 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to Basics: Revisiting ASR in the Age of Voice Agents
Mar 26, 2026Automatic speech recognition (ASR) systems have achieved near-human accuracy on curated benchmarks, yet still fail in real-world voice agents under conditions that current evaluations do not systematically cover. Without diagnostic tools that isolate specific failure factors, practitioners cannot anticipate which conditions, in which languages, will cause what degree of degradation. We introduce WildASR, a multilingual (four-language) diagnostic benchmark sourced entirely from real human speech that factorizes ASR robustness along three axes: environmental degradation, demographic shift, and linguistic diversity. Evaluating seven widely used ASR systems, we find severe and uneven performance degradation, and model robustness does not transfer across languages or conditions. Critically, models often hallucinate plausible but unspoken content under partial or degraded inputs, creating concrete safety risks for downstream agent behavior. Our results demonstrate that targeted, factor-isolated evaluation is essential for understanding and improving ASR reliability in production systems. Besides the benchmark itself, we also present three analytical tools that practitioners can use to guide deployment decisions.
Bridging Graph Structure and Knowledge-Guided Editing for Interpretable Temporal Knowledge Graph Reasoning
Jan 29, 2026Temporal knowledge graph reasoning (TKGR) aims to predict future events by inferring missing entities with dynamic knowledge structures. Existing LLM-based reasoning methods prioritize contextual over structural relations, struggling to extract relevant subgraphs from dynamic graphs. This limits structural information understanding, leading to unstructured, hallucination-prone inferences especially with temporal inconsistencies. To address this problem, we propose IGETR (Integration of Graph and Editing-enhanced Temporal Reasoning), a hybrid reasoning framework that combines the structured temporal modeling capabilities of Graph Neural Networks (GNNs) with the contextual understanding of LLMs. IGETR operates through a three-stage pipeline. The first stage aims to ground the reasoning process in the actual data by identifying structurally and temporally coherent candidate paths through a temporal GNN, ensuring that inference starts from reliable graph-based evidence. The second stage introduces LLM-guided path editing to address logical and semantic inconsistencies, leveraging external knowledge to refine and enhance the initial paths. The final stage focuses on integrating the refined reasoning paths to produce predictions that are both accurate and interpretable. Experiments on standard TKG benchmarks show that IGETR achieves state-of-the-art performance, outperforming strong baselines with relative improvements of up to 5.6% on Hits@1 and 8.1% on Hits@3 on the challenging ICEWS datasets. Additionally, we execute ablation studies and additional analyses confirm the effectiveness of each component.
StructEval: Benchmarking LLMs' Capabilities to Generate Structural Outputs
May 26, 2025
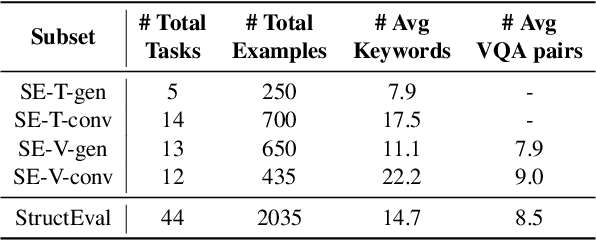
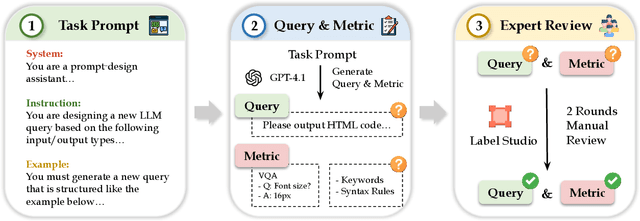

As Large Language Models (LLMs) become integral to software development workflows, their ability to generate structured outputs has become critically important. We introduce StructEval, a comprehensive benchmark for evaluating LLMs' capabilities in producing both non-renderable (JSON, YAML, CSV) and renderable (HTML, React, SVG) structured formats. Unlike prior benchmarks, StructEval systematically evaluates structural fidelity across diverse formats through two paradigms: 1) generation tasks, producing structured output from natural language prompts, and 2) conversion tasks, translating between structured formats. Our benchmark encompasses 18 formats and 44 types of task, with novel metrics for format adherence and structural correctness. Results reveal significant performance gaps, even state-of-the-art models like o1-mini achieve only 75.58 average score, with open-source alternatives lagging approximately 10 points behind. We find generation tasks more challenging than conversion tasks, and producing correct visual content more difficult than generating text-only structures.
