 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-resource Hallucination Detection for Text Generation via Graph-based Contextual Knowledge Triples Modeling
Sep 18, 2024



LLMs obtain remarkable performance but suffer from hallucinations. Most research on detecting hallucination focuses on the questions with short and concrete correct answers that are easy to check the faithfulness. Hallucination detections for text generation with open-ended answers are more challenging. Some researchers use external knowledge to detect hallucinations in generated texts, but external resources for specific scenarios are hard to access. Recent studies on detecting hallucinations in long text without external resources conduct consistency comparison among multiple sampled outputs. To handle long texts, researchers split long texts into multiple facts and individually compare the consistency of each pairs of facts. However, these methods (1) hardly achieve alignment among multiple facts; (2) overlook dependencies between multiple contextual facts. In this paper, we propose a graph-based context-aware (GCA) hallucination detection for text generations, which aligns knowledge facts and considers the dependencies between contextual knowledge triples in consistency comparison. Particularly, to align multiple facts, we conduct a triple-oriented response segmentation to extract multiple knowledge triples. To model dependencies among contextual knowledge triple (facts), we construct contextual triple into a graph and enhance triples' interactions via message passing and aggregating via RGCN. To avoid the omission of knowledge triples in long text, we conduct a LLM-based reverse verification via reconstructing the knowledge triples. Experiments show that our model enhances hallucination detection and excels all baselines.
TFDMNet: A Novel Network Structure Combines the Time Domain and Frequency Domain Features
Jan 29, 2024Convolutional neural network (CNN) has achieved impressive success in computer vision during the past few decades. The image convolution operation helps CNNs to get good performance on image-related tasks. However, it also has high computation complexity and hard to be parallelized. This paper proposes a novel Element-wise Multiplication Layer (EML) to replace convolution layers, which can be trained in the frequency domain. Theoretical analyses show that EMLs lower the computation complexity and easier to be parallelized. Moreover, we introduce a Weight Fixation mechanism to alleviate the problem of over-fitting, and analyze the working behavior of Batch Normalization and Dropout in the frequency domain. To get the balance between the computation complexity and memory usage, we propose a new network structure, namely Time-Frequency Domain Mixture Network (TFDMNet), which combines the advantages of both convolution layers and EMLs. Experimental results imply that TFDMNet achieves good performance on MNIST, CIFAR-10 and ImageNet databases with less number of operations comparing with corresponding CNNs.
Auto-Prox: Training-Free Vision Transformer Architecture Search via Automatic Proxy Discovery
Dec 14, 2023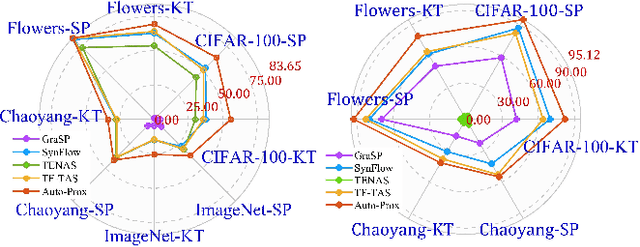
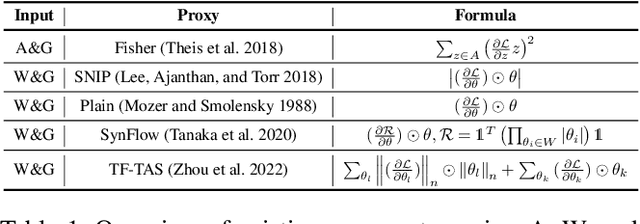
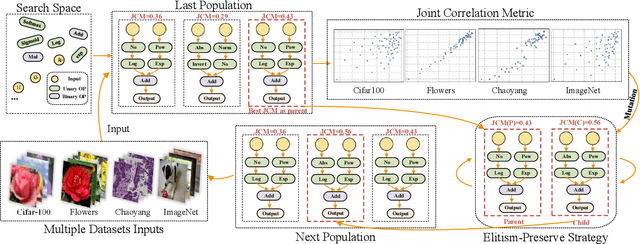
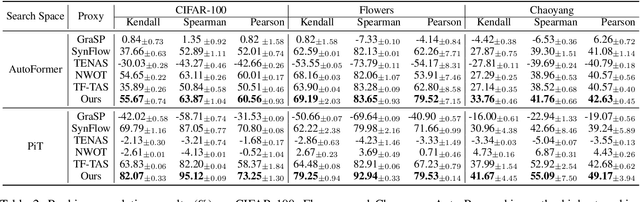
The substantial success of Vision Transformer (ViT) in computer vision tasks is largely attributed to the architecture design. This underscores the necessity of efficient architecture search for designing better ViTs automatically. As training-based architecture search methods are computationally intensive, there is a growing interest in training-free methods that use zero-cost proxies to score ViTs. However, existing training-free approaches require expert knowledge to manually design specific zero-cost proxies. Moreover, these zero-cost proxies exhibit limitations to generalize across diverse domains. In this paper, we introduce Auto-Prox, an automatic proxy discovery