 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Plain Demos: A Demo-centric Anchoring Paradigm for In-Context Learning in Alzheimer's Disease Detection
Nov 10, 2025Detecting Alzheimer's disease (AD) from narrative transcripts challenges large language models (LLMs): pre-training rarely covers this out-of-distribution task, and all transcript demos describe the same scene, producing highly homogeneous contexts. These factors cripple both the model's built-in task knowledge (\textbf{task cognition}) and its ability to surface subtle, class-discriminative cues (\textbf{contextual perception}). Because cognition is fixed after pre-training, improving in-context learning (ICL) for AD detection hinges on enriching perception through better demonstration (demo) sets. We demonstrate that standard ICL quickly saturates, its demos lack diversity (context width) and fail to convey fine-grained signals (context depth), and that recent task vector (TV) approaches improve broad task adaptation by injecting TV into the LLMs' hidden states (HSs), they are ill-suited for AD detection due to the mismatch of injection granularity, strength and position. To address these bottlenecks, we introduce \textbf{DA4ICL}, a demo-centric anchoring framework that jointly expands context width via \emph{\textbf{Diverse and Contrastive Retrieval}} (DCR) and deepens each demo's signal via \emph{\textbf{Projected Vector Anchoring}} (PVA) at every Transformer layer. Across three AD benchmarks, DA4ICL achieves large, stable gains over both ICL and TV baselines, charting a new paradigm for fine-grained, OOD and low-resource LLM adaptation.
Explicit Knowledge-Guided In-Context Learning for Early Detection of Alzheimer's Disease
Nov 09, 2025Detecting Alzheimer's Disease (AD) from narrative transcripts remains a challenging task for large language models (LLMs), particularly under out-of-distribution (OOD) and data-scarce conditions. While in-context learning (ICL) provides a parameter-efficient alternative to fine-tuning, existing ICL approaches often suffer from task recognition failure, suboptimal demonstration selection, and misalignment between label words and task objectives, issues that are amplified in clinical domains like AD detection. We propose Explicit Knowledge In-Context Learners (EK-ICL), a novel framework that integrates structured explicit knowledge to enhance reasoning stability and task alignment in ICL. EK-ICL incorporates three knowledge components: confidence scores derived from small language models (SLMs) to ground predictions in task-relevant patterns, parsing feature scores to capture structural differences and improve demo selection, and label word replacement to resolve semantic misalignment with LLM priors. In addition, EK-ICL employs a parsing-based retrieval strategy and ensemble prediction to mitigate the effects of semantic homogeneity in AD transcripts. Extensive experiments across three AD datasets demonstrate that EK-ICL significantly outperforms state-of-the-art fine-tuning and ICL baselines. Further analysis reveals that ICL performance in AD detection is highly sensitive to the alignment of label semantics and task-specific context, underscoring the importance of explicit knowledge in clinical reasoning under low-resource conditions.
Precise Zero-Shot Pointwise Ranking with LLMs through Post-Aggregated Global Context Information
Jun 12, 2025Recent advancements have successfully harnessed the power of Large Language Models (LLMs) for zero-shot document ranking, exploring a variety of prompting strategies. Comparative approaches like pairwise and listwise achieve high effectiveness but are computationally intensive and thus less practical for larger-scale applications. Scoring-based pointwise approaches exhibit superior efficiency by independently and simultaneously generating the relevance scores for each candidate document. However, this independence ignores critical comparative insights between documents, resulting in inconsistent scoring and suboptimal performance. In this paper, we aim to improve the effectiveness of pointwise methods while preserving their efficiency through two key innovations: (1) We propose a novel Global-Consistent Comparative Pointwise Ranking (GCCP) strategy that incorporates global reference comparisons between each candidate and an anchor document to generate contrastive relevance scores. We strategically design the anchor document as a query-focused summary of pseudo-relevant candidates, which serves as an effective reference point by capturing the global context for document comparison. (2) These contrastive relevance scores can be efficiently Post-Aggregated with existing pointwise methods, seamlessly integrating essential Global Context information in a training-free manner (PAGC). Extensive experiments on the TREC DL and BEIR benchmark demonstrate that our approach significantly outperforms previous pointwise methods while maintaining comparable efficiency. Our method also achieves competitive performance against comparative methods that require substantially more computational resources. More analyses further validate the efficacy of our anchor construction strategy.
