 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Invariant Learning for Dynamic Graphs under Distribution Shifts
Mar 08, 2024Dynamic graph neural networks (DyGNNs) currently struggle with handling distribution shifts that are inherent in dynamic graphs. Existing work on DyGNNs with out-of-distribution settings only focuses on the time domain, failing to handle cases involving distribution shifts in the spectral domain. In this paper, we discover that there exist cases with distribution shifts unobservable in the time domain while observable in the spectral domain, and propose to study distribution shifts on dynamic graphs in the spectral domain for the first time. However, this investigation poses two key challenges: i) it is non-trivial to capture different graph patterns that are driven by various frequency components entangled in the spectral domain; and ii) it remains unclear how to handle distribution shifts with the discovered spectral patterns. To address these challenges, we propose Spectral Invariant Learning for Dynamic Graphs under Distribution Shifts (SILD), which can handle distribution shifts on dynamic graphs by capturing and utilizing invariant and variant spectral patterns. Specifically, we first design a DyGNN with Fourier transform to obtain the ego-graph trajectory spectrums, allowing the mixed dynamic graph patterns to be transformed into separate frequency components. We then develop a disentangled spectrum mask to filter graph dynamics from various frequency components and discover the invariant and variant spectral patterns. Finally, we propose invariant spectral filtering, which encourages the model to rely on invariant patterns for generalization under distribution shifts. Experimental results on synthetic and real-world dynamic graph datasets demonstrate the superiority of our method for both node classification and link prediction tasks under distribution shifts.
PIAT: Parameter Interpolation based Adversarial Training for Image Classification
Mar 24, 2023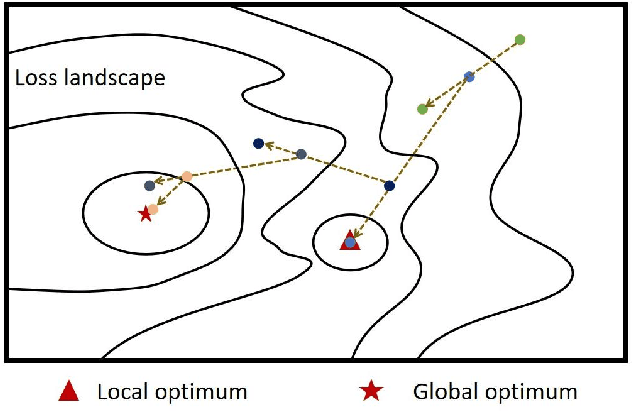
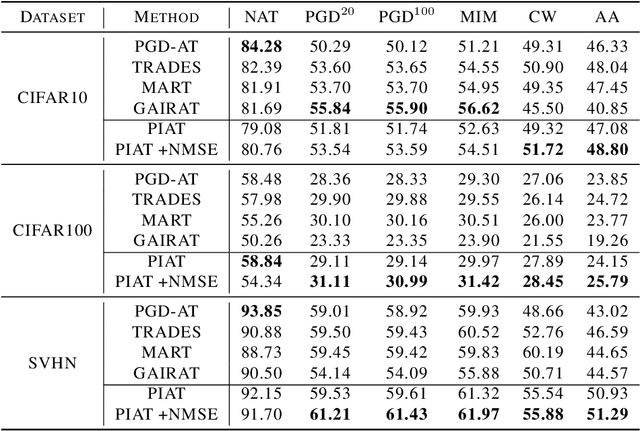
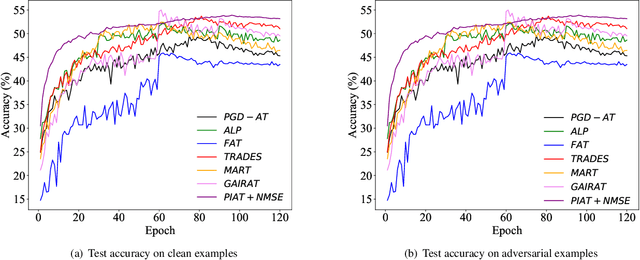
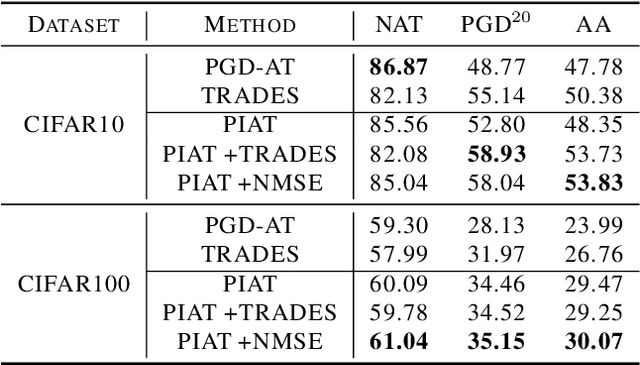