framework, to address the problem. First, we build the ViT-Bench-101, which involves different ViT candidates and their actual performance on multiple datasets. Utilizing ViT-Bench-101, we can evaluate zero-cost proxies based on their score-accuracy correlation. Then, we represent zero-cost proxies with computation graphs and organize the zero-cost proxy search space with ViT statistics and primitive operations. To discover generic zero-cost proxies, we propose a joint correlation metric to evolve and mutate different zero-cost proxy candidates. We introduce an elitism-preserve strategy for search efficiency to achieve a better trade-off between exploitation and exploration. Based on the discovered zero-cost proxy, we conduct a ViT architecture search in a training-free manner. Extensive experiments demonstrate that our method generalizes well to different datasets and achieves state-of-the-art results both in ranking correlation and final accuracy. Codes can be found at https://github.com/lilujunai/Auto-Prox-AAAI24.
TVT: Training-Free Vision Transformer Search on Tiny Datasets
Nov 24, 2023



Training-free Vision Transformer (ViT) architecture search is presented to search for a better ViT with zero-cost proxies. While ViTs achieve significant distillation gains from CNN teacher models on small datasets, the current zero-cost proxies in ViTs do not generalize well to the distillation training paradigm according to our experimental observations. In this paper, for the first time, we investigate how to search in a training-free manner with the help of teacher models and devise an effective Training-free ViT (TVT) search framework. Firstly, we observe that the similarity of attention maps between ViT and ConvNet teachers affects distill accuracy notably. Thus, we present a teacher-aware metric conditioned on the feature attention relations between teacher and student. Additionally, TVT employs the L2-Norm of the student's weights as the student-capability metric to improve ranking consistency. Finally, TVT searches for the best ViT for distilling with ConvNet teachers via our teacher-aware metric and student-capability metric, resulting in impressive gains in efficiency and effectiveness. Extensive experiments on various tiny datasets and search spaces show that our TVT outperforms state-of-the-art training-free search methods. The code will be released.
EMQ: Evolving Training-free Proxies for Automated Mixed Precision Quantization
Jul 20, 2023



Mixed-Precision Quantization~(MQ) can achieve a competitive accuracy-complexity trade-off for models. Conventional training-based search methods require time-consuming candidate training to search optimized per-layer bit-width configurations in MQ. Recently, some training-free approaches have presented various MQ proxies and significantly improve search efficiency. However, the correlation between these proxies and quantization accuracy is poorly understood. To address the gap, we first build the MQ-Bench-101, which involves different bit configurations and quantization results. Then, we observe that the existing training-free proxies perform weak correlations on the MQ-Bench-101. To efficiently seek superior proxies, we develop an automatic search of proxies framework for MQ via evolving algorithms. In particular, we devise an elaborate search space involving the existing proxies and perform an evolution search to discover the best correlated MQ proxy. We proposed a diversity-prompting selection strategy and compatibility screening protocol to avoid premature convergence and improve search efficiency. In this way, our Evolving proxies for Mixed-precision Quantization~(EMQ) framework allows the auto-generation of proxies without heavy tuning and expert knowledge. Extensive experiments on ImageNet with various ResNet and MobileNet families demonstrate that our EMQ obtains superior performance than state-of-the-art mixed-precision methods at a significantly reduced cost. The code will be released.
