 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRQ-GMM: Residual Quantized Gaussian Mixture Model for Multimodal Semantic Discretization in CTR Prediction
Feb 13, 2026Multimodal content is crucial for click-through rate (CTR) prediction. However, directly incorporating continuous embeddings from pre-trained models into CTR models yields suboptimal results due to misaligned optimization objectives and convergence speed inconsistency during joint training. Discretizing embeddings into semantic IDs before feeding them into CTR models offers a more effective solution, yet existing methods suffer from limited codebook utilization, reconstruction accuracy, and semantic discriminability. We propose RQ-GMM (Residual Quantized Gaussian Mixture Model), which introduces probabilistic modeling to better capture the statistical structure of multimodal embedding spaces. Through Gaussian Mixture Models combined with residual quantization, RQ-GMM achieves superior codebook utilization and reconstruction accuracy. Experiments on public datasets and online A/B tests on a large-scale short-video platform serving hundreds of millions of users demonstrate substantial improvements: RQ-GMM yields a 1.502% gain in Advertiser Value over strong baselines. The method has been fully deployed, serving daily recommendations for hundreds of millions of users.
Distribution-Aware End-to-End Embedding for Streaming Numerical Features in Click-Through Rate Prediction
Feb 03, 2026This paper explores effective numerical feature embedding for Click-Through Rate prediction in streaming environments. Conventional static binning methods rely on offline statistics of numerical distributions; however, this inherently two-stage process often triggers semantic drift during bin boundary updates. While neural embedding methods enable end-to-end learning, they often discard explicit distributional information. Integrating such information end-to-end is challenging because streaming features often violate the i.i.d. assumption, precluding unbiased estimation of the population distribution via the expectation of order statistics. Furthermore, the critical context dependency of numerical distributions is often neglected. To this end, we propose DAES, an end-to-end framework designed to tackle numerical feature embedding in streaming training scenarios by integrating distributional information with an adaptive modulation mechanism. Specifically, we introduce an efficient reservoir-sampling-based distribution estimation method and two field-aware distribution modulation strategies to capture streaming distributions and field-dependent semantics. DAES significantly outperforms existing approaches as demonstrated by extensive offline and online experiments and has been fully deployed on a leading short-video platform with hundreds of millions of daily active users.
Model Editing for LLMs4Code: How Far are We?
Nov 11, 2024



Large Language Models for Code (LLMs4Code) have been found to exhibit outstanding performance in the software engineering domain, especially the remarkable performance in coding tasks. However, even the most advanced LLMs4Code can inevitably contain incorrect or outdated code knowledge. Due to the high cost of training LLMs4Code, it is impractical to re-train the models for fixing these problematic code knowledge. Model editing is a new technical field for effectively and efficiently correcting erroneous knowledge in LLMs, where various model editing techniques and benchmarks have been proposed recently. Despite that, a comprehensive study that thoroughly compares and analyzes the performance of the state-of-the-art model editing techniques for adapting the knowledge within LLMs4Code across various code-related tasks is notably absent. To bridge this gap, we perform the first systematic study on applying state-of-the-art model editing approaches to repair the inaccuracy of LLMs4Code. To that end, we introduce a benchmark named CLMEEval, which consists of two datasets, i.e., CoNaLa-Edit (CNLE) with 21K+ code generation samples and CodeSearchNet-Edit (CSNE) with 16K+ code summarization samples. With the help of CLMEEval, we evaluate six advanced model editing techniques on three LLMs4Code: CodeLlama (7B), CodeQwen1.5 (7B), and Stable-Code (3B). Our findings include that the external memorization-based GRACE approach achieves the best knowledge editing effectiveness and specificity (the editing does not influence untargeted knowledge), while generalization (whether the editing can generalize to other semantically-identical inputs) is a universal challenge for existing techniques. Furthermore, building on in-depth case analysis, we introduce an enhanced version of GRACE called A-GRACE, which incorporates contrastive learning to better capture the semantics of the inputs.
Long-Term Prediction Accuracy Improvement of Data-Driven Medium-Range Global Weather Forecast
Jun 26, 2024



