 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupporting renewable energy planning and operation with data-driven high-resolution ensemble weather forecast
May 07, 2025The planning and operation of renewable energy, especially wind power, depend crucially on accurate, timely, and high-resolution weather information. Coarse-grid global numerical weather forecasts are typically downscaled to meet these requirements, introducing challenges of scale inconsistency, process representation error, computation cost, and entanglement of distinct uncertainty sources from chaoticity, model bias, and large-scale forcing. We address these challenges by learning the climatological distribution of a target wind farm using its high-resolution numerical weather simulations. An optimal combination of this learned high-resolution climatological prior with coarse-grid large scale forecasts yields highly accurate, fine-grained, full-variable, large ensemble of weather pattern forecasts. Using observed meteorological records and wind turbine power outputs as references, the proposed methodology verifies advantageously compared to existing numerical/statistical forecasting-downscaling pipelines, regarding either deterministic/probabilistic skills or economic gains. Moreover, a 100-member, 10-day forecast with spatial resolution of 1 km and output frequency of 15 min takes < 1 hour on a moderate-end GPU, as contrast to $\mathcal{O}(10^3)$ CPU hours for conventional numerical simulation. By drastically reducing computational costs while maintaining accuracy, our method paves the way for more efficient and reliable renewable energy planning and operation.
Long-Term Prediction Accuracy Improvement of Data-Driven Medium-Range Global Weather Forecast
Jun 26, 2024



Long-term stability stands as a crucial requirement in data-driven medium-range global weather forecasting. Spectral bias is recognized as the primary contributor to instabilities, as data-driven methods difficult to learn small-scale dynamics. In this paper, we reveal that the universal mechanism for these instabilities is not only related to spectral bias but also to distortions brought by processing spherical data using conventional convolution. These distortions lead to a rapid amplification of errors over successive long-term iterations, resulting in a significant decline in forecast accuracy. To address this issue, a universal neural operator called the Spherical Harmonic Neural Operator (SHNO) is introduced to improve long-term iterative forecasts. SHNO uses the spherical harmonic basis to mitigate distortions for spherical data and uses gated residual spectral attention (GRSA) to correct spectral bias caused by spurious correlations across different scales. The effectiveness and merit of the proposed method have been validated through its application for spherical Shallow Water Equations (SWEs) and medium-range global weather forecasting. Our findings highlight the benefits and potential of SHNO to improve the accuracy of long-term prediction.