Progressive Meta-Pooling Learning for Lightweight Image Classification Model
Jan 24, 2023



Practical networks for edge devices adopt shallow depth and small convolutional kernels to save memory and computational cost, which leads to a restricted receptive field. Conventional efficient learning methods focus on lightweight convolution designs, ignoring the role of the receptive field in neural network design. In this paper, we propose the Meta-Pooling framework to make the receptive field learnable for a lightweight network, which consists of parameterized pooling-based operations. Specifically, we introduce a parameterized spatial enhancer, which is composed of pooling operations to provide versatile receptive fields for each layer of a lightweight model. Then, we present a Progressive Meta-Pooling Learning (PMPL) strategy for the parameterized spatial enhancer to acquire a suitable receptive field size. The results on the ImageNet dataset demonstrate that MobileNetV2 using Meta-Pooling achieves top1 accuracy of 74.6\%, which outperforms MobileNetV2 by 2.3\%.
RD-NAS: Enhancing One-shot Supernet Ranking Ability via Ranking Distillation from Zero-cost Proxies
Jan 24, 2023



Neural architecture search (NAS) has made tremendous progress in the automatic design of effective neural network structures but suffers from a heavy computational burden. One-shot NAS significantly alleviates the burden through weight sharing and improves computational efficiency. Zero-shot NAS further reduces the cost by predicting the performance of the network from its initial state, which conducts no training. Both methods aim to distinguish between "good" and "bad" architectures, i.e., ranking consistency of predicted and true performance. In this paper, we propose Ranking Distillation one-shot NAS (RD-NAS) to enhance ranking consistency, which utilizes zero-cost proxies as the cheap teacher and adopts the margin ranking loss to distill the ranking knowledge. Specifically, we propose a margin subnet sampler to distill the ranking knowledge from zero-shot NAS to one-shot NAS by introducing Group distance as margin. Our evaluation of the NAS-Bench-201 and ResNet-based search space demonstrates that RD-NAS achieve 10.7\% and 9.65\% improvements in ranking ability, respectively. Our codes are available at https://github.com/pprp/CVPR2022-NAS-competition-Track1-3th-solution
OVO: One-shot Vision Transformer Search with Online distillation
Dec 28, 2022
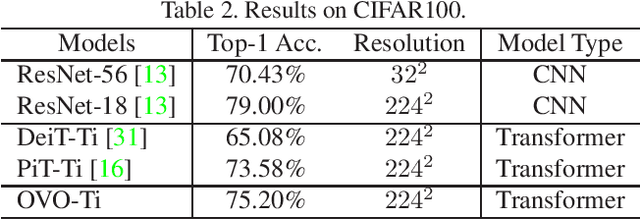
Pure transformers have shown great potential for vision tasks recently. However, their accuracy in small or medium datasets is not satisfactory. Although some existing methods introduce a CNN as a teacher to guide the training process by distillation, the gap between teacher and student networks would lead to sub-optimal performance. In this work, we propose a new One-shot Vision transformer search framework with Online distillation, namely OVO. OVO samples sub-nets for both teacher and student networks for better distillation results. Benefiting from the online distillation, thousands of subnets in the supernet are well-trained without extra finetuning or retraining. In experiments, OVO-Ti achieves 73.32% top-1 accuracy on ImageNet and 75.2% on CIFAR-100, respectively.
