 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSRM: High-Fidelity Object-Centric Reconstruction via Scaled Context Windows
Apr 06, 2026We introduce the Large Sparse Reconstruction Model to study how scaling transformer context windows impacts feed-forward 3D reconstruction. Although recent object-centric feed-forward methods deliver robust, high-quality reconstruction, they still lag behind dense-view optimization in recovering fine-grained texture and appearance. We show that expanding the context window -- by substantially increasing the number of active object and image tokens -- remarkably narrows this gap and enables high-fidelity 3D object reconstruction and inverse rendering. To scale effectively, we adapt native sparse attention in our architecture design, unlocking its capacity for 3D reconstruction with three key contributions: (1) an efficient coarse-to-fine pipeline that focuses computation on informative regions by predicting sparse high-resolution residuals; (2) a 3D-aware spatial routing mechanism that establishes accurate 2D-3D correspondences using explicit geometric distances rather than standard attention scores; and (3) a custom block-aware sequence parallelism strategy utilizing an All-gather-KV protocol to balance dynamic, sparse workloads across GPUs. As a result, LSRM handles 20x more object tokens and >2x more image tokens than prior state-of-the-art (SOTA) methods. Extensive evaluations on standard novel-view synthesis benchmarks show substantial gains over the current SOTA, yielding 2.5 dB higher PSNR and 40% lower LPIPS. Furthermore, when extending LSRM to inverse rendering tasks, qualitative and quantitative evaluations on widely-used benchmarks demonstrate consistent improvements in texture and geometry details, achieving an LPIPS that matches or exceeds that of SOTA dense-view optimization methods. Code and model will be released on our project page.
ART: Articulated Reconstruction Transformer
Dec 16, 2025We introduce ART, Articulated Reconstruction Transformer -- a category-agnostic, feed-forward model that reconstructs complete 3D articulated objects from only sparse, multi-state RGB images. Previous methods for articulated object reconstruction either rely on slow optimization with fragile cross-state correspondences or use feed-forward models limited to specific object categories. In contrast, ART treats articulated objects as assemblies of rigid parts, formulating reconstruction as part-based prediction. Our newly designed transformer architecture maps sparse image inputs to a set of learnable part slots, from which ART jointly decodes unified representations for individual parts, including their 3D geometry, texture, and explicit articulation parameters. The resulting reconstructions are physically interpretable and readily exportable for simulation. Trained on a large-scale, diverse dataset with per-part supervision, and evaluated across diverse benchmarks, ART achieves significant improvements over existing baselines and establishes a new state of the art for articulated object reconstruction from image inputs.
GSWorld: Closed-Loop Photo-Realistic Simulation Suite for Robotic Manipulation
Oct 23, 2025This paper presents GSWorld, a robust, photo-realistic simulator for robotics manipulation that combines 3D Gaussian Splatting with physics engines. Our framework advocates "closing the loop" of developing manipulation policies with reproducible evaluation of policies learned from real-robot data and sim2real policy training without using real robots. To enable photo-realistic rendering of diverse scenes, we propose a new asset format, which we term GSDF (Gaussian Scene Description File), that infuses Gaussian-on-Mesh representation with robot URDF and other objects. With a streamlined reconstruction pipeline, we curate a database of GSDF that contains 3 robot embodiments for single-arm and bimanual manipulation, as well as more than 40 objects. Combining GSDF with physics engines, we demonstrate several immediate interesting applications: (1) learning zero-shot sim2real pixel-to-action manipulation policy with photo-realistic rendering, (2) automated high-quality DAgger data collection for adapting policies to deployment environments, (3) reproducible benchmarking of real-robot manipulation policies in simulation, (4) simulation data collection by virtual teleoperation, and (5) zero-shot sim2real visual reinforcement learning. Website: https://3dgsworld.github.io/.