Disentangling Instructive Information from Ranked Multiple Candidates for Multi-Document Scientific Summarization
Apr 16, 2024



Automatically condensing multiple topic-related scientific papers into a succinct and concise summary is referred to as Multi-Document Scientific Summarization (MDSS). Currently, while commonly used abstractive MDSS methods can generate flexible and coherent summaries, the difficulty in handling global information and the lack of guidance during decoding still make it challenging to generate better summaries. To alleviate these two shortcomings, this paper introduces summary candidates into MDSS, utilizing the global information of the document set and additional guidance from the summary candidates to guide the decoding process. Our insights are twofold: Firstly, summary candidates can provide instructive information from both positive and negative perspectives, and secondly, selecting higher-quality candidates from multiple options contributes to producing better summaries. Drawing on the insights, we propose a summary candidates fusion framework -- Disentangling Instructive information from Ranked candidates (DIR) for MDSS. Specifically, DIR first uses a specialized pairwise comparison method towards multiple candidates to pick out those of higher quality. Then DIR disentangles the instructive information of summary candidates into positive and negative latent variables with Conditional Variational Autoencoder. These variables are further incorporated into the decoder to guide generation. We evaluate our approach with three different types of Transformer-based models and three different types of candidates, and consistently observe noticeable performance improvements according to automatic and human evaluation. More analyses further demonstrate the effectiveness of our model in handling global information and enhancing decoding controllability.
Recommending Missed Citations Identified by Reviewers: A New Task, Dataset and Baselines
Mar 04, 2024



Citing comprehensively and appropriately has become a challenging task with the explosive growth of scientific publications. Current citation recommendation systems aim to recommend a list of scientific papers for a given text context or a draft paper. However, none of the existing work focuses on already included citations of full papers, which are imperfect and still have much room for improvement. In the scenario of peer reviewing, it is a common phenomenon that submissions are identified as missing vital citations by reviewers. This may lead to a negative impact on the credibility and validity of the research presented. To help improve citations of full papers, we first define a novel task of Recommending Missed Citations Identified by Reviewers (RMC) and construct a corresponding expert-labeled dataset called CitationR. We conduct an extensive evaluation of several state-of-the-art methods on CitationR. Furthermore, we propose a new framework RMCNet with an Attentive Reference Encoder module mining the relevance between papers, already-made citations, and missed citations. Empirical results prove that RMC is challenging, with the proposed architecture outperforming previous methods in all metrics. We release our dataset and benchmark models to motivate future research on this challenging new task.
Retrieval-augmented GPT-3.5-based Text-to-SQL Framework with Sample-aware Prompting and Dynamic Revision Chain
Jul 11, 2023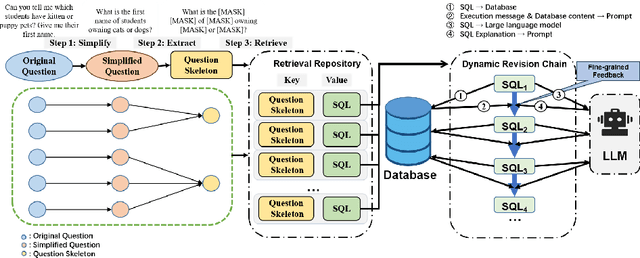
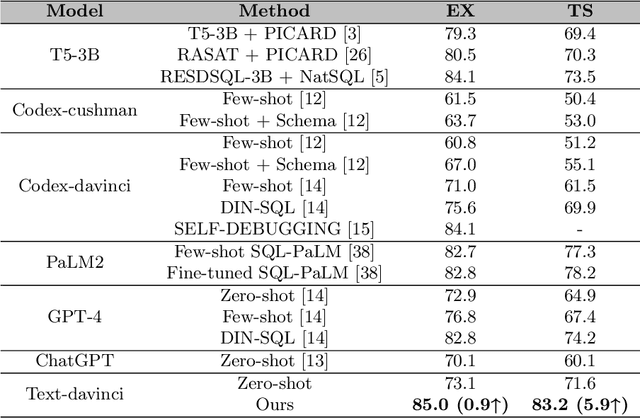


Text-to-SQL aims at generating SQL queries for the given natural language questions and thus helping users to query databases. Prompt learning with large language models (LLMs) has emerged as a recent approach, which designs prompts to lead LLMs to understand the input question and generate the corresponding SQL. However, it faces challenges with strict SQL syntax requirements. Existing work prompts the LLMs with a list of demonstration examples (i.e. question-SQL pairs) to generate SQL, but the fixed prompts can hardly handle the scenario where the semantic gap between the retrieved demonstration and the input question is large. In this paper, we propose a retrieval-augmented prompting method for a LLM-based Text-to-SQL framework, involving sample-aware prompting and a dynamic revision chain. Our approach incorporates sample-aware demonstrations, which include the composition of SQL operators and fine-grained information related to the given question. To retrieve questions sharing similar intents with input questions, we propose two strategies for assisting retrieval. Firstly, we leverage LLMs to simplify the original questions, unifying the syntax and thereby clarifying the users' intentions. To generate executable and accurate SQLs without human intervention, we design a dynamic revision chain which iteratively adapts fine-grained feedback from the previously generated SQL. Experimental results on three Text-to-SQL benchmarks demonstrate the superiority of our method over strong baseline models.