Long-term stability stands as a crucial requirement in data-driven medium-range global weather forecasting. Spectral bias is recognized as the primary contributor to instabilities, as data-driven methods difficult to learn small-scale dynamics. In this paper, we reveal that the universal mechanism for these instabilities is not only related to spectral bias but also to distortions brought by processing spherical data using conventional convolution. These distortions lead to a rapid amplification of errors over successive long-term iterations, resulting in a significant decline in forecast accuracy. To address this issue, a universal neural operator called the Spherical Harmonic Neural Operator (SHNO) is introduced to improve long-term iterative forecasts. SHNO uses the spherical harmonic basis to mitigate distortions for spherical data and uses gated residual spectral attention (GRSA) to correct spectral bias caused by spurious correlations across different scales. The effectiveness and merit of the proposed method have been validated through its application for spherical Shallow Water Equations (SWEs) and medium-range global weather forecasting. Our findings highlight the benefits and potential of SHNO to improve the accuracy of long-term prediction.
SWEA: Changing Factual Knowledge in Large Language Models via Subject Word Embedding Altering
Jan 31, 2024Model editing has recently gained widespread attention. Current model editing methods primarily involve modifying model parameters or adding additional modules to the existing model. However, the former causes irreversible damage to LLMs, while the latter incurs additional inference overhead and fuzzy vector matching is not always reliable. To address these issues, we propose an expandable Subject Word Embedding Altering (SWEA) framework, which modifies the representation of subjects and achieve the goal of editing knowledge during the inference stage. SWEA uses precise key matching outside the model and performs reliable subject word embedding altering, thus protecting the original weights of the model without increasing inference overhead. We then propose optimizing then suppressing fusion method, which first optimizes the embedding vector for the editing target and then suppresses the Knowledge Embedding Dimension (KED) to obtain the final fused embedding. We thus propose SWEAOS method for editing factual knowledge in LLMs. We demonstrate the state-of-the-art performance of SWEAOS on the COUNTERFACT and zsRE datasets. To further validate the reasoning ability of SWEAOS in editing knowledge, we evaluate it on the more complex RIPPLEEDITS benchmark. The results on two subdatasets demonstrate that our SWEAOS possesses state-of-the-art reasoning ability.
Posterior Probability Matters: Doubly-Adaptive Calibration for Neural Predictions in Online Advertising
May 15, 2022
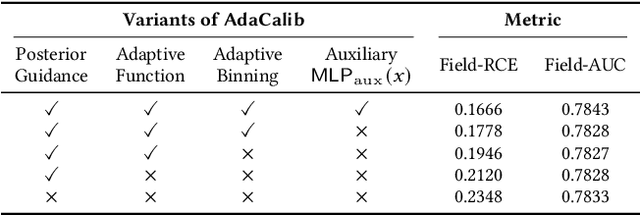
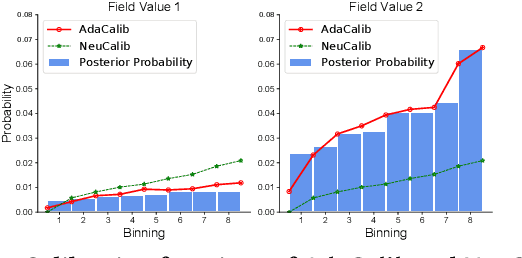
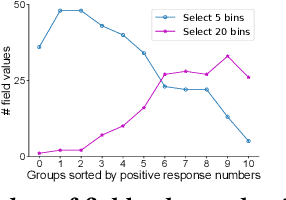
Predicting user response probabilities is vital for ad ranking and bidding. We hope that predictive models can produce accurate probabilistic predictions that reflect true likelihoods. Calibration techniques aims to post-process model predictions to posterior probabilities. Field-level calibration -- which performs calibration w.r.t. to a specific field value -- is fine-grained and more practical. In this paper we propose a doubly-adaptive approach AdaCalib. It learns an isotonic function family to calibrate model predictions with the guidance of posterior statistics, and field-adaptive mechanisms are designed to ensure that the posterior is appropriate for the field value to be calibrated. Experiments verify that AdaCalib achieves significant improvement on calibration performance. It has been deployed online and beats previous approach.
UKD: Debiasing Conversion Rate Estimation via Uncertainty-regularized Knowledge Distillation
Jan 20, 2022

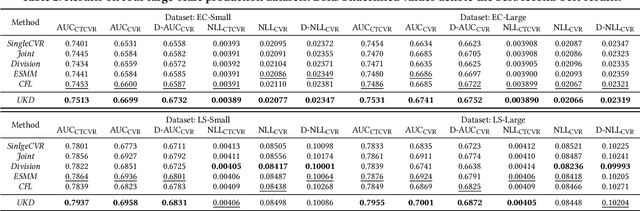

In online advertising, conventional post-click conversion rate (CVR) estimation models are trained using clicked samples. However, during online serving the models need to estimate for all impression ads, leading to the sample selection bias (SSB) issue. Intuitively, providing reliable supervision signals for unclicked ads is a feasible way to alleviate the SSB issue. This paper proposes an uncertainty-regularized knowledge distillation (UKD) framework to debias CVR estimation via distilling knowledge from unclicked ads. A teacher model learns click-adaptive representations and produces pseudo-conversion labels on unclicked ads as supervision signals. Then a student model is trained on both clicked and unclicked ads with knowledge distillation, performing uncertainty modeling to alleviate the inherent noise in pseudo-labels. Experiments on billion-scale datasets show that UKD outperforms previous debiasing methods. Online results verify that UKD achieves significant improvements.