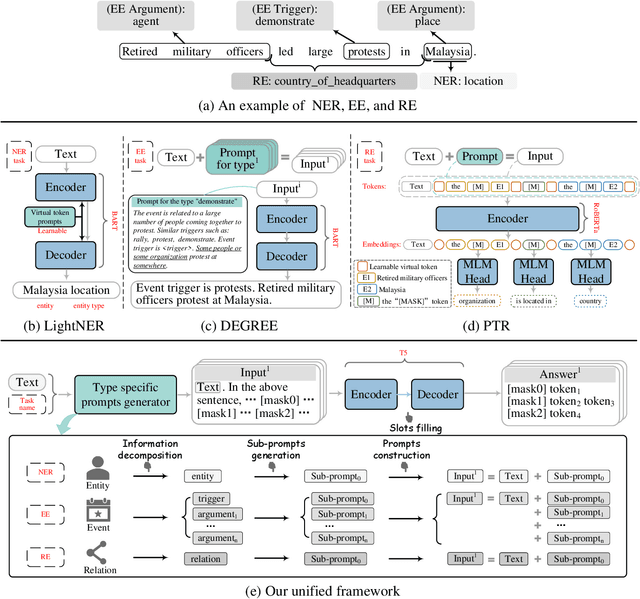
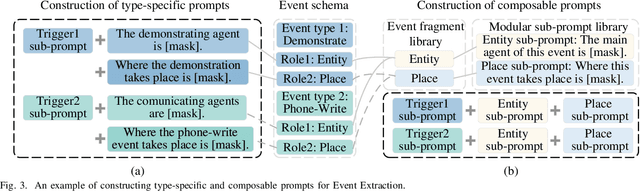
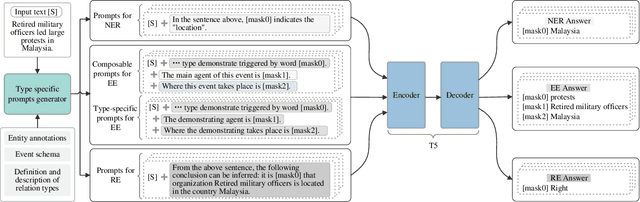
Prompt learning is an effective paradigm that bridges gaps between the pre-training tasks and the corresponding downstream applications. Approaches based on this paradigm have achieved great transcendent results in various applications. However, it still needs to be answered how to design a unified framework based on the prompt learning paradigm for various information extraction tasks. In this paper, we propose a novel composable prompt-based generative framework, which could be applied to a wide range of tasks in the field of Information Extraction. Specifically, we reformulate information extraction tasks into the form of filling slots in pre-designed type-specific prompts, which consist of one or multiple sub-prompts. A strategy of constructing composable prompts is proposed to enhance the generalization ability to extract events in data-scarce scenarios. Furthermore, to fit this framework, we transform Relation Extraction into the task of determining semantic consistency in prompts. The experimental results demonstrate that our approach surpasses compared baselines on real-world datasets in data-abundant and data-scarce scenarios. Further analysis of the proposed framework is presented, as well as numerical experiments conducted to investigate impact factors of performance on various tasks.
ADMMiRNN: Training RNN with Stable Convergence via An Efficient ADMM Approach
Jun 17, 2020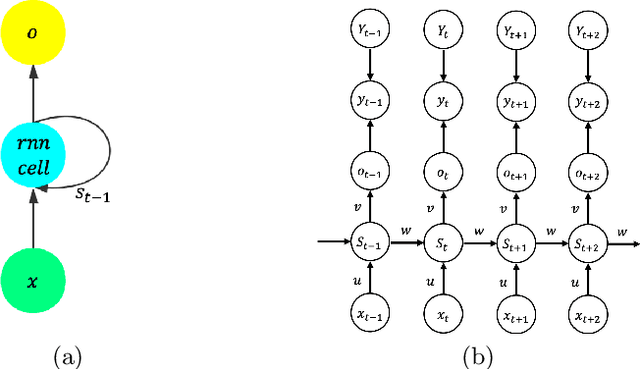

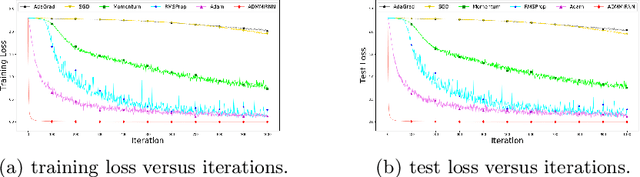
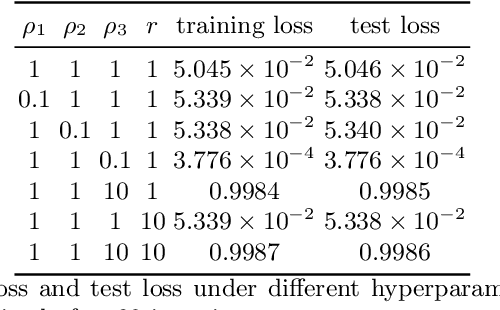
It is hard to train Recurrent Neural Network (RNN) with stable convergence and avoid gradient vanishing and exploding, as the weights in the recurrent unit are repeated from iteration to iteration. Moreover, RNN is sensitive to the initialization of weights and bias, which brings difficulty in the training phase. With the gradient-free feature and immunity to poor conditions, the Alternating Direction Method of Multipliers (ADMM) has become a promising algorithm to train neural networks beyond traditional stochastic gradient algorithms. However, ADMM could not be applied to train RNN directly since the state in the