 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOVO: One-shot Vision Transformer Search with Online distillation
Paper and Code
Dec 28, 2022
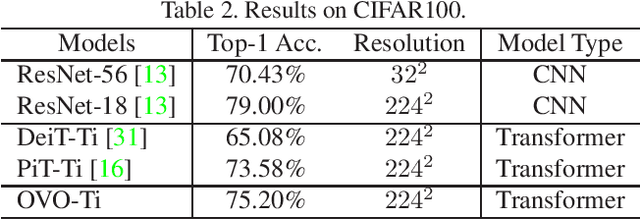
Pure transformers have shown great potential for vision tasks recently. However, their accuracy in small or medium datasets is not satisfactory. Although some existing methods introduce a CNN as a teacher to guide the training process by distillation, the gap between teacher and student networks would lead to sub-optimal performance. In this work, we propose a new One-shot Vision transformer search framework with Online distillation, namely OVO. OVO samples sub-nets for both teacher and student networks for better distillation results. Benefiting from the online distillation, thousands of subnets in the supernet are well-trained without extra finetuning or retraining. In experiments, OVO-Ti achieves 73.32% top-1 accuracy on ImageNet and 75.2% on CIFAR-100, respectively.