DGS-LRM: Real-Time Deformable 3D Gaussian Reconstruction From Monocular Videos
Jun 11, 2025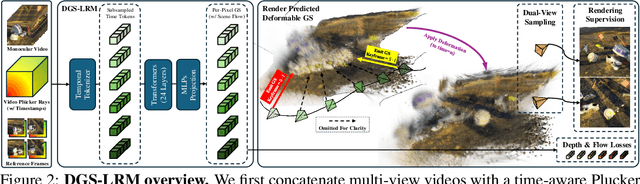
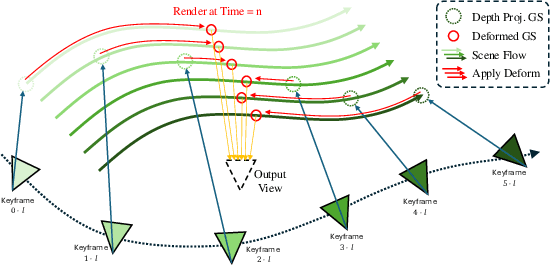
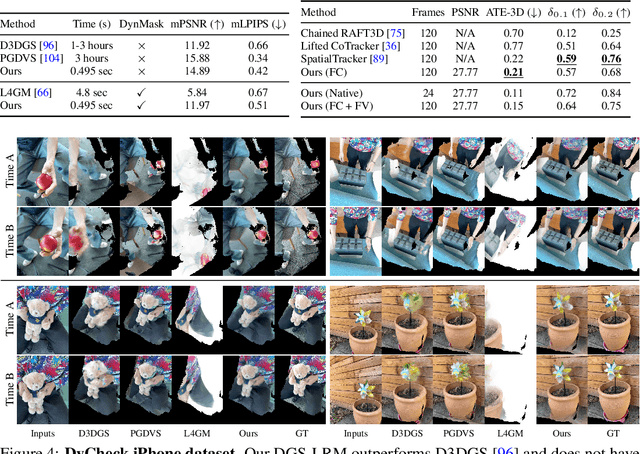

We introduce the Deformable Gaussian Splats Large Reconstruction Model (DGS-LRM), the first feed-forward method predicting deformable 3D Gaussian splats from a monocular posed video of any dynamic scene. Feed-forward scene reconstruction has gained significant attention for its ability to rapidly create digital replicas of real-world environments. However, most existing models are limited to static scenes and fail to reconstruct the motion of moving objects. Developing a feed-forward model for dynamic scene reconstruction poses significant challenges, including the scarcity of training data and the need for appropriate 3D representations and training paradigms. To address these challenges, we introduce several key technical contributions: an enhanced large-scale synthetic dataset with ground-truth multi-view videos and dense 3D scene flow supervision; a per-pixel deformable 3D Gaussian representation that is easy to learn, supports high-quality dynamic view synthesis, and enables long-range 3D tracking; and a large transformer network that achieves real-time, generalizable dynamic scene reconstruction. Extensive qualitative and quantitative experiments demonstrate that DGS-LRM achieves dynamic scene reconstruction quality comparable to optimization-based methods, while significantly outperforming the state-of-the-art predictive dynamic reconstruction method on real-world examples. Its predicted physically grounded 3D deformation is accurate and can readily adapt for long-range 3D tracking tasks, achieving performance on par with state-of-the-art monocular video 3D tracking methods.
4DGT: Learning a 4D Gaussian Transformer Using Real-World Monocular Videos
Jun 09, 2025
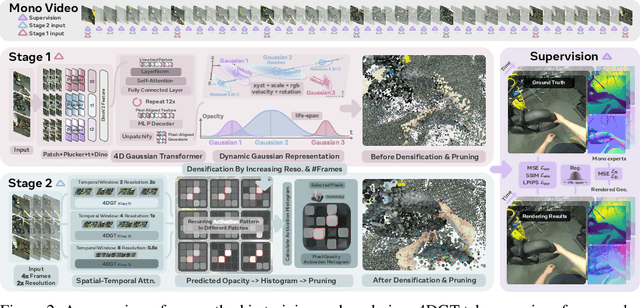


We propose 4DGT, a 4D Gaussian-based Transformer model for dynamic scene reconstruction, trained entirely on real-world monocular posed videos. Using 4D Gaussian as an inductive bias, 4DGT unifies static and dynamic components, enabling the modeling of complex, time-varying environments with varying object lifespans. We proposed a novel density control strategy in training, which enables our 4DGT to handle longer space-time input and remain efficient rendering at runtime. Our model processes 64 consecutive posed frames in a rolling-window fashion, predicting consistent 4D Gaussians in the scene. Unlike optimization-based methods, 4DGT performs purely feed-forward inference, reducing reconstruction time from hours to seconds and scaling effectively to long video sequences. Trained only on large-scale monocular posed video datasets, 4DGT can outperform prior Gaussian-based networks significantly in real-world videos and achieve on-par accuracy with optimization-based methods on cross-domain videos. Project page: https://4dgt.github.io
Photoreal Scene Reconstruction from an Egocentric Device
Jun 04, 2025In this paper, we investigate the challenges associated with using egocentric devices to photorealistic reconstruct the scene in high dynamic range. Existing methodologies typically assume using frame-rate 6DoF pose estimated from the device's visual-inertial odometry system, which may neglect crucial details necessary for pixel-accurate reconstruction. This study presents two significant findings. Firstly, in contrast to mainstream work treating RGB camera as global shutter frame-rate camera, we emphasize the importance of employing visual-inertial bundle adjustment (VIBA) to calibrate the precise timestamps and movement of the rolling shutter RGB sensing camera in a high frequency trajectory format, which ensures an accurate calibration of the physical properties of the rolling-shutter camera. Secondly, we incorporate a physical image formation model based into Gaussian Splatting, which effectively addresses the sensor characteristics, including the rolling-shutter effect of RGB cameras and the dynamic ranges measured by sensors. Our proposed formulation is applicable to the widely-used variants of Gaussian Splats representation. We conduct a comprehensive evaluation of our pipeline using the open-source Project Aria device under diverse indoor and outdoor lighting conditions, and further validate it on a Meta Quest3 device. Across all experiments, we observe a consistent visual enhancement of +1 dB in PSNR by incorporating VIBA, with an additional +1 dB achieved through our proposed image formation model. Our complete implementation, evaluation datasets, and recording profile are available at http://www.projectaria.com/photoreal-reconstruction/
Monocular Online Reconstruction with Enhanced Detail Preservation
May 14, 2025We propose an online 3D Gaussian-based dense mapping framework for photorealistic details reconstruction from a monocular image stream. Our approach addresses two key challenges in monocular online reconstruction: distributing Gaussians without relying on depth maps and ensuring both local and global consistency in the reconstructed maps. To achieve this, we introduce two key modules: the Hierarchical Gaussian Management Module for effective Gaussian distribution and the Global Consistency Optimization Module for maintaining alignment and coherence at all scales. In addition, we present the Multi-level Occupancy Hash Voxels (MOHV), a structure that regularizes Gaussians for capturing details across multiple levels of granularity. MOHV ensures accurate reconstruction of both fine and coarse geometries and textures, preserving intricate details while maintaining overall structural integrity. Compared to state-of-the-art RGB-only and even RGB-D methods, our framework achieves superior reconstruction quality with high computational efficiency. Moreover, it integrates seamlessly with various tracking systems, ensuring generality and scalability.
