 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePTA: Enhancing Multimodal Sentiment Analysis through Pipelined Prediction and Translation-based Alignment
Paper and Code

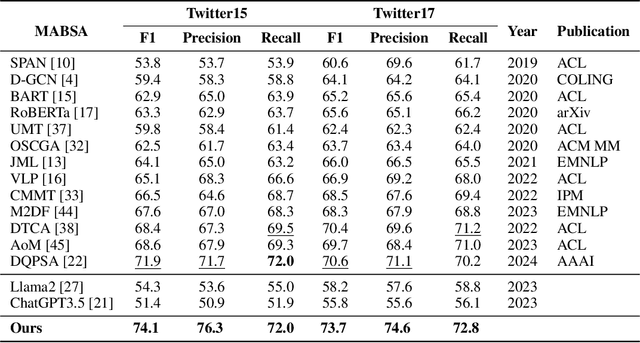


Multimodal aspect-based sentiment analysis (MABSA) aims to understand opinions in a granular manner, advancing human-computer interaction and other fields. Traditionally, MABSA methods use a joint prediction approach to identify aspects and sentiments simultaneously. However, we argue that joint models are not always superior. Our analysis shows that joint models struggle to align relevant text tokens with image patches, leading to misalignment and ineffective image utilization. In contrast, a pipeline framework first identifies aspects through MATE (Multimodal Aspect Term Extraction) and then aligns these aspects with image patches for sentiment classification (MASC: Multimodal Aspect-Oriented Sentiment Classification). This method is better suited for multimodal scenarios where effective image use is crucial. We present three key observations: (a) MATE and MASC have different feature requirements, with MATE focusing on token-level features and MASC on sequence-level features; (b) the aspect identified by MATE is crucial for effective image utilization; and (c) images play a trivial role in previous MABSA methods due to high noise. Based on these observations, we propose a pipeline framework that first predicts the aspect and then uses translation-based alignment (TBA) to enhance multimodal semantic consistency for better image utilization. Our method achieves state-of-the-art (SOTA) performance on widely used MABSA datasets Twitter-15 and Twitter-17. This demonstrates the effectiveness of the pipeline approach and its potential to provide valuable insights for future MABSA research. For reproducibility, the code and checkpoint will be released.