MuDPT: Multi-modal Deep-symphysis Prompt Tuning for Large Pre-trained Vision-Language Models
Jun 20, 2023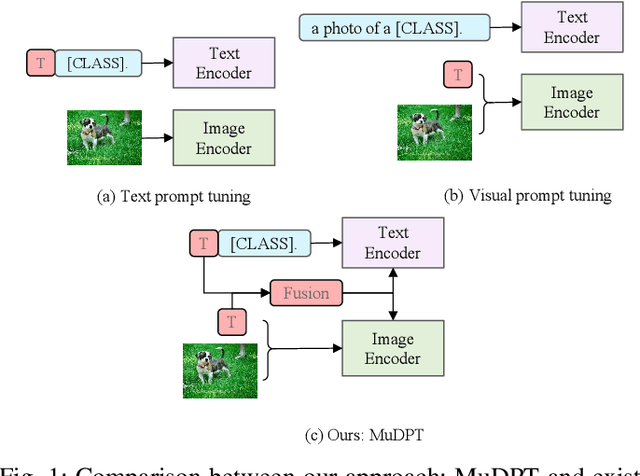
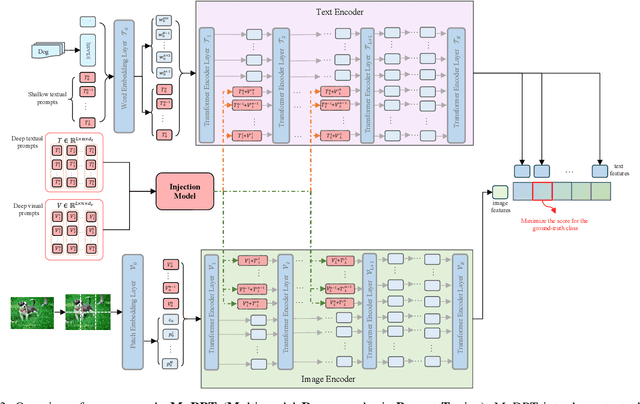
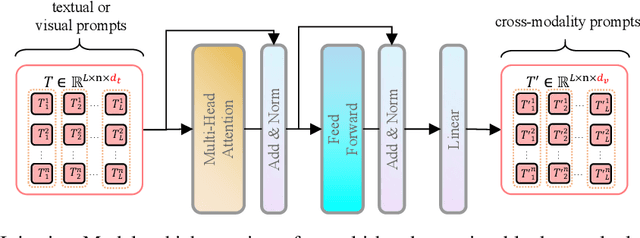
Prompt tuning, like CoOp, has recently shown promising vision recognizing and transfer learning ability on various downstream tasks with the emergence of large pre-trained vision-language models like CLIP. However, we identify that existing uni-modal prompt tuning approaches may result in sub-optimal performance since this uni-modal design breaks the original alignment of textual and visual representations in the pre-trained model. Inspired by the nature of pre-trained vision-language models, we aim to achieve completeness in prompt tuning and propose a novel approach called Multi-modal Deep-symphysis Prompt Tuning, dubbed as MuDPT, which extends independent multi-modal prompt tuning by additionally learning a model-agnostic transformative network to allow deep hierarchical bi-directional prompt fusion. We evaluate the effectiveness of MuDPT on few-shot vision recognition and out-of-domain generalization tasks. Compared with the state-of-the-art methods, MuDPT achieves better recognition and generalization ability with an apparent margin thanks to synergistic alignment of textual and visual representations. Our code is available at: https://github.com/Mechrev0/MuDPT.