VideoEval-Pro: Robust and Realistic Long Video Understanding Evaluation
May 20, 2025Large multimodal models (LMMs) have recently emerged as a powerful tool for long video understanding (LVU), prompting the development of standardized LVU benchmarks to evaluate their performance. However, our investigation reveals a rather sober lesson for existing LVU benchmarks. First, most existing benchmarks rely heavily on multiple-choice questions (MCQs), whose evaluation results are inflated due to the possibility of guessing the correct answer; Second, a significant portion of questions in these benchmarks have strong priors to allow models to answer directly without even reading the input video. For example, Gemini-1.5-Pro can achieve over 50\% accuracy given a random frame from a long video on Video-MME. We also observe that increasing the number of frames does not necessarily lead to improvement on existing benchmarks, which is counterintuitive. As a result, the validity and robustness of current LVU benchmarks are undermined, impeding a faithful assessment of LMMs' long-video understanding capability. To tackle this problem, we propose VideoEval-Pro, a realistic LVU benchmark containing questions with open-ended short-answer, which truly require understanding the entire video. VideoEval-Pro assesses both segment-level and full-video understanding through perception and reasoning tasks. By evaluating 21 proprietary and open-source video LMMs, we conclude the following findings: (1) video LMMs show drastic performance ($>$25\%) drops on open-ended questions compared with MCQs; (2) surprisingly, higher MCQ scores do not lead to higher open-ended scores on VideoEval-Pro; (3) compared to other MCQ benchmarks, VideoEval-Pro benefits more from increasing the number of input frames. Our results show that VideoEval-Pro offers a more realistic and reliable measure of long video understanding, providing a clearer view of progress in this domain.
Vamba: Understanding Hour-Long Videos with Hybrid Mamba-Transformers
Mar 14, 2025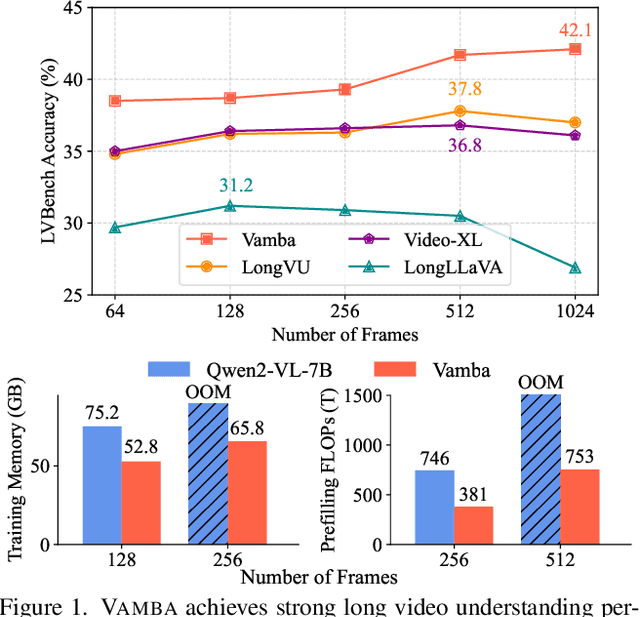
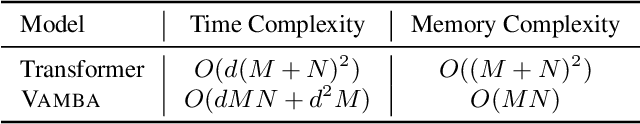
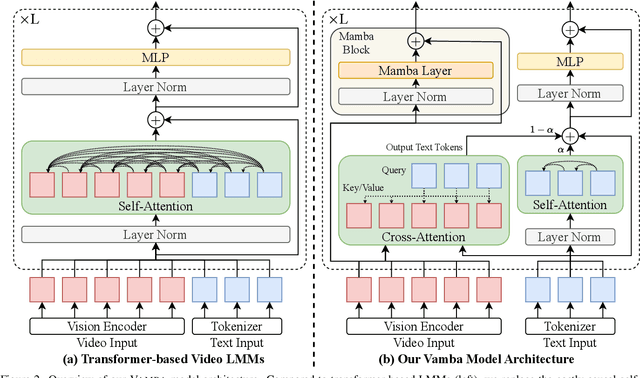
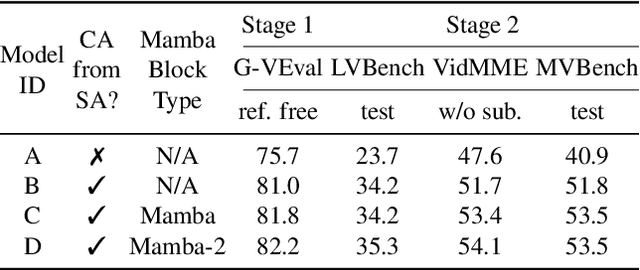
