 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Spatially Varying Material Selection in Images
Jun 11, 2025
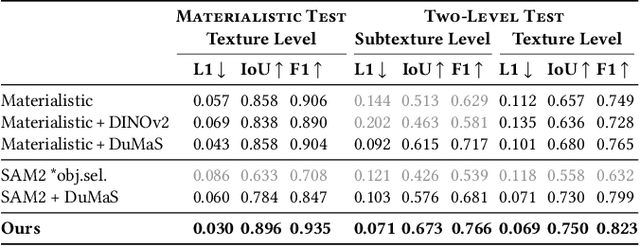

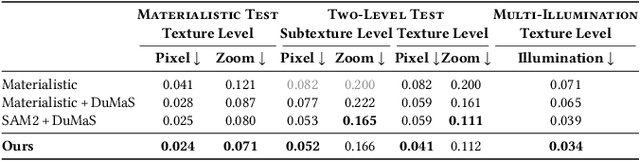
Selection is the first step in many image editing processes, enabling faster and simpler modifications of all pixels sharing a common modality. In this work, we present a method for material selection in images, robust to lighting and reflectance variations, which can be used for downstream editing tasks. We rely on vision transformer (ViT) models and leverage their features for selection, proposing a multi-resolution processing strategy that yields finer and more stable selection results than prior methods. Furthermore, we enable selection at two levels: texture and subtexture, leveraging a new two-level material selection (DuMaS) dataset which includes dense annotations for over 800,000 synthetic images, both on the texture and subtexture levels.
Bootstrapping Corner Cases: High-Resolution Inpainting for Safety Critical Detect and Avoid for Automated Flying
Jan 14, 2025Modern machine learning techniques have shown tremendous potential, especially for object detection on camera images. For this reason, they are also used to enable safety-critical automated processes such as autonomous drone flights. We present a study on object detection for Detect and Avoid, a safety critical function for drones that detects air traffic during automated flights for safety reasons. An ill-posed problem is the generation of good and especially large data sets, since detection itself is the corner case. Most models suffer from limited ground truth in raw data, \eg recorded air traffic or frontal flight with a small aircraft. It often leads to poor and critical detection rates. We overcome this problem by using inpainting methods to bootstrap the dataset such that it explicitly contains the corner cases of the raw data. We provide an overview of inpainting methods and generative models and present an example pipeline given a small annotated dataset. We validate our method by generating a high-resolution dataset, which we make publicly available and present it to an independent object detector that was fully trained on real data.
SAMa: Material-aware 3D Selection and Segmentation
Nov 28, 2024
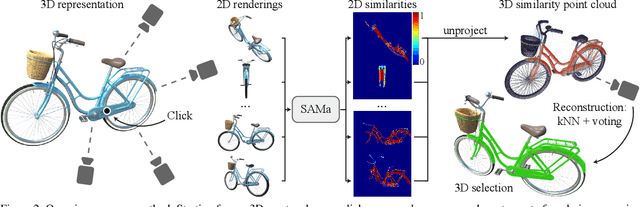
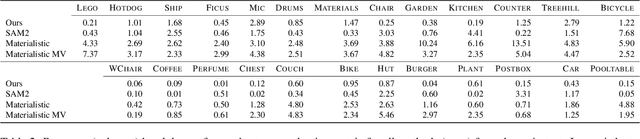
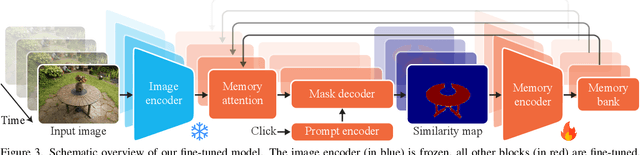
Decomposing 3D assets into material parts is a common task for artists and creators, yet remains a highly manual process. In this work, we introduce Select Any Material (SAMa), a material selection approach for various 3D representations. Building on the recently introduced SAM2 video selection model, we extend its capabilities to the material domain. We leverage the model's cross-view consistency to create a 3D-consistent intermediate material-similarity representation in the form of a point cloud from a sparse set of views. Nearest-neighbour lookups in this similarity cloud allow us to efficiently reconstruct accurate continuous selection masks over objects' surfaces that can be inspected from any view. Our method is multiview-consistent by design, alleviating the need for contrastive learning or feature-field pre-processing, and performs optimization-free selection in seconds. Our approach works on arbitrary 3D representations and outperforms several strong baselines in terms of selection accuracy and multiview consistency. It enables several compelling applications, such as replacing the diffuse-textured materials on a text-to-3D output, or selecting and editing materials on NeRFs and 3D-Gaussians.
NeRF Analogies: Example-Based Visual Attribute Transfer for NeRFs
Feb 13, 2024