LIRM: Large Inverse Rendering Model for Progressive Reconstruction of Shape, Materials and View-dependent Radiance Fields
Apr 28, 2025We present Large Inverse Rendering Model (LIRM), a transformer architecture that jointly reconstructs high-quality shape, materials, and radiance fields with view-dependent effects in less than a second. Our model builds upon the recent Large Reconstruction Models (LRMs) that achieve state-of-the-art sparse-view reconstruction quality. However, existing LRMs struggle to reconstruct unseen parts accurately and cannot recover glossy appearance or generate relightable 3D contents that can be consumed by standard Graphics engines. To address these limitations, we make three key technical contributions to build a more practical multi-view 3D reconstruction framework. First, we introduce an update model that allows us to progressively add more input views to improve our reconstruction. Second, we propose a hexa-plane neural SDF representation to better recover detailed textures, geometry and material parameters. Third, we develop a novel neural directional-embedding mechanism to handle view-dependent effects. Trained on a large-scale shape and material dataset with a tailored coarse-to-fine training scheme, our model achieves compelling results. It compares favorably to optimization-based dense-view inverse rendering methods in terms of geometry and relighting accuracy, while requiring only a fraction of the inference time.
Digital Twin Catalog: A Large-Scale Photorealistic 3D Object Digital Twin Dataset
Apr 11, 2025



We introduce Digital Twin Catalog (DTC), a new large-scale photorealistic 3D object digital twin dataset. A digital twin of a 3D object is a highly detailed, virtually indistinguishable representation of a physical object, accurately capturing its shape, appearance, physical properties, and other attributes. Recent advances in neural-based 3D reconstruction and inverse rendering have significantly improved the quality of 3D object reconstruction. Despite these advancements, there remains a lack of a large-scale, digital twin quality real-world dataset and benchmark that can quantitatively assess and compare the performance of different reconstruction methods, as well as improve reconstruction quality through training or fine-tuning. Moreover, to democratize 3D digital twin creation, it is essential to integrate creation techniques with next-generation egocentric computing platforms, such as AR glasses. Currently, there is no dataset available to evaluate 3D object reconstruction using egocentric captured images. To address these gaps, the DTC dataset features 2,000 scanned digital twin-quality 3D objects, along with image sequences captured under different lighting conditions using DSLR cameras and egocentric AR glasses. This dataset establishes the first comprehensive real-world evaluation benchmark for 3D digital twin creation tasks, offering a robust foundation for comparing and improving existing reconstruction methods. The DTC dataset is already released at https://www.projectaria.com/datasets/dtc/ and we will also make the baseline evaluations open-source.
3D Mesh Editing using Masked LRMs
Dec 11, 2024We present a novel approach to mesh shape editing, building on recent progress in 3D reconstruction from multi-view images. We formulate shape editing as a conditional reconstruction problem, where the model must reconstruct the input shape with the exception of a specified 3D region, in which the geometry should be generated from the conditional signal. To this end, we train a conditional Large Reconstruction Model (LRM) for masked reconstruction, using multi-view consistent masks rendered from a randomly generated 3D occlusion, and using one clean viewpoint as the conditional signal. During inference, we manually define a 3D region to edit and provide an edited image from a canonical viewpoint to fill in that region. We demonstrate that, in just a single forward pass, our method not only preserves the input geometry in the unmasked region through reconstruction capabilities on par with SoTA, but is also expressive enough to perform a variety of mesh edits from a single image guidance that past works struggle with, while being 10x faster than the top-performing competing prior work.