Address Matching Based On Hierarchical Information
May 10, 2023There is evidence that address matching plays a crucial role in many areas such as express delivery, online shopping and so on. Address has a hierarchical structure, in contrast to unstructured texts, which can contribute valuable information for address matching. Based on this idea, this paper proposes a novel method to leverage the hierarchical information in deep learning method that not only improves the ability of existing methods to handle irregular address, but also can pay closer attention to the special part of address. Experimental findings demonstrate that the proposed method improves the current approach by 3.2% points.
A Case-Based Reasoning Framework for Adaptive Prompting in Cross-Domain Text-to-SQL
Apr 26, 2023



Recent advancements in Large Language Models (LLMs), such as Codex, ChatGPT and GPT-4 have significantly impacted the AI community, including Text-to-SQL tasks. Some evaluations and analyses on LLMs show their potential to generate SQL queries but they point out poorly designed prompts (e.g. simplistic construction or random sampling) limit LLMs' performance and may cause unnecessary or irrelevant outputs. To address these issues, we propose CBR-ApSQL, a Case-Based Reasoning (CBR)-based framework combined with GPT-3.5 for precise control over case-relevant and case-irrelevant knowledge in Text-to-SQL tasks. We design adaptive prompts for flexibly adjusting inputs for GPT-3.5, which involves (1) adaptively retrieving cases according to the question intention by de-semantizing the input question, and (2) an adaptive fallback mechanism to ensure the informativeness of the prompt, as well as the relevance between cases and the prompt. In the de-semanticization phase, we designed Semantic Domain Relevance Evaluator(SDRE), combined with Poincar\'e detector(mining implicit semantics in hyperbolic space), TextAlign(discovering explicit matches), and Positector (part-of-speech detector). SDRE semantically and syntactically generates in-context exemplar annotations for the new case. On the three cross-domain datasets, our framework outperforms the state-of-the-art(SOTA) model in execution accuracy by 3.7\%, 2.5\%, and 8.2\%, respectively.
Multi-Document Scientific Summarization from a Knowledge Graph-Centric View
Sep 09, 2022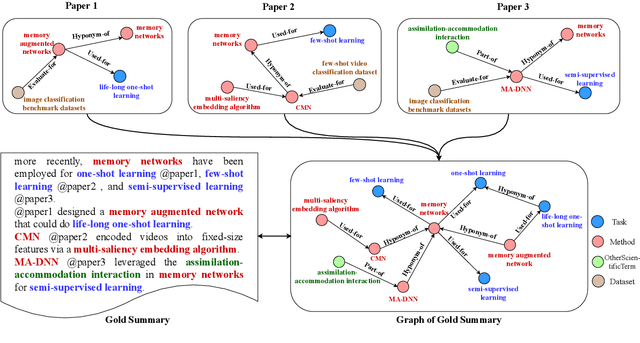

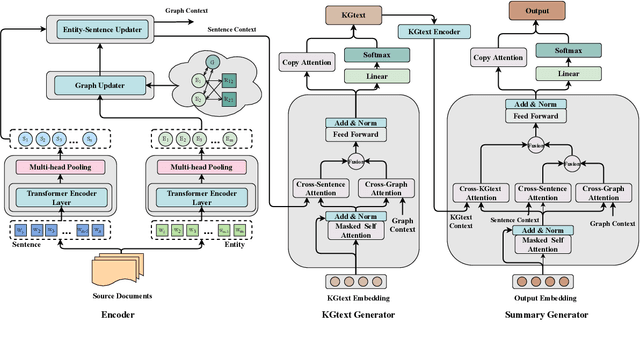

Multi-Document Scientific Summarization (MDSS) aims to produce coherent and concise summaries for clusters of topic-relevant scientific papers. This task requires precise understanding of paper content and accurate modeling of cross-paper relationships. Knowledge graphs convey compact and interpretable structured information for documents, which makes them ideal for content modeling and relationship modeling. In this paper, we present KGSum, an MDSS model centred on knowledge graphs during both the encoding and decoding process. Specifically, in the encoding process, two graph-based modules are proposed to incorporate knowledge graph information into paper encoding, while in the decoding process, we propose a two-stage decoder by first generating knowledge graph information of summary in the form of descriptive sentences, followed by generating the final summary. Empirical results show that the proposed architecture brings substantial improvements over baselines on the Multi-Xscience dataset.