State-of-the-art transformer-based large multimodal models (LMMs) struggle to handle hour-long video inputs due to the quadratic complexity of the causal self-attention operations, leading to high computational costs during training and inference. Existing token compression-based methods reduce the number of video tokens but often incur information loss and remain inefficient for extremely long sequences. In this paper, we explore an orthogonal direction to build a hybrid Mamba-Transformer model (VAMBA) that employs Mamba-2 blocks to encode video tokens with linear complexity. Without any token reduction, VAMBA can encode more than 1024 frames (640$\times$360) on a single GPU, while transformer-based models can only encode 256 frames. On long video input, VAMBA achieves at least 50% reduction in GPU memory usage during training and inference, and nearly doubles the speed per training step compared to transformer-based LMMs. Our experimental results demonstrate that VAMBA improves accuracy by 4.3% on the challenging hour-long video understanding benchmark LVBench over prior efficient video LMMs, and maintains strong performance on a broad spectrum of long and short video understanding tasks.
EPO: Explicit Policy Optimization for Strategic Reasoning in LLMs via Reinforcement Learning
Feb 18, 2025
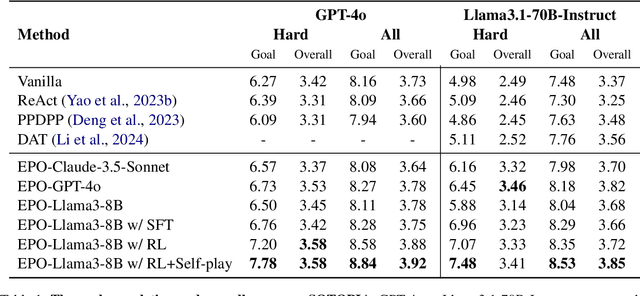
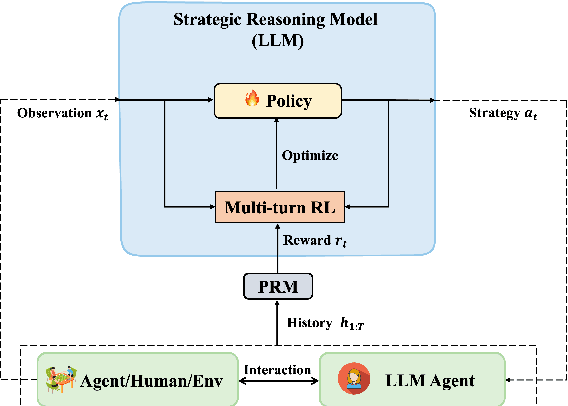
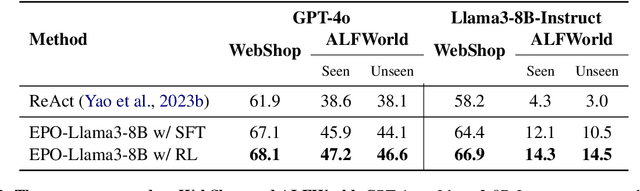
Large Language Models (LLMs) have shown impressive reasoning capabilities in well-defined problems with clear solutions, such as mathematics and coding. However, they still struggle with complex real-world scenarios like business negotiations, which require strategic reasoning-an ability to navigate dynamic environments and align long-term goals amidst uncertainty. Existing methods for strategic reasoning face challenges in adaptability, scalability, and transferring strategies to new contexts. To address these issues, we propose explicit policy optimization (EPO) for strategic reasoning, featuring an LLM that provides strategies in open-ended action space and can be plugged into arbitrary LLM agents to motivate goal-directed behavior. To improve adaptability and policy transferability, we train the strategic reasoning model via multi-turn reinforcement learning (RL) using process rewards and iterative self-play, without supervised fine-tuning (SFT) as a preliminary step. Experiments across social and physical domains demonstrate EPO's ability of long-term goal alignment through enhanced strategic reasoning, achieving state-of-the-art performance on social dialogue and web navigation tasks. Our findings reveal various collaborative reasoning mechanisms emergent in EPO and its effectiveness in generating novel strategies, underscoring its potential for strategic reasoning in real-world applications.
