 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception of Knowledge Boundary for Large Language Models through Semi-open-ended Question Answering
May 23, 2024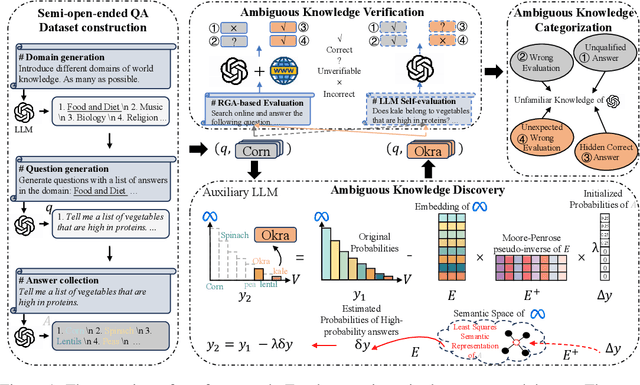
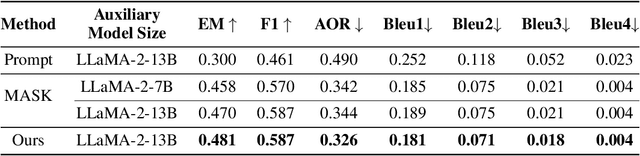
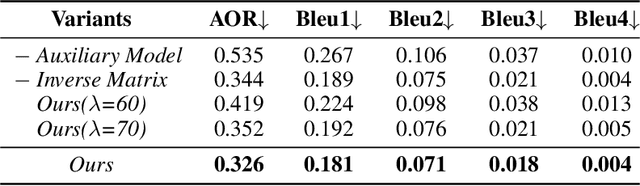
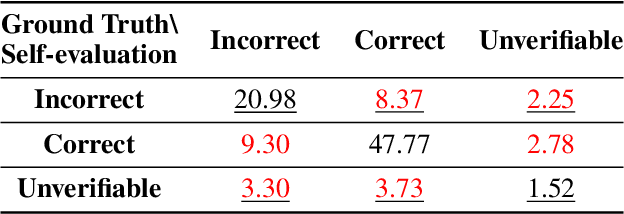
Large Language Models (LLMs) are widely used for knowledge-seeking yet suffer from hallucinations. The knowledge boundary (KB) of an LLM limits its factual understanding, beyond which it may begin to hallucinate. Investigating the perception of LLMs' KB is crucial for detecting hallucinations and LLMs' reliable generation. Current studies perceive LLMs' KB on questions with a concrete answer (close-ended questions) while paying limited attention to semi-open-ended questions (SoeQ) that correspond to many potential answers. Some researchers achieve it by judging whether the question is answerable or not. However, this paradigm is unsuitable for SoeQ, which are usually partially answerable, containing both answerable and ambiguous (unanswerable) answers. Ambiguous answers are essential for knowledge-seeking, but they may go beyond the KB of LLMs. In this paper, we perceive the LLMs' KB with SoeQ by discovering more ambiguous answers. First, we apply an LLM-based approach to construct SoeQ and obtain answers from a target LLM. Unfortunately, the output probabilities of mainstream black-box LLMs are inaccessible to sample for low-probability ambiguous answers. Therefore, we apply an open-sourced auxiliary model to explore ambiguous answers for the target LLM. We calculate the nearest semantic representation for existing answers to estimate their probabilities, with which we reduce the generation probability of high-probability answers to achieve a more effective generation. Finally, we compare the results from the RAG-based evaluation and LLM self-evaluation to categorize four types of ambiguous answers that are beyond the KB of the target LLM. Following our method, we construct a dataset to perceive the KB for GPT-4. We find that GPT-4 performs poorly on SoeQ and is often unaware of its KB. Besides, our auxiliary model, LLaMA-2-13B, is effective in discovering more ambiguous answers.