 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModernGBERT: German-only 1B Encoder Model Trained from Scratch
May 19, 2025



Despite the prominence of decoder-only language models, encoders remain crucial for resource-constrained applications. We introduce ModernGBERT (134M, 1B), a fully transparent family of German encoder models trained from scratch, incorporating architectural innovations from ModernBERT. To evaluate the practical trade-offs of training encoders from scratch, we also present LL\"aMmlein2Vec (120M, 1B, 7B), a family of encoders derived from German decoder-only models via LLM2Vec. We benchmark all models on natural language understanding, text embedding, and long-context reasoning tasks, enabling a controlled comparison between dedicated encoders and converted decoders. Our results show that ModernGBERT 1B outperforms prior state-of-the-art German encoders as well as encoders adapted via LLM2Vec, with regard to performance and parameter-efficiency. All models, training data, checkpoints and code are publicly available, advancing the German NLP ecosystem with transparent, high-performance encoder models.
Exploring Design Choices for Autoregressive Deep Learning Climate Models
May 05, 2025
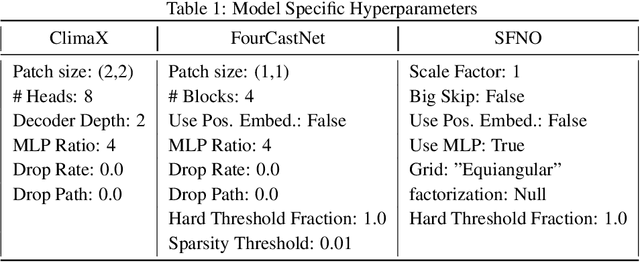


Deep Learning models have achieved state-of-the-art performance in medium-range weather prediction but often fail to maintain physically consistent rollouts beyond 14 days. In contrast, a few atmospheric models demonstrate stability over decades, though the key design choices enabling this remain unclear. This study quantitatively compares the long-term stability of three prominent DL-MWP architectures - FourCastNet, SFNO, and ClimaX - trained on ERA5 reanalysis data at 5.625{\deg} resolution. We systematically assess the impact of autoregressive training steps, model capacity, and choice of prognostic variables, identifying configurations that enable stable 10-year rollouts while preserving the statistical properties of the reference dataset. Notably, rollouts with SFNO exhibit the greatest robustness to hyperparameter choices, yet all models can experience instability depending on the random seed and the set of prognostic variables
LLäMmlein: Compact and Competitive German-Only Language Models from Scratch
Nov 17, 2024We create two German-only decoder models, LL\"aMmlein 120M and 1B, transparently from scratch and publish them, along with the training data, for the German NLP research community to use. The model training involved several key steps, including extensive data preprocessing, the creation of a custom German tokenizer, the training itself, as well as the evaluation of the final models on various benchmarks. Throughout the training process, multiple checkpoints were saved and analyzed using the SuperGLEBer benchmark to monitor the models' learning dynamics. Compared to state-of-the-art models on the SuperGLEBer benchmark, both LL\"aMmlein models performed competitively, consistently matching or surpassing models with similar parameter sizes. The results show that the models' quality scales with size as expected, but performance improvements on some tasks plateaued early, offering valuable insights into resource allocation for future model development.
Modeling and Analyzing the Influence of Non-Item Pages on Sequential Next-Item Prediction
Aug 28, 2024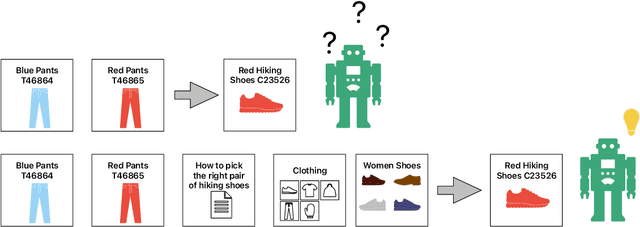



Analyzing the sequence of historical interactions between users and items, sequential recommendation models learn user intent and make predictions about the next item of interest. Next to these item interactions, most systems also have interactions with pages not related to specific items, for example navigation pages, account pages, and pages for a specific category, which may provide additional insights into the user's interests. However, while there are several approaches to integrate additional information about items and users, the topic of integrating non-item pages has been less explored. We use the hypotheses testing framework HypTrails to show that there is indeed a relationship between these non-item pages and the items of interest and fill this gap by proposing various approaches of representing non-item pages (e.g, based on their content) to use them as an additional information source for the task of sequential next-item prediction. We create a synthetic dataset with non-item pages highly related to the subsequent item to show that the models are generally capable of learning from these interactions, and subsequently evaluate the improvements gained by including non-item pages in two real-world datasets. We adapt eight popular sequential recommender models, covering CNN-, RNN- and transformer-based architectures, to integrate non-item pages and investigate the capabilities of these models to leverage their information for next item prediction. We also analyze their behavior on noisy data and compare different item representation strategies. Our results show that non-item pages are a valuable source of information, but representing such a page well is the key to successfully leverage them. The inclusion of non-item pages can increase the performance for next-item prediction in all examined model architectures with a varying degree.
Systematic Evaluation of Synthetic Data Augmentation for Multi-class NetFlow Traffic
Aug 28, 2024