ConvFormer: Closing the Gap Between CNN and Vision Transformers
Sep 22, 2022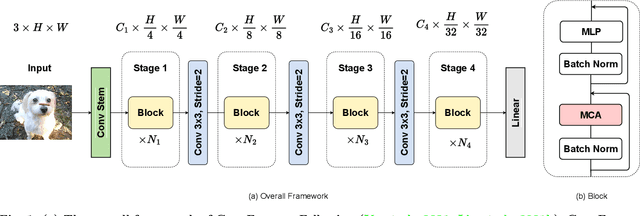
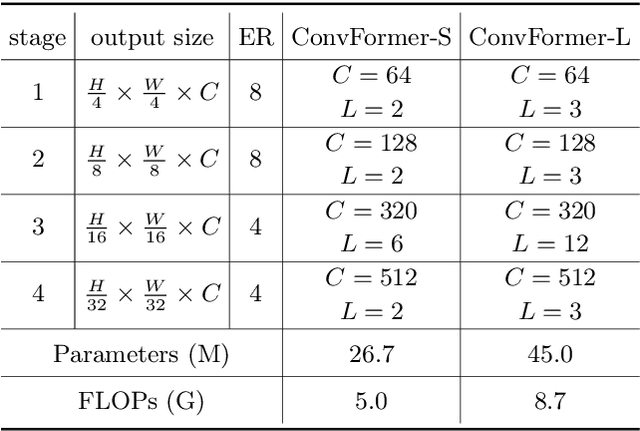
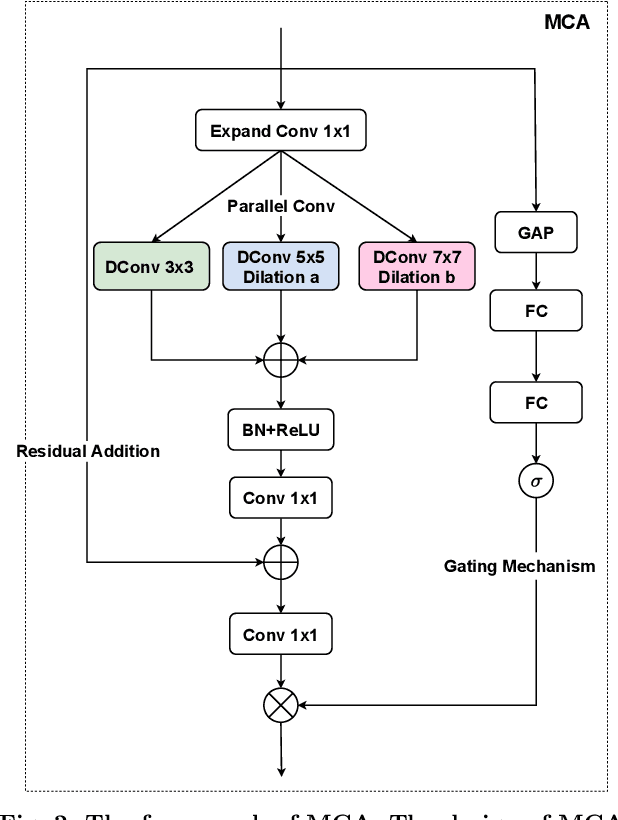
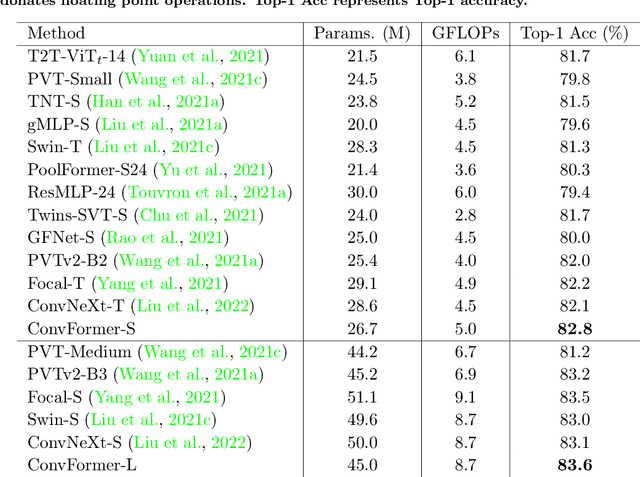
Vision transformers have shown excellent performance in computer vision tasks. However, the computation cost of their (local) self-attention mechanism is expensive. Comparatively, CNN is more efficient with built-in inductive bias. Recent works show that CNN is promising to compete with vision transformers by learning their architecture design and training protocols. Nevertheless, existing methods either ignore multi-level features or lack dynamic prosperity, leading to sub-optimal performance. In this paper, we propose a novel attention mechanism named MCA, which captures different patterns of input images by multiple kernel sizes and enables input-adaptive weights with a gating mechanism. Based on MCA, we present a neural network named ConvFormer. ConvFormer adopts the general architecture of vision transformers, while replacing the (local) self-attention mechanism with our proposed MCA. Extensive experimental results demonstrated that ConvFormer achieves state-of-the-art performance on ImageNet classification, which outperforms similar-sized