 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoBehavior: Self-supervised Representation Learning for Ultra-long Behavior Sequence via Hierarchical Grouping
Jun 13, 2021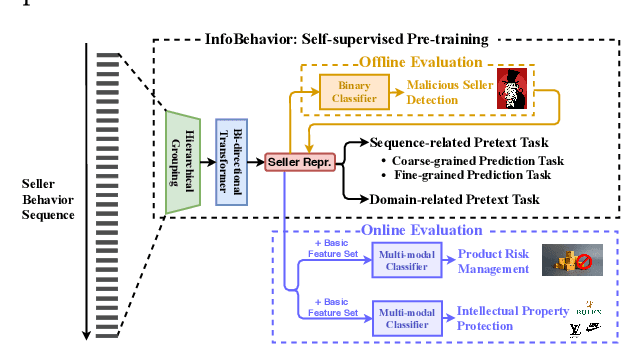
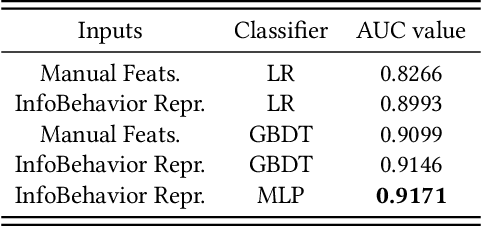
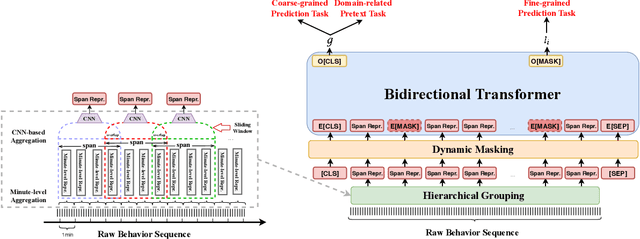
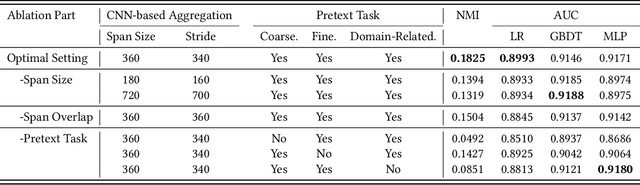
E-commerce companies have to face abnormal sellers who sell potentially-risky products. Typically, the risk can be identified by jointly considering product content (e.g., title and image) and seller behavior. This work focuses on behavior feature extraction as behavior sequences can provide valuable clues for the risk discovery by reflecting the sellers' operation habits. Traditional feature extraction techniques heavily depend on domain experts and adapt poorly to new tasks. In this paper, we propose a self-supervised method InfoBehavior to automatically extract meaningful representations from ultra-long raw behavior sequences instead of the costly feature selection procedure. InfoBehavior utilizes Bidirectional Transformer as feature encoder due to its excellent capability in modeling long-term dependency. However, it is intractable for commodity GPUs because the time and memory required by Transformer grow quadratically with the increase of sequence length. Thus, we propose a hierarchical grouping strategy to aggregate ultra-long raw behavior sequences to length-processable high-level embedding sequences. Moreover, we introduce two types of pretext tasks. Sequence-related pretext task defines a contrastive-based training objective to correctly select the masked-out coarse-grained/fine-grained behavior sequences against other "distractor" behavior sequences; Domain-related pretext task designs a classification training objective to correctly predict the domain-specific statistical results of anomalous behavior. We show that behavior representations from the pre-trained InfoBehavior can be directly used or integrated with features from other side information to support a wide range of downstream tasks. Experimental results demonstrate that InfoBehavior significantly improves the performance of Product Risk Management and Intellectual Property Protection.
Spam Review Detection with Graph Convolutional Networks
Aug 22, 2019
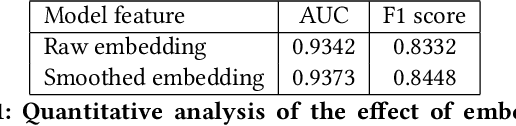
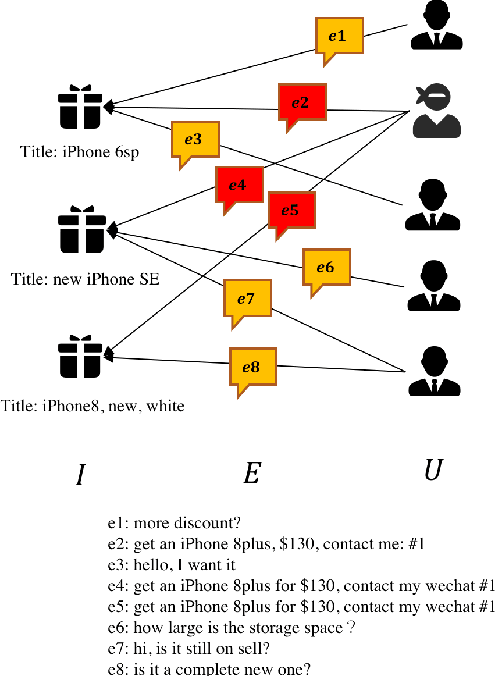
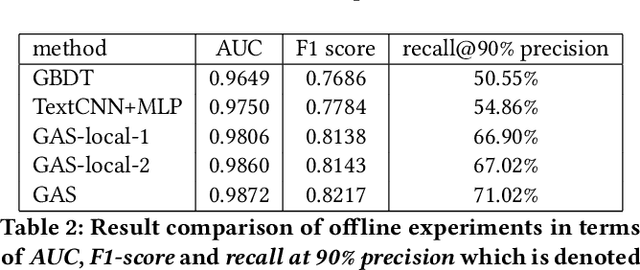
Customers make a lot of reviews on online shopping websites every day, e.g., Amazon and Taobao. Reviews affect the buying decisions of customers, meanwhile, attract lots of spammers aiming at misleading buyers. Xianyu, the largest second-hand goods app in China, suffering from spam reviews. The anti-spam system of Xianyu faces two major challenges: scalability of the data and adversarial actions taken by spammers. In this paper, we present our technical solutions to address these challenges. We propose a large-scale anti-spam method based on graph convolutional networks (GCN) for detecting spam advertisements at Xianyu, named GCN-based Anti-Spam (GAS) model. In this model, a heterogeneous graph and a homogeneous graph are integrated to capture the local context and global context of a comment. Offline experiments show that the proposed method is superior to our baseline model in which the information of reviews, features of users and items being reviewed are utilized. Furthermore, we deploy our system to process million-scale data daily at Xianyu. The online performance also demonstrates the effectiveness of the proposed method.