Adversarial training has been demonstrated to be the most effective approach to defend against adversarial attacks. However, existing adversarial training methods show apparent oscillations and overfitting issue in the training process, degrading the defense efficacy. In this work, we propose a novel framework, termed Parameter Interpolation based Adversarial Training (PIAT), that makes full use of the historical information during training. Specifically, at the end of each epoch, PIAT tunes the model parameters as the interpolation of the parameters of the previous and current epochs. Besides, we suggest to use the Normalized Mean Square Error (NMSE) to further improve the robustness by aligning the clean and adversarial examples. Compared with other regularization methods, NMSE focuses more on the relative magnitude of the logits rather than the absolute magnitude. Extensive experiments on several benchmark datasets and various networks show that our method could prominently improve the model robustness and reduce the generalization error. Moreover, our framework is general and could further boost the robust accuracy when combined with other adversarial training methods.
Compare learning: bi-attention network for few-shot learning
Mar 25, 2022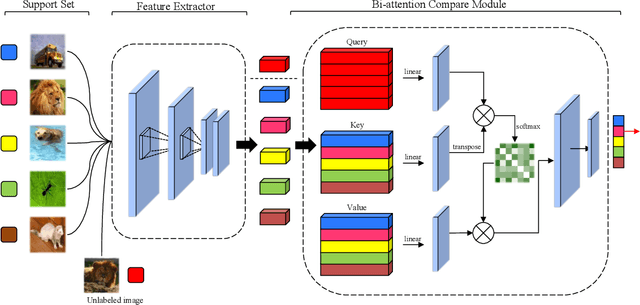
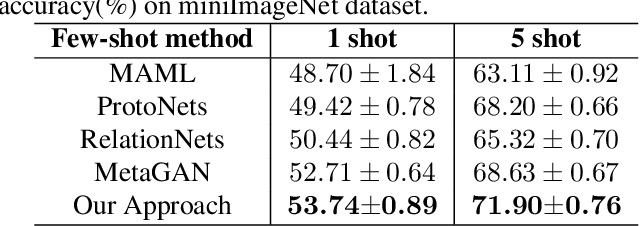

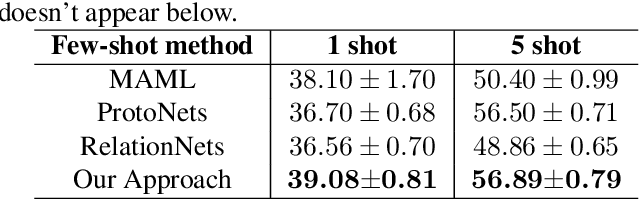
Learning with few labeled data is a key challenge for visual recognition, as deep neural networks tend to overfit using a few samples only. One of the Few-shot learning methods called metric learning addresses this challenge by first learning a deep distance metric to determine whether a pair of images belong to the same category, then applying the trained metric to instances from other test set with limited labels. This method makes the most of the few samples and limits the overfitting effectively. However, extant metric networks usually employ Linear classifiers or Convolutional neural networks (CNN) that are not precise enough to globally capture the subtle differences between vectors. In this paper, we propose a novel approach named Bi-attention network to compare the instances, which can measure the similarity between embeddings of instances precisely, globally and efficiently. We verify the effectiveness of our model on two benchmarks. Experiments show that our approach achieved improved accuracy and convergence speed over baseline models.