SDPO: Segment-Level Direct Preference Optimization for Social Agents
Jan 03, 2025



Social agents powered by large language models (LLMs) can simulate human social behaviors but fall short in handling complex goal-oriented social dialogues. Direct Preference Optimization (DPO) has proven effective in aligning LLM behavior with human preferences across a variety of agent tasks. Existing DPO-based approaches for multi-turn interactions are divided into turn-level and session-level methods. The turn-level method is overly fine-grained, focusing exclusively on individual turns, while session-level methods are too coarse-grained, often introducing training noise. To address these limitations, we propose Segment-Level Direct Preference Optimization (SDPO), which focuses on specific key segments within interactions to optimize multi-turn agent behavior while minimizing training noise. Evaluations on the SOTOPIA benchmark demonstrate that SDPO-tuned agents consistently outperform both existing DPO-based methods and proprietary LLMs like GPT-4o, underscoring SDPO's potential to advance the social intelligence of LLM-based agents. We release our code and data at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/SDPO.
FlowBench: Revisiting and Benchmarking Workflow-Guided Planning for LLM-based Agents
Jun 21, 2024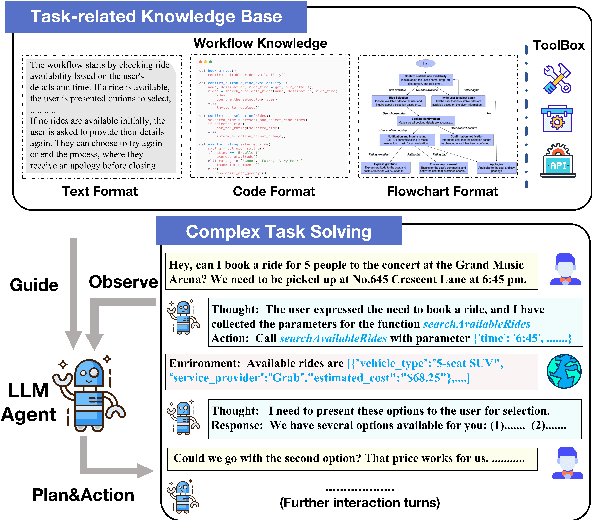

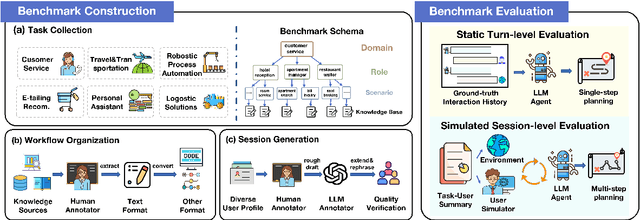
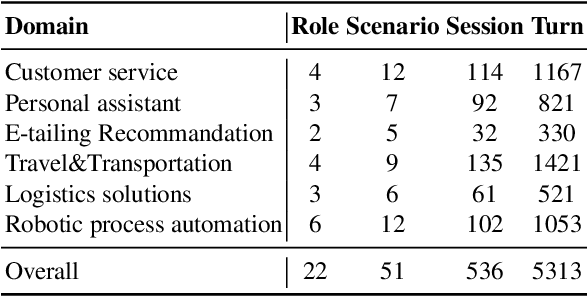
LLM-based agents have emerged as promising tools, which are crafted to fulfill complex tasks by iterative planning and action. However, these agents are susceptible to undesired planning hallucinations when lacking specific knowledge for expertise-intensive tasks. To address this, preliminary attempts are made to enhance planning reliability by incorporating external workflow-related knowledge. Despite the promise, such infused knowledge is mostly disorganized and diverse in formats, lacking rigorous formalization and comprehensive comparisons. Motivated by this, we formalize different formats of workflow knowledge and present FlowBench, the first benchmark for workflow-guided planning. FlowBench covers 51 different scenarios from 6 domains, with knowledge presented in diverse formats. To assess different LLMs on FlowBench, we design a multi-tiered evaluation framework. We evaluate the efficacy of workflow knowledge across multiple formats, and the results indicate that current LLM agents need considerable improvements for satisfactory planning. We hope that our challenging benchmark can pave the way for future agent planning research.
