 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADMMiRNN: Training RNN with Stable Convergence via An Efficient ADMM Approach
Paper and Code
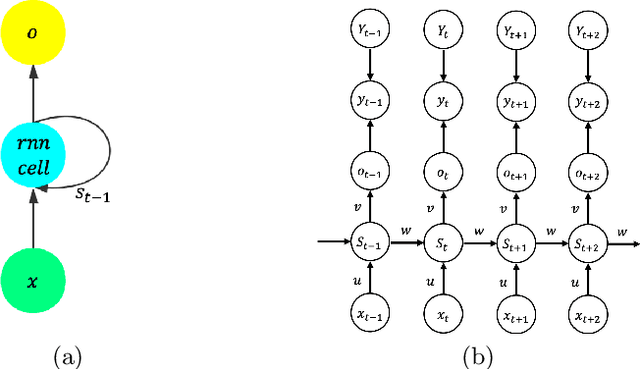

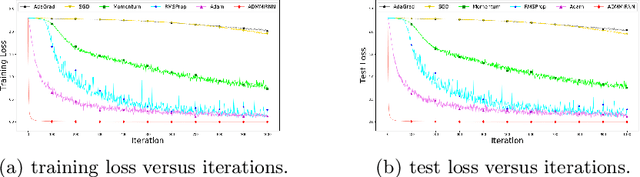
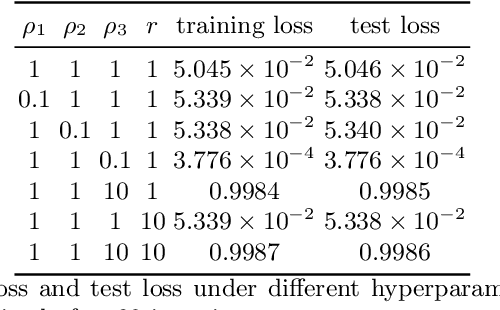
It is hard to train Recurrent Neural Network (RNN) with stable convergence and avoid gradient vanishing and exploding, as the weights in the recurrent unit are repeated from iteration to iteration. Moreover, RNN is sensitive to the initialization of weights and bias, which brings difficulty in the training phase. With the gradient-free feature and immunity to poor conditions, the Alternating Direction Method of Multipliers (ADMM) has become a promising algorithm to train neural networks beyond traditional stochastic gradient algorithms. However, ADMM could not be applied to train RNN directly since the state in the recurrent unit is repetitively updated over timesteps. Therefore, this work builds a new framework named ADMMiRNN upon the unfolded form of RNN to address the above challenges simultaneously and provides novel update rules and theoretical convergence analysis. We explicitly specify key update rules in the iterations of ADMMiRNN with deliberately constructed approximation techniques and solutions to each subproblem instead of vanilla ADMM. Numerical experiments are conducted on MNIST and text classification tasks, where ADMMiRNN achieves convergent results and outperforms compared baselines. Furthermore, ADMMiRNN trains RNN in a more stable way without gradient vanishing or exploding compared to the stochastic gradient algorithms. Source code has been available at https://github.com/TonyTangYu/ADMMiRNN.