InfoBehavior: Self-supervised Representation Learning for Ultra-long Behavior Sequence via Hierarchical Grouping
Jun 13, 2021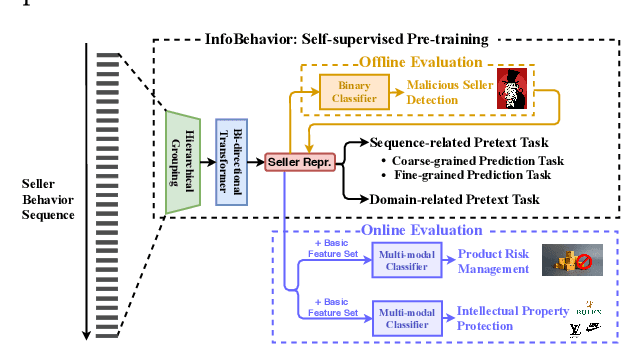
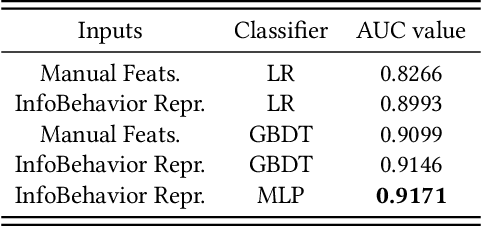
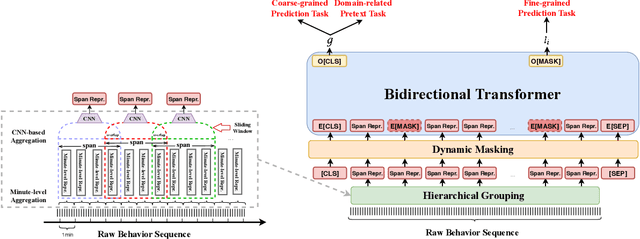
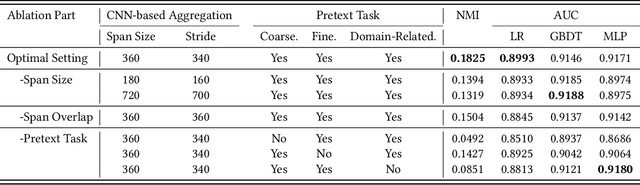
E-commerce companies have to face abnormal sellers who sell potentially-risky products. Typically, the risk can be identified by jointly considering product content (e.g., title and image) and seller behavior. This work focuses on behavior feature extraction as behavior sequences can provide valuable clues for the risk discovery by reflecting the sellers' operation habits. Traditional feature extraction techniques heavily depend on domain experts and adapt poorly to new tasks. In this paper, we propose a self-supervised method InfoBehavior to automatically extract meaningful representations from ultra-long raw behavior sequences instead of the costly feature selection procedure. InfoBehavior utilizes Bidirectional Transformer as feature encoder due to its excellent capability in modeling long-term dependency. However, it is intractable for commodity GPUs because the time and memory required by Transformer grow quadratically with the increase of sequence length. Thus, we propose a hierarchical grouping strategy to aggregate ultra-long raw behavior sequences to length-processable high-level embedding sequences. Moreover, we introduce two types of pretext tasks. Sequence-related pretext task defines a contrastive-based training objective to correctly select the masked-out coarse-grained/fine-grained behavior sequences against other "distractor" behavior sequences; Domain-related pretext task designs a classification training objective to correctly predict the domain-specific statistical results of anomalous behavior. We show that behavior representations from the pre-trained InfoBehavior can be directly used or integrated with features from other side information to support a wide range of downstream tasks. Experimental results demonstrate that InfoBehavior significantly improves the performance of Product Risk Management and Intellectual Property Protection.