TVDIM: Enhancing Image Self-Supervised Pretraining via Noisy Text Data
Jun 13, 2021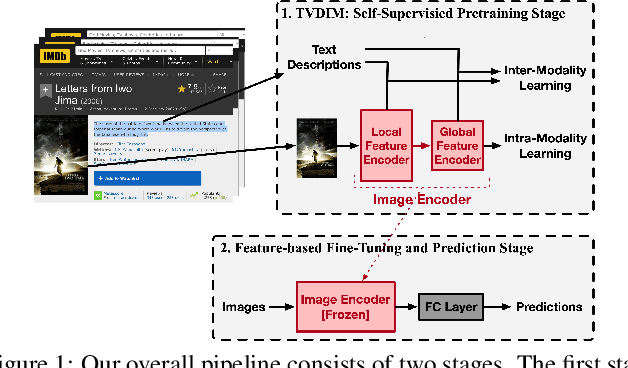
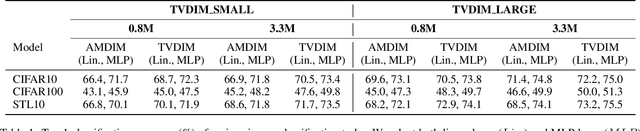
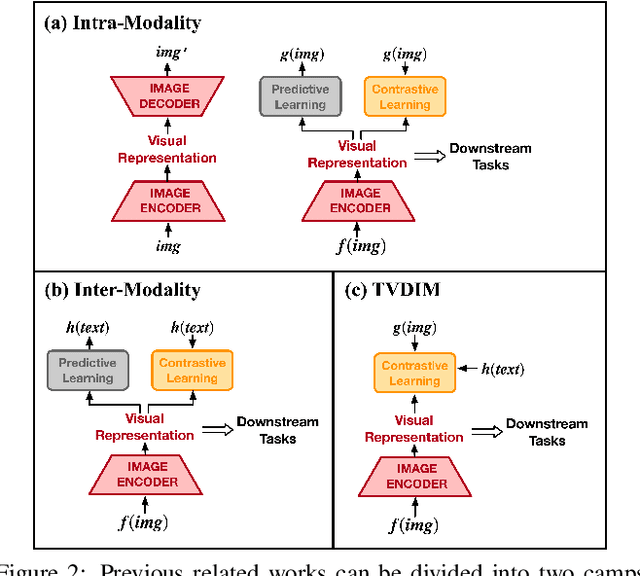
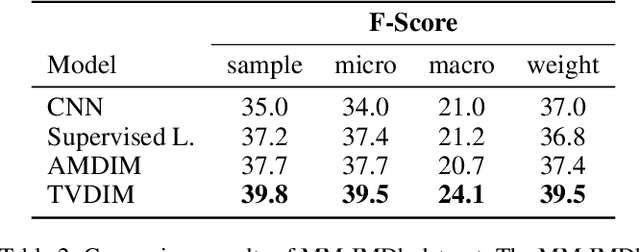
Among ubiquitous multimodal data in the real world, text is the modality generated by human, while image reflects the physical world honestly. In a visual understanding application, machines are expected to understand images like human. Inspired by this, we propose a novel self-supervised learning method, named Text-enhanced Visual Deep InfoMax (TVDIM), to learn better visual representations by fully utilizing the naturally-existing multimodal data. Our core idea of self-supervised learning is to maximize the mutual information between features extracted from multiple views of a shared context to a rational degree. Different from previous methods which only consider multiple views from a single modality, our work produces multiple views from different modalities, and jointly optimizes the mutual information for features pairs of intra-modality and inter-modality. Considering the information gap between inter-modality features pairs from data noise, we adopt a \emph{ranking-based} contrastive learning to optimize the mutual information. During evaluation, we directly use the pre-trained visual representations to complete various image classification tasks. Experimental results show that, TVDIM significantly outperforms previous visual self-supervised methods when processing the same set of images.
InfoBehavior: Self-supervised Representation Learning for Ultra-long Behavior Sequence via Hierarchical Grouping
Jun 13, 2021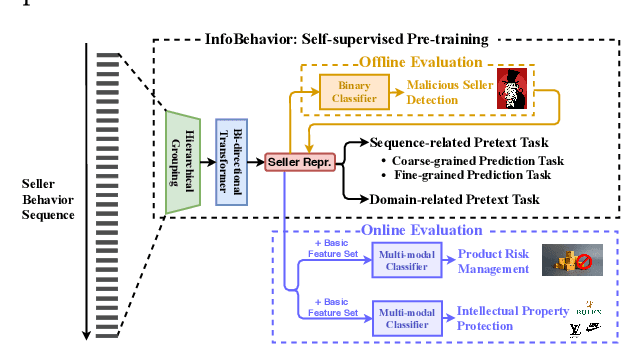
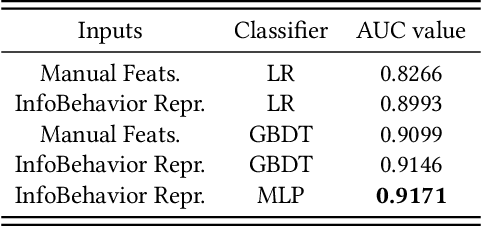
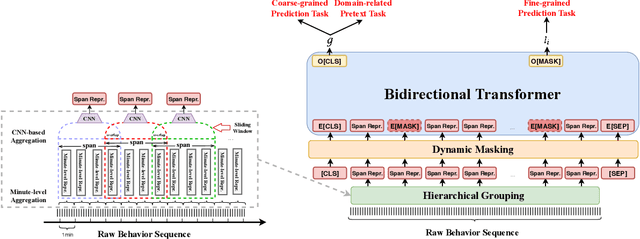
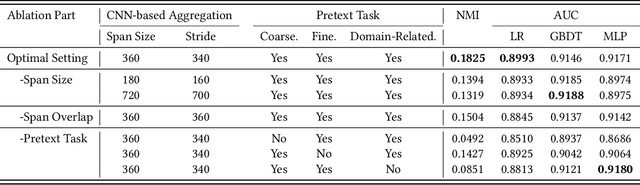
E-commerce companies have to face abnormal sellers who sell potentially-risky products. Typically, the risk can be identified by jointly considering product content (e.g., title and image) and seller behavior. This work focuses on behavior feature extraction as behavior sequences can provide valuable clues for the risk discovery by reflecting the sellers' operation habits. Traditional feature extraction techniques heavily depend on domain experts and adapt poorly to new tasks. In this paper, we propose a self-supervised method InfoBehavior to automatically extract meaningful representations from ultra-long raw behavior sequences instead of the costly feature selection procedure. InfoBehavior utilizes Bidirectional Transformer as feature encoder due to its excellent capability in modeling long-term