The detection of cyber-attacks in computer networks is a crucial and ongoing research challenge. Machine learning-based attack classification offers a promising solution, as these models can be continuously updated with new data, enhancing the effectiveness of network intrusion detection systems (NIDS). Unlike binary classification models that simply indicate the presence of an attack, multi-class models can identify specific types of attacks, allowing for more targeted and effective incident responses. However, a significant drawback of these classification models is their sensitivity to imbalanced training data. Recent advances suggest that generative models can assist in data augmentation, claiming to offer superior solutions for imbalanced datasets. Classical balancing methods, although less novel, also provide potential remedies for this issue. Despite these claims, a comprehensive comparison of these methods within the NIDS domain is lacking. Most existing studies focus narrowly on individual methods, making it difficult to compare results due to varying experimental setups. To close this gap, we designed a systematic framework to compare classical and generative resampling methods for class balancing across multiple popular classification models in the NIDS domain, evaluated on several NIDS benchmark datasets. Our experiments indicate that resampling methods for balancing training data do not reliably improve classification performance. Although some instances show performance improvements, the majority of results indicate decreased performance, with no consistent trend in favor of a specific resampling technique enhancing a particular classifier.
ModeConv: A Novel Convolution for Distinguishing Anomalous and Normal Structural Behavior
Jun 28, 2024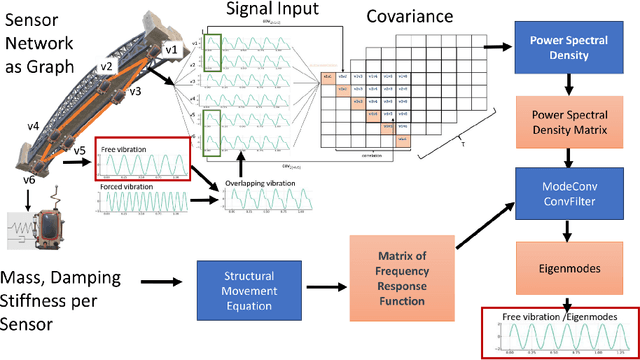
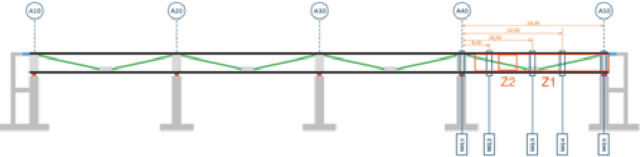
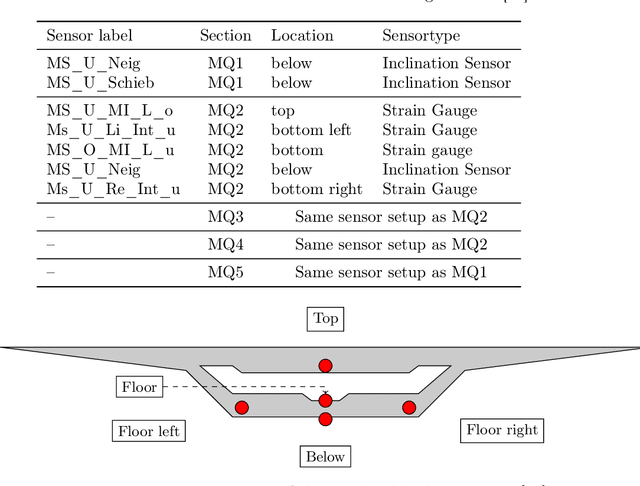
External influences such as traffic and environmental factors induce vibrations in structures, leading to material degradation over time. These vibrations result in cracks due to the material's lack of plasticity compromising structural integrity. Detecting such damage requires the installation of vibration sensors to capture the internal dynamics. However, distinguishing relevant eigenmodes from external noise necessitates the use of Deep Learning models. The detection of changes in eigenmodes can be used to anticipate these shifts in material properties and to discern between normal and anomalous structural behavior. Eigenmodes, representing characteristic vibration patterns, provide insights into structural dynamics and deviations from expected states. Thus, we propose ModeConv to automatically capture and analyze changes in eigenmodes, facilitating effective anomaly detection in structures and material properties. In the conducted experiments, ModeConv demonstrates computational efficiency improvements, resulting in reduced runtime for model calculations. The novel ModeConv neural network layer is tailored for temporal graph neural networks, in which every node represents one sensor. ModeConv employs a singular value decomposition based convolutional filter design for complex numbers and leverages modal transformation in lieu of Fourier or Laplace transformations in spectral graph convolutions. We include a mathematical complexity analysis illustrating the runtime reduction.
GrINd: Grid Interpolation Network for Scattered Observations
Mar 28, 2024



