 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvFormer: Closing the Gap Between CNN and Vision Transformers
Paper and Code
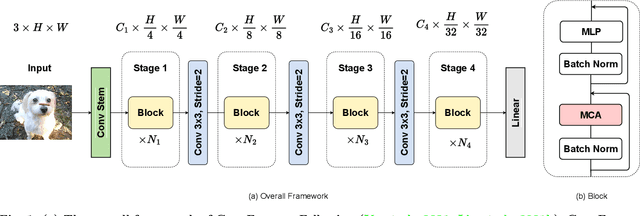
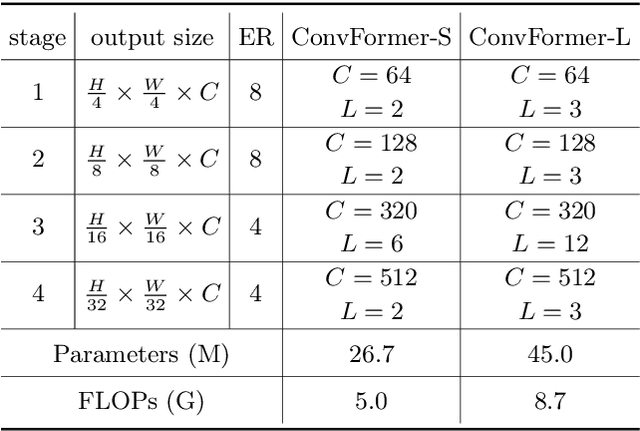
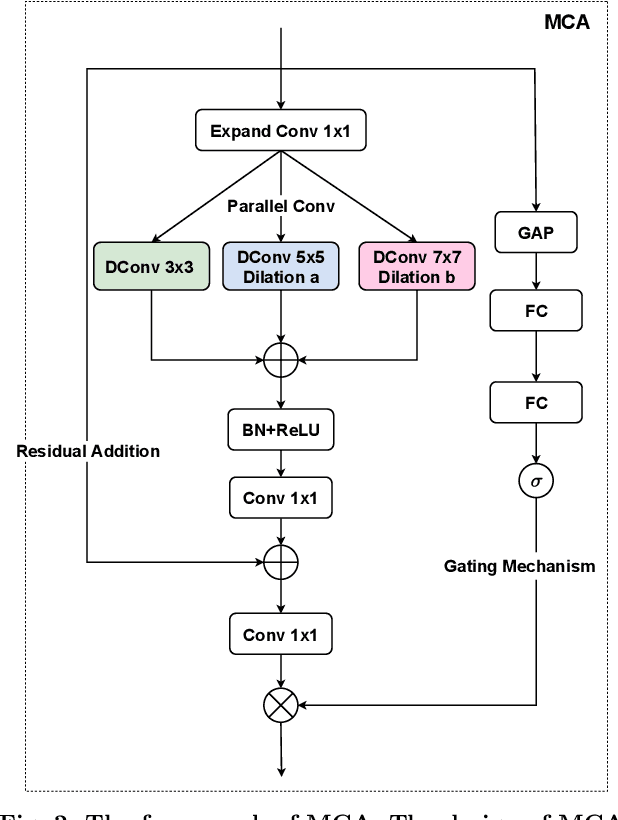
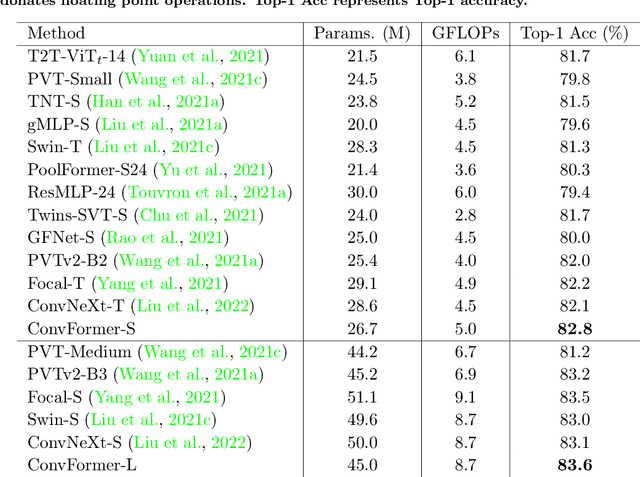
Vision transformers have shown excellent performance in computer vision tasks. However, the computation cost of their (local) self-attention mechanism is expensive. Comparatively, CNN is more efficient with built-in inductive bias. Recent works show that CNN is promising to compete with vision transformers by learning their architecture design and training protocols. Nevertheless, existing methods either ignore multi-level features or lack dynamic prosperity, leading to sub-optimal performance. In this paper, we propose a novel attention mechanism named MCA, which captures different patterns of input images by multiple kernel sizes and enables input-adaptive weights with a gating mechanism. Based on MCA, we present a neural network named ConvFormer. ConvFormer adopts the general architecture of vision transformers, while replacing the (local) self-attention mechanism with our proposed MCA. Extensive experimental results demonstrated that ConvFormer achieves state-of-the-art performance on ImageNet classification, which outperforms similar-sized vision transformers(ViTs) and convolutional neural networks (CNNs). Moreover, for object detection on COCO and semantic segmentation tasks on ADE20K, ConvFormer also shows excellent performance compared with recently advanced methods. Code and models will be available.