dependency. However, it is intractable for commodity GPUs because the time and memory required by Transformer grow quadratically with the increase of sequence length. Thus, we propose a hierarchical grouping strategy to aggregate ultra-long raw behavior sequences to length-processable high-level embedding sequences. Moreover, we introduce two types of pretext tasks. Sequence-related pretext task defines a contrastive-based training objective to correctly select the masked-out coarse-grained/fine-grained behavior sequences against other "distractor" behavior sequences; Domain-related pretext task designs a classification training objective to correctly predict the domain-specific statistical results of anomalous behavior. We show that behavior representations from the pre-trained InfoBehavior can be directly used or integrated with features from other side information to support a wide range of downstream tasks. Experimental results demonstrate that InfoBehavior significantly improves the performance of Product Risk Management and Intellectual Property Protection.
GraphTheta: A Distributed Graph Neural Network Learning System With Flexible Training Strategy
Apr 21, 2021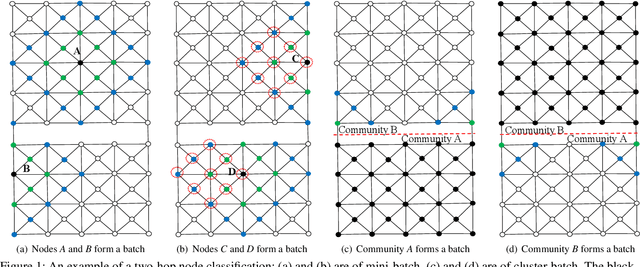
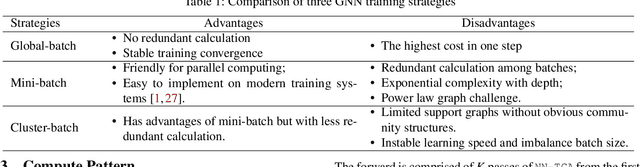
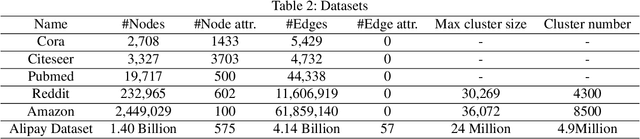
Graph neural networks (GNNs) have been demonstrated as a powerful tool for analysing non-Euclidean graph data. However, the lack of efficient distributed graph learning systems severely hinders applications of GNNs, especially when graphs are big, of high density or with highly skewed node degree distributions. In this paper, we present a new distributed graph learning system GraphTheta, which supports multiple training strategies and enables efficient and scalable learning on big graphs. GraphTheta implements both localized and globalized graph convolutions on graphs, where a new graph learning abstraction NN-TGAR is designed to bridge the gap between graph processing and graph learning frameworks. A distributed graph engine is proposed to conduct the stochastic gradient descent optimization with hybrid-parallel execution. Moreover, we add support for a new cluster-batched training strategy in addition to the conventional global-batched and mini-batched ones. We evaluate GraphTheta using a number of network data with network size ranging from small-, modest- to large-scale. Experimental results show that GraphTheta scales almost linearly to 1,024 workers and trains an in-house developed GNN model within 26 hours on Alipay dataset of 1.4 billion nodes and 4.1 billion attributed edges. Moreover, GraphTheta also obtains better prediction results than the state-of-the-art GNN methods. To the best of our knowledge, this work represents the largest edge-attributed GNN learning task conducted on a billion-scale network in the literature.