PTA: Enhancing Multimodal Sentiment Analysis through Pipelined Prediction and Translation-based Alignment
May 23, 2024
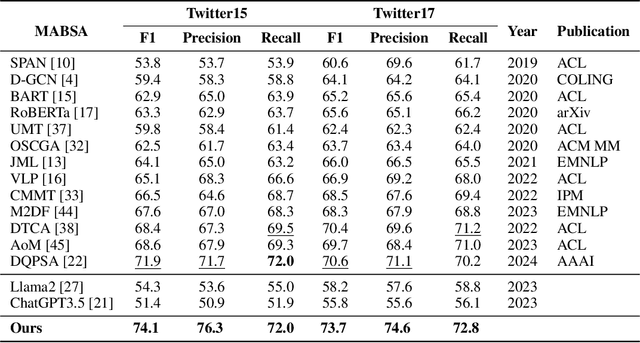


Multimodal aspect-based sentiment analysis (MABSA) aims to understand opinions in a granular manner, advancing human-computer interaction and other fields. Traditionally, MABSA methods use a joint prediction approach to identify aspects and sentiments simultaneously. However, we argue that joint models are not always superior. Our analysis shows that joint models struggle to align relevant text tokens with image patches, leading to misalignment and ineffective image utilization. In contrast, a pipeline framework first identifies aspects through MATE (Multimodal Aspect Term Extraction) and then aligns these aspects with image patches for sentiment classification (MASC: Multimodal Aspect-Oriented Sentiment Classification). This method is better suited for multimodal scenarios where effective image use is crucial. We present three key observations: (a) MATE and MASC have different feature requirements, with MATE focusing on token-level features and MASC on sequence-level features; (b) the aspect identified by MATE is crucial for effective image utilization; and (c) images play a trivial role in previous MABSA methods due to high noise. Based on these observations, we propose a pipeline framework that first predicts the aspect and then uses translation-based alignment (TBA) to enhance multimodal semantic consistency for better image utilization. Our method achieves state-of-the-art (SOTA) performance on widely used MABSA datasets Twitter-15 and Twitter-17. This demonstrates the effectiveness of the pipeline approach and its potential to provide valuable insights for future MABSA research. For reproducibility, the code and checkpoint will be released.
Self-Explanation Prompting Improves Dialogue Understanding in Large Language Models
Sep 22, 2023

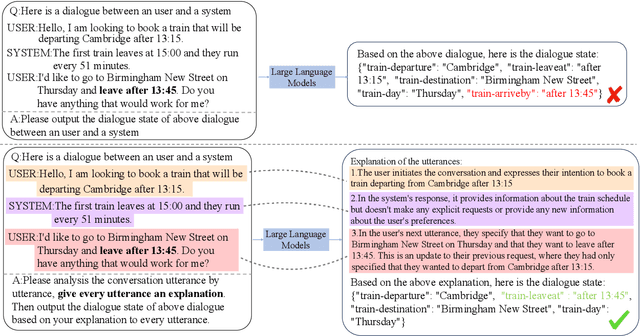

Task-oriented dialogue (TOD) systems facilitate users in executing various activities via multi-turn dialogues, but Large Language Models (LLMs) often struggle to comprehend these intricate contexts. In this study, we propose a novel "Self-Explanation" prompting strategy to enhance the comprehension abilities of LLMs in multi-turn dialogues. This task-agnostic approach requires the model to analyze each dialogue utterance before task execution, thereby improving performance across various dialogue-centric tasks. Experimental results from six benchmark datasets confirm that our method consistently outperforms other zero-shot prompts and matches or exceeds the efficacy of few-shot prompts, demonstrating its potential as a powerful tool in enhancing LLMs' comprehension in complex dialogue tasks.