 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWSC: Shared Weight for Similar Channel in LLM
Jan 15, 2025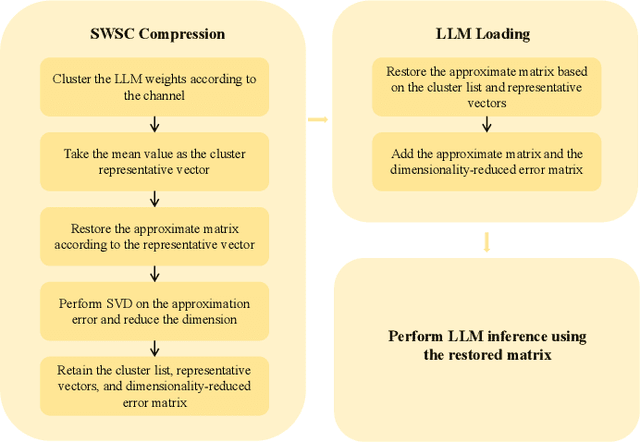
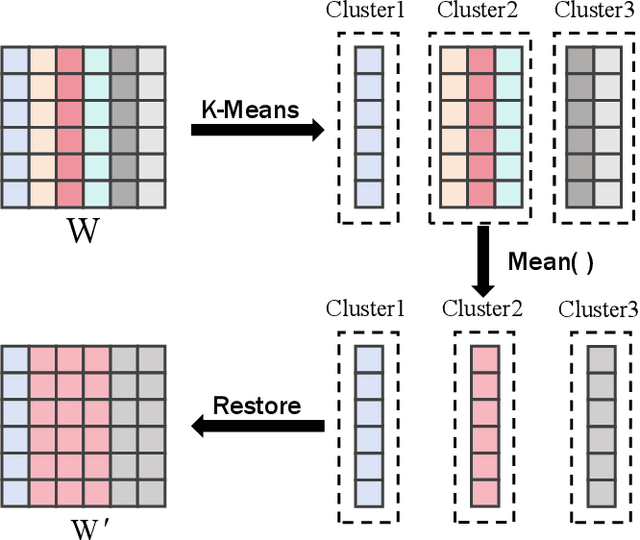
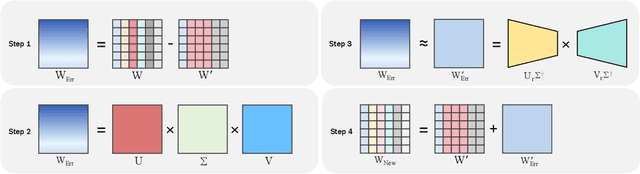
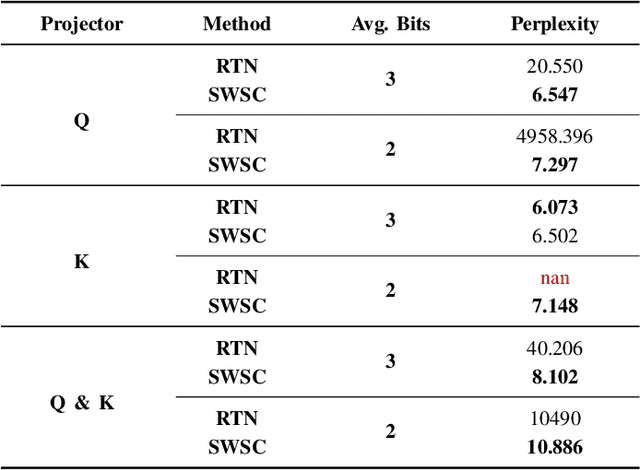
Large language models (LLMs) have spurred development in multiple industries. However, the growing number of their parameters brings substantial storage and computing burdens, making it essential to explore model compression techniques for parameter reduction and easier deployment. We propose SWSC, an LLM compression method based on the concept of Shared Weight for Similar Channel. It uses the K-Means clustering algorithm to cluster model weights channel-by-channel, generating clusters with highly similar vectors within each. A representative vector from each cluster is selected to approximately replace all vectors in the cluster, significantly reducing the number of model weight parameters. However, approximate restoration will inevitably cause damage to the performance of the model. To tackle this issue, we perform singular value decomposition on the weight error values before and after compression and retain the larger singular values and their corresponding singular vectors to compensate for the accuracy. The experimental results show that our method can effectively ensure the performance of the compressed LLM even under low-precision conditions.