Predicting the evolution of spatiotemporal physical systems from sparse and scattered observational data poses a significant challenge in various scientific domains. Traditional methods rely on dense grid-structured data, limiting their applicability in scenarios with sparse observations. To address this challenge, we introduce GrINd (Grid Interpolation Network for Scattered Observations), a novel network architecture that leverages the high-performance of grid-based models by mapping scattered observations onto a high-resolution grid using a Fourier Interpolation Layer. In the high-resolution space, a NeuralPDE-class model predicts the system's state at future timepoints using differentiable ODE solvers and fully convolutional neural networks parametrizing the system's dynamics. We empirically evaluate GrINd on the DynaBench benchmark dataset, comprising six different physical systems observed at scattered locations, demonstrating its state-of-the-art performance compared to existing models. GrINd offers a promising approach for forecasting physical systems from sparse, scattered observational data, extending the applicability of deep learning methods to real-world scenarios with limited data availability.
Global Vegetation Modeling with Pre-Trained Weather Transformers
Mar 27, 2024



Accurate vegetation models can produce further insights into the complex interaction between vegetation activity and ecosystem processes. Previous research has established that long-term trends and short-term variability of temperature and precipitation affect vegetation activity. Motivated by the recent success of Transformer-based Deep Learning models for medium-range weather forecasting, we adapt the publicly available pre-trained FourCastNet to model vegetation activity while accounting for the short-term dynamics of climate variability. We investigate how the learned global representation of the atmosphere's state can be transferred to model the normalized difference vegetation index (NDVI). Our model globally estimates vegetation activity at a resolution of \SI{0.25}{\degree} while relying only on meteorological data. We demonstrate that leveraging pre-trained weather models improves the NDVI estimates compared to learning an NDVI model from scratch. Additionally, we compare our results to other recent data-driven NDVI modeling approaches from machine learning and ecology literature. We further provide experimental evidence on how much data and training time is necessary to turn FourCastNet into an effective vegetation model. Code and models will be made available upon publication.
BibSonomy Meets ChatLLMs for Publication Management: From Chat to Publication Management: Organizing your related work using BibSonomy & LLMs
Jan 17, 2024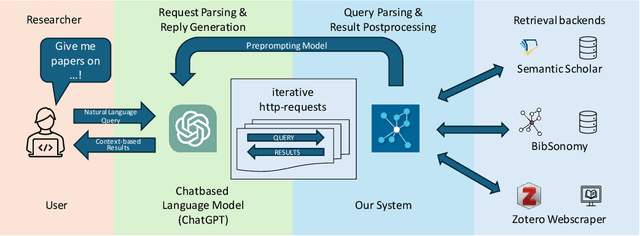



The ever-growing corpus of scientific literature presents significant challenges for researchers with respect to discovery, management, and annotation of relevant publications. Traditional platforms like Semantic Scholar, BibSonomy, and Zotero offer tools for literature management, but largely require manual laborious and error-prone input of tags and metadata. Here, we introduce a novel retrieval augmented generation system that leverages chat-based large language models (LLMs) to streamline and enhance the process of publication management. It provides a unified chat-based interface, enabling intuitive interactions with various backends, including Semantic Scholar, BibSonomy, and the Zotero Webscraper. It supports two main use-cases: (1) Explorative Search & Retrieval - leveraging LLMs to search for and retrieve both specific and general scientific publications, while addressing the challenges of content hallucination and data obsolescence; and (2) Cataloguing & Management - aiding in the organization of personal publication libraries, in this case BibSonomy, by automating the addition of metadata and tags, while facilitating manual edits and updates. We compare our system to different LLM models in three different settings, including a user study, and we can show its advantages in different metrics.
Higher-Order DeepTrails: Unified Approach to *Trails
Oct 06, 2023


Analyzing, understanding, and describing human behavior is advantageous in different settings, such as web browsing or traffic navigation. Understanding human behavior naturally helps to improve and optimize the underlying infrastructure or user interfaces. Typically, human navigation is represented by sequences of transitions between states. Previous work suggests to use hypotheses, representing different intuitions about the navigation to analyze these transitions. To mathematically grasp this setting, first-order Markov chains are used to capture the behavior, consequently allowing to apply different kinds of graph comparisons, but comes with the inherent drawback of losing information about higher-order dependencies within the sequences. To this end, we propose to analyze entire sequences using autoregressive language models, as they are traditionally used to model higher-order dependencies in sequences. We show that our approach can be easily adapted to model different settings introduced in previous work, namely HypTrails, MixedTrails and even SubTrails, while at the same time bringing unique advantages: 1. Modeling higher-order dependencies between state transitions, while 2. being able to identify short comings in proposed hypotheses, and 3. naturally introducing a unified approach to model all settings. To show the expressiveness of our approach, we evaluate our approach on different synthetic datasets and conclude with an exemplary analysis of a real-world dataset, examining the behavior of users who interact with voice assistants.