vision transformers(ViTs) and convolutional neural networks (CNNs). Moreover, for object detection on COCO and semantic segmentation tasks on ADE20K, ConvFormer also shows excellent performance compared with recently advanced methods. Code and models will be available.
Prior-Guided One-shot Neural Architecture Search
Jun 27, 2022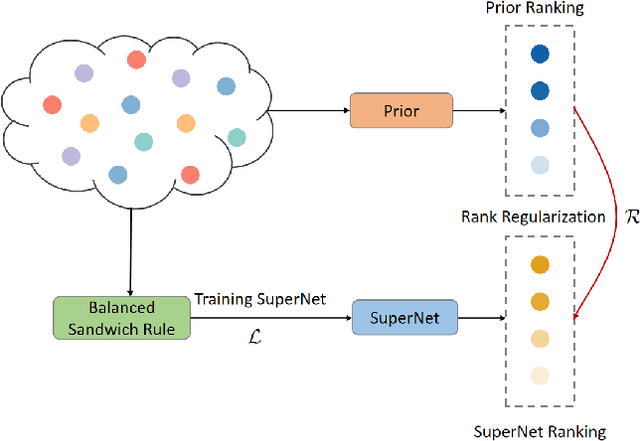
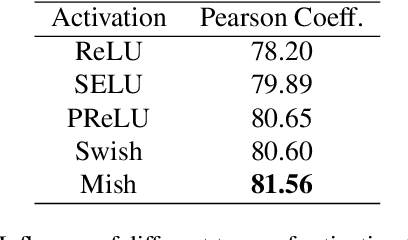
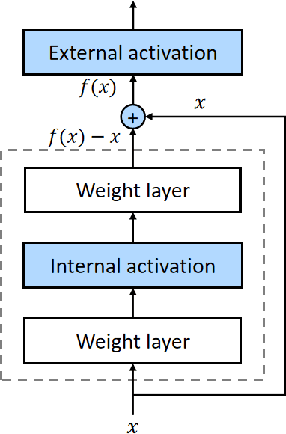

Neural architecture search methods seek optimal candidates with efficient weight-sharing supernet training. However, recent studies indicate poor ranking consistency about the performance between stand-alone architectures and shared-weight networks. In this paper, we present Prior-Guided One-shot NAS (PGONAS) to strengthen the ranking correlation of supernets. Specifically, we first explore the effect of activation functions and propose a balanced sampling strategy based on the Sandwich Rule to alleviate weight coupling in the supernet. Then, FLOPs and Zen-Score are adopted to guide the training of supernet with ranking correlation loss. Our PGONAS ranks 3rd place in the supernet Track Track of CVPR2022 Second lightweight NAS challenge. Code is available in https://github.com/pprp/CVPR2022-NAS?competition-Track1-3th-solution.