LSAQ: Layer-Specific Adaptive Quantization for Large Language Model Deployment
Dec 24, 2024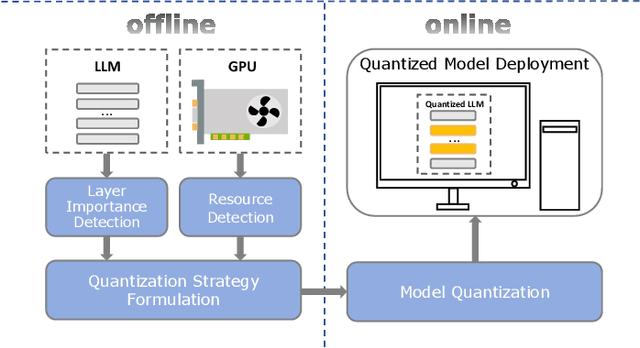
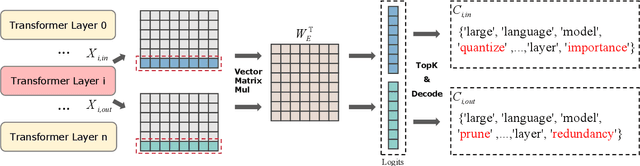
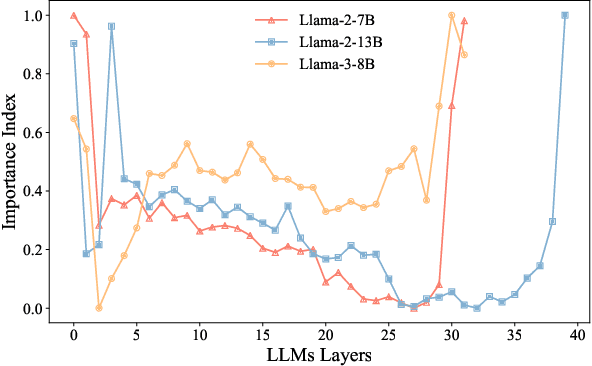
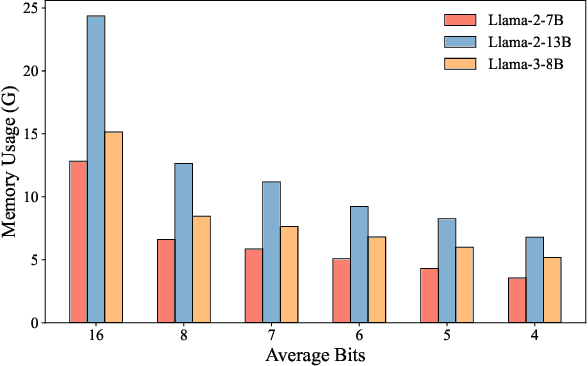
As large language models (LLMs) demonstrate exceptional performance across various domains, the deployment of these models on edge devices has emerged as a new trend. Quantization techniques, which reduce the size and memory footprint of LLMs, are effective for enabling deployment on resource-constrained edge devices. However, existing one-size-fits-all quantization methods often fail to dynamically adjust the memory consumption of LLMs based on specific hardware characteristics and usage scenarios. To address this limitation, we propose LSAQ (Layer-Specific Adaptive Quantization), a system for adaptive quantization and dynamic deployment of LLMs based on layer importance. LSAQ evaluates layer importance by constructing top-k token sets from the inputs and outputs of each layer and calculating their Jaccard coefficient. Using this evaluation, the system adaptively adjusts quantization strategies in real time according to the resource availability of edge devices, assigning different precision levels to layers of varying importance. This approach significantly reduces the storage requirements of LLMs while maintaining model performance, enabling efficient deployment across diverse hardware platforms and usage scenarios.