A Neural Radiance Field (NeRF) encodes the specific relation of 3D geometry and appearance of a scene. We here ask the question whether we can transfer the appearance from a source NeRF onto a target 3D geometry in a semantically meaningful way, such that the resulting new NeRF retains the target geometry but has an appearance that is an analogy to the source NeRF. To this end, we generalize classic image analogies from 2D images to NeRFs. We leverage correspondence transfer along semantic affinity that is driven by semantic features from large, pre-trained 2D image models to achieve multi-view consistent appearance transfer. Our method allows exploring the mix-and-match product space of 3D geometry and appearance. We show that our method outperforms traditional stylization-based methods and that a large majority of users prefer our method over several typical baselines.
Neural Bounding
Oct 10, 2023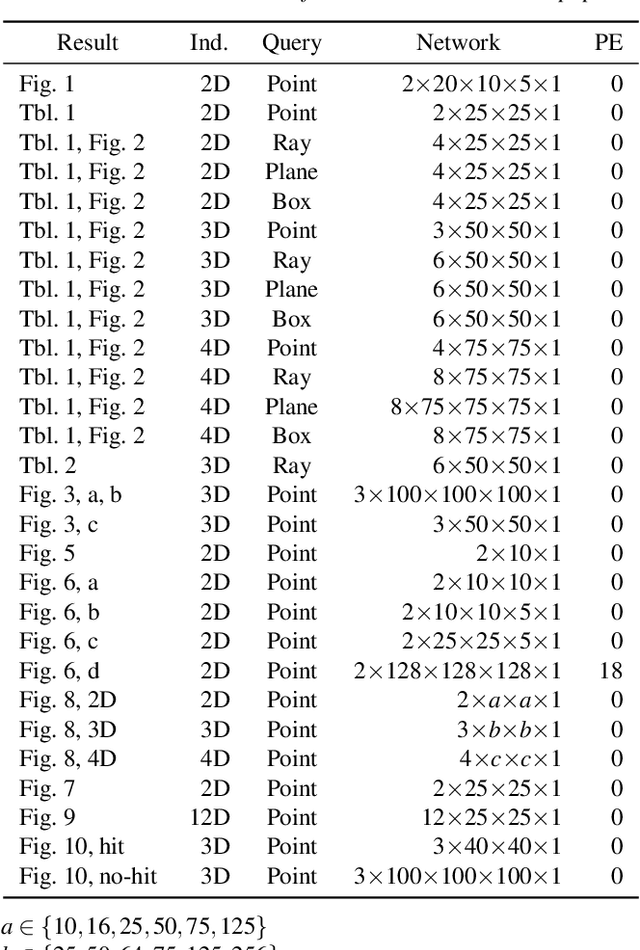
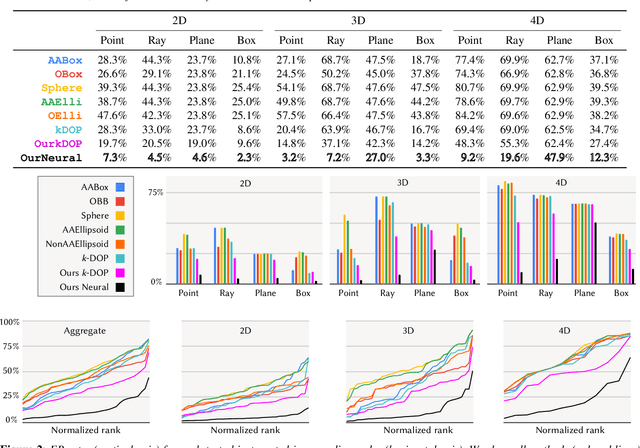
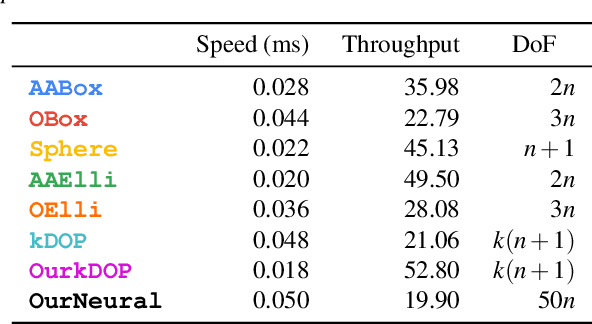

