 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrbanIR: Large-Scale Urban Scene Inverse Rendering from a Single Video
Paper and Code
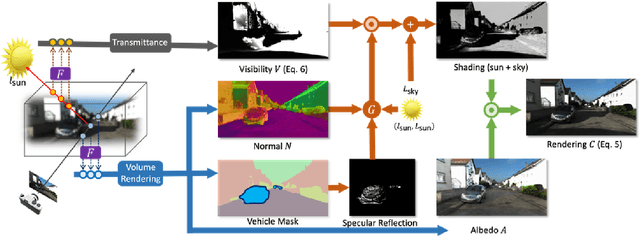
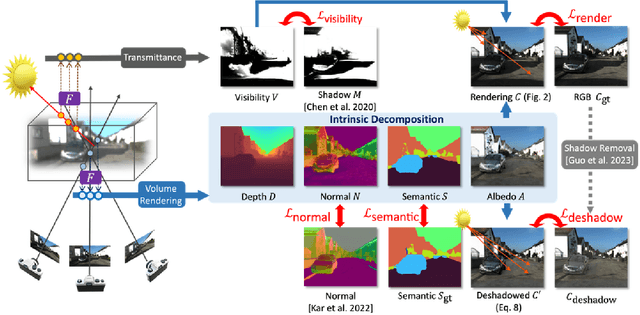


We show how to build a model that allows realistic, free-viewpoint renderings of a scene under novel lighting conditions from video. Our method -- UrbanIR: Urban Scene Inverse Rendering -- computes an inverse graphics representation from the video. UrbanIR jointly infers shape, albedo, visibility, and sun and sky illumination from a single video of unbounded outdoor scenes with unknown lighting. UrbanIR uses videos from cameras mounted on cars (in contrast to many views of the same points in typical NeRF-style estimation). As a result, standard methods produce poor geometry estimates (for example, roofs), and there are numerous ''floaters''. Errors in inverse graphics inference can result in strong rendering artifacts. UrbanIR uses novel losses to control these and other sources of error. UrbanIR uses a novel loss to make very good estimates of shadow volumes in the original scene. The resulting representations facilitate controllable editing, delivering photorealistic free-viewpoint renderings of relit scenes and inserted objects. Qualitative evaluation demonstrates strong improvements over the state-of-the-art.