 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTVDIM: Enhancing Image Self-Supervised Pretraining via Noisy Text Data
Paper and Code
Jun 13, 2021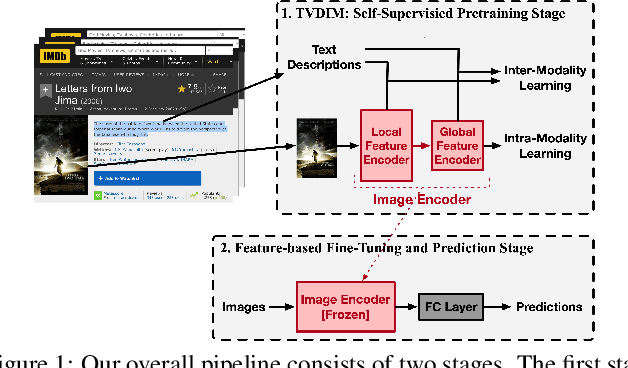
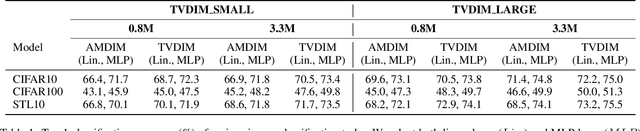
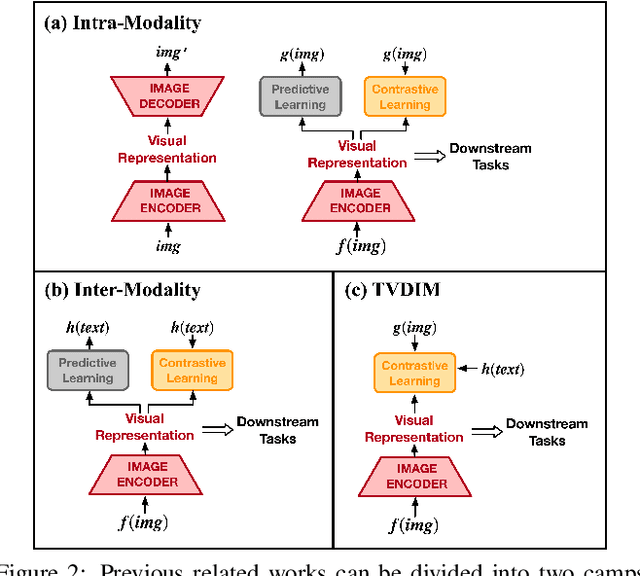
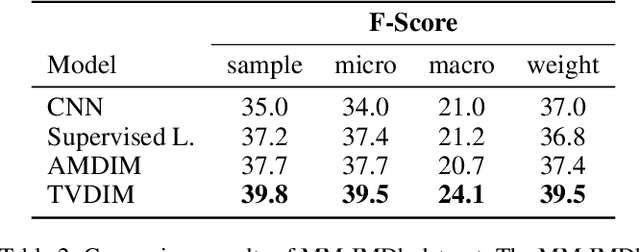
Among ubiquitous multimodal data in the real world, text is the modality generated by human, while image reflects the physical world honestly. In a visual understanding application, machines are expected to understand images like human. Inspired by this, we propose a novel self-supervised learning method, named Text-enhanced Visual Deep InfoMax (TVDIM), to learn better visual representations by fully utilizing the naturally-existing multimodal data. Our core idea of self-supervised learning is to maximize the mutual information between features extracted from multiple views of a shared context to a rational degree. Different from previous methods which only consider multiple views from a single modality, our work produces multiple views from different modalities, and jointly optimizes the mutual information for features pairs of intra-modality and inter-modality. Considering the information gap between inter-modality features pairs from data noise, we adopt a \emph{ranking-based} contrastive learning to optimize the mutual information. During evaluation, we directly use the pre-trained visual representations to complete various image classification tasks. Experimental results show that, TVDIM significantly outperforms previous visual self-supervised methods when processing the same set of images.