Bounding volumes are an established concept in computer graphics and vision tasks but have seen little change since their early inception. In this work, we study the use of neural networks as bounding volumes. Our key observation is that bounding, which so far has primarily been considered a problem of computational geometry, can be redefined as a problem of learning to classify space into free and empty. This learning-based approach is particularly advantageous in high-dimensional spaces, such as animated scenes with complex queries, where neural networks are known to excel. However, unlocking neural bounding requires a twist: allowing -- but also limiting -- false positives, while ensuring that the number of false negatives is strictly zero. We enable such tight and conservative results using a dynamically-weighted asymmetric loss function. Our results show that our neural bounding produces up to an order of magnitude fewer false positives than traditional methods.
Zero Grads Ever Given: Learning Local Surrogate Losses for Non-Differentiable Graphics
Aug 10, 2023

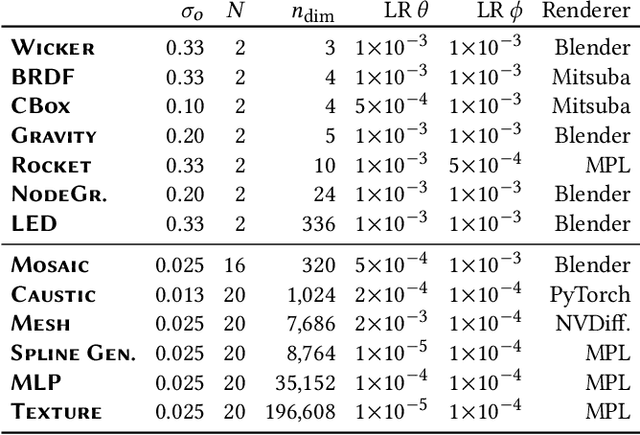
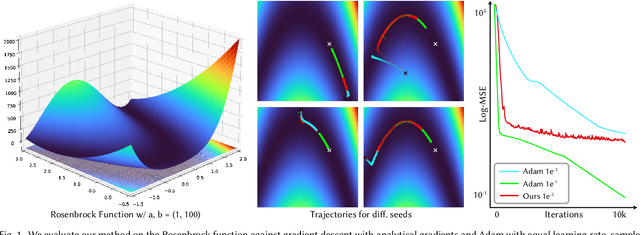
Gradient-based optimization is now ubiquitous across graphics, but unfortunately can not be applied to problems with undefined or zero gradients. To circumvent this issue, the loss function can be manually replaced by a "surrogate" that has similar minima but is differentiable. Our proposed framework, ZeroGrads, automates this process by learning a neural approximation of the objective function, the surrogate, which in turn can be used to differentiate through arbitrary black-box graphics pipelines. We train the surrogate on an actively smoothed version of the objective and encourage locality, focusing the surrogate's capacity on what matters at the current training episode. The fitting is performed online, alongside the parameter optimization, and self-supervised, without pre-computed data or pre-trained models. As sampling the objective is expensive (it requires a full rendering or simulator run), we devise an efficient sampling scheme that allows for tractable run-times and competitive performance at little overhead. We demonstrate optimizing diverse non-convex, non-differentiable black-box problems in graphics, such as visibility in rendering, discrete parameter spaces in procedural modelling or optimal control in physics-driven animation. In contrast to more traditional algorithms, our approach scales well to higher dimensions, which we demonstrate on problems with up to 35k interlinked variables.
Plateau-free Differentiable Path Tracing
Nov 30, 2022



Current differentiable renderers provide light transport gradients with respect to arbitrary scene parameters. However, the mere existence of these gradients does not guarantee useful update steps in an optimization. Instead, inverse rendering might not converge due to inherent plateaus, i.e., regions of zero gradient, in the objective function. We propose to alleviate this by convolving the high-dimensional rendering function that maps scene parameters to images with an additional kernel that blurs the parameter space. We describe two Monte Carlo estimators to compute plateau-free gradients efficiently, i.e., with low variance, and show that these translate into net-gains in optimization error and runtime performance. Our approach is a straightforward extension to both black-box and differentiable renderers and enables optimization of problems with intricate light transport, such as caustics or global illumination, that existing differentiable renderers do not converge on.
Learning to Learn and Sample BRDFs
Oct 07, 2022
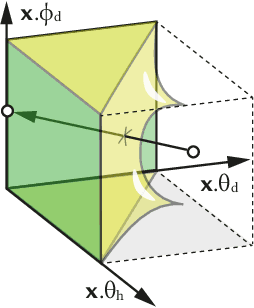