recurrent unit is repetitively updated over timesteps. Therefore, this work builds a new framework named ADMMiRNN upon the unfolded form of RNN to address the above challenges simultaneously and provides novel update rules and theoretical convergence analysis. We explicitly specify key update rules in the iterations of ADMMiRNN with deliberately constructed approximation techniques and solutions to each subproblem instead of vanilla ADMM. Numerical experiments are conducted on MNIST and text classification tasks, where ADMMiRNN achieves convergent results and outperforms compared baselines. Furthermore, ADMMiRNN trains RNN in a more stable way without gradient vanishing or exploding compared to the stochastic gradient algorithms. Source code has been available at https://github.com/TonyTangYu/ADMMiRNN.
Event Arguments Extraction via Dilate Gated Convolutional Neural Network with Enhanced Local Features
Jun 02, 2020
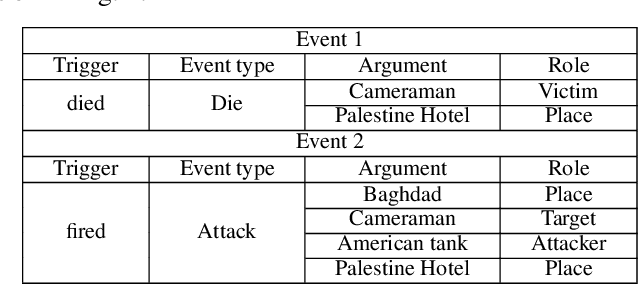
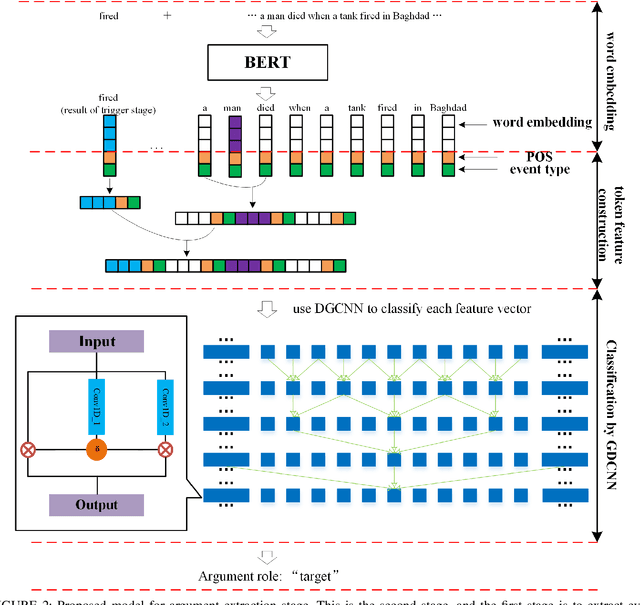
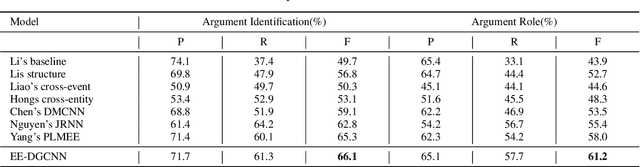
Event Extraction plays an important role in information-extraction to understand the world. Event extraction could be split into two subtasks: one is event trigger extraction, the other is event arguments extraction. However, the F-Score of event arguments extraction is much lower than that of event trigger extraction, i.e. in the most recent work, event trigger extraction achieves 80.7%, while event arguments extraction achieves only 58%. In pipelined structures, the difficulty of event arguments extraction lies in its lack of classification feature, and the much higher computation consumption. In this work, we proposed a novel Event Extraction approach based on multi-layer Dilate Gated Convolutional Neural Network (EE-DGCNN) which has fewer parameters. In addition, enhanced local information is incorporated into word features, to assign event arguments roles for triggers predicted by the first subtask. The numerical experiments demonstrated significant performance improvement beyond state-of-art event extraction approaches on real-world datasets. Further analysis of extraction procedure is presented, as well as experiments are conducted to analyze impact factors related to the performance improvement.