We propose a method to accelerate the joint process of physically acquiring and learning neural Bi-directional Reflectance Distribution Function (BRDF) models. While BRDF learning alone can be accelerated by meta-learning, acquisition remains slow as it relies on a mechanical process. We show that meta-learning can be extended to optimize the physical sampling pattern, too. After our method has been meta-trained for a set of fully-sampled BRDFs, it is able to quickly train on new BRDFs with up to five orders of magnitude fewer physical acquisition samples at similar quality. Our approach also extends to other linear and non-linear BRDF models, which we show in an extensive evaluation.
NICER: Aesthetic Image Enhancement with Humans in the Loop
Dec 03, 2020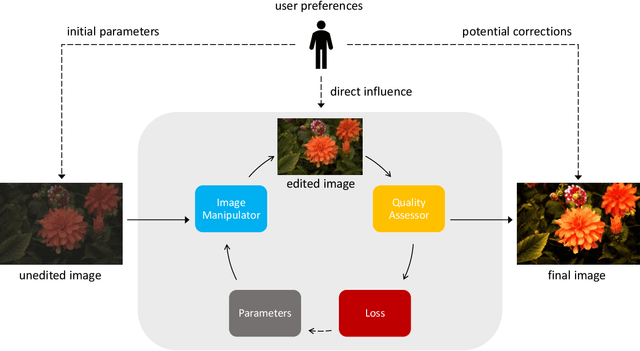
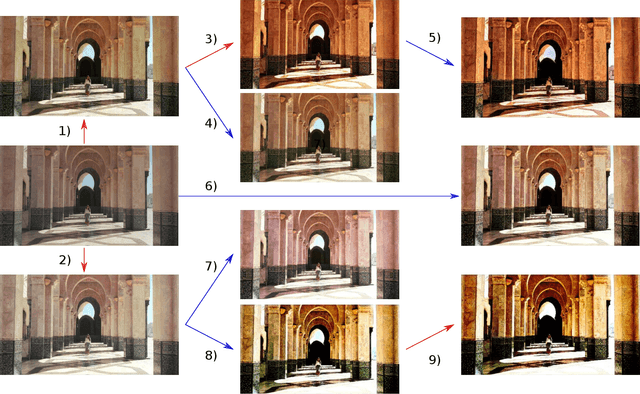
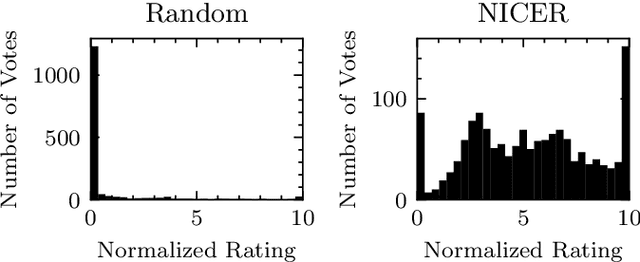

Fully- or semi-automatic image enhancement software helps users to increase the visual appeal of photos and does not require in-depth knowledge of manual image editing. However, fully-automatic approaches usually enhance the image in a black-box manner that does not give the user any control over the optimization process, possibly leading to edited images that do not subjectively appeal to the user. Semi-automatic methods mostly allow for controlling which pre-defined editing step is taken, which restricts the users in their creativity and ability to make detailed adjustments, such as brightness or contrast. We argue that incorporating user preferences by guiding an automated enhancement method simplifies image editing and increases the enhancement's focus on the user. This work thus proposes the Neural Image Correction & Enhancement Routine (NICER), a neural network based approach to no-reference image enhancement in a fully-, semi-automatic or fully manual process that is interactive and user-centered. NICER iteratively adjusts image editing parameters in order to maximize an aesthetic score based on image style and content. Users can modify these parameters at any time and guide the optimization process towards a desired direction. This interactive workflow is a novelty in the field of human-computer interaction for image enhancement tasks. In a user study, we show that NICER can improve image aesthetics without user interaction and that allowing user interaction leads to diverse enhancement outcomes that are strongly preferred over the unedited image. We make our code publicly available to facilitate further research in this direction.
* The code can be found at https://github.com/mr-Mojo/NICER