 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Design Choices for Autoregressive Deep Learning Climate Models
May 05, 2025Deep Learning models have achieved state-of-the-art performance in medium-range weather prediction but often fail to maintain physically consistent rollouts beyond 14 days. In contrast, a few atmospheric models demonstrate stability over decades, though the key design choices enabling this remain unclear. This study quantitatively compares the long-term stability of three prominent DL-MWP architectures - FourCastNet, SFNO, and ClimaX - trained on ERA5 reanalysis data at 5.625{\deg} resolution. We systematically assess the impact of autoregressive training steps, model capacity, and choice of prognostic variables, identifying configurations that enable stable 10-year rollouts while preserving the statistical properties of the reference dataset. Notably, rollouts with SFNO exhibit the greatest robustness to hyperparameter choices, yet all models can experience instability depending on the random seed and the set of prognostic variables
GrINd: Grid Interpolation Network for Scattered Observations
Mar 28, 2024Predicting the evolution of spatiotemporal physical systems from sparse and scattered observational data poses a significant challenge in various scientific domains. Traditional methods rely on dense grid-structured data, limiting their applicability in scenarios with sparse observations. To address this challenge, we introduce GrINd (Grid Interpolation Network for Scattered Observations), a novel network architecture that leverages the high-performance of grid-based models by mapping scattered observations onto a high-resolution grid using a Fourier Interpolation Layer. In the high-resolution space, a NeuralPDE-class model predicts the system's state at future timepoints using differentiable ODE solvers and fully convolutional neural networks parametrizing the system's dynamics. We empirically evaluate GrINd on the DynaBench benchmark dataset, comprising six different physical systems observed at scattered locations, demonstrating its state-of-the-art performance compared to existing models. GrINd offers a promising approach for forecasting physical systems from sparse, scattered observational data, extending the applicability of deep learning methods to real-world scenarios with limited data availability.
Global Vegetation Modeling with Pre-Trained Weather Transformers
Mar 27, 2024Accurate vegetation models can produce further insights into the complex interaction between vegetation activity and ecosystem processes. Previous research has established that long-term trends and short-term variability of temperature and precipitation affect vegetation activity. Motivated by the recent success of Transformer-based Deep Learning models for medium-range weather forecasting, we adapt the publicly available pre-trained FourCastNet to model vegetation activity while accounting for the short-term dynamics of climate variability. We investigate how the learned global representation of the atmosphere's state can be transferred to model the normalized difference vegetation index (NDVI). Our model globally estimates vegetation activity at a resolution of \SI{0.25}{\degree} while relying only on meteorological data. We demonstrate that leveraging pre-trained weather models improves the NDVI estimates compared to learning an NDVI model from scratch. Additionally, we compare our results to other recent data-driven NDVI modeling approaches from machine learning and ecology literature. We further provide experimental evidence on how much data and training time is necessary to turn FourCastNet into an effective vegetation model. Code and models will be made available upon publication.
TaylorPDENet: Learning PDEs from non-grid Data
Jun 26, 2023



Modeling data obtained from dynamical systems has gained attention in recent years as a challenging task for machine learning models. Previous approaches assume the measurements to be distributed on a grid. However, for real-world applications like weather prediction, the observations are taken from arbitrary locations within the spatial domain. In this paper, we propose TaylorPDENet - a novel machine learning method that is designed to overcome this challenge. Our algorithm uses the multidimensional Taylor expansion of a dynamical system at each observation point to estimate the spatial derivatives to perform predictions. TaylorPDENet is able to accomplish two objectives simultaneously: accurately forecast the evolution of a complex dynamical system and explicitly reconstruct the underlying differential equation describing the system. We evaluate our model on a variety of advection-diffusion equations with different parameters and show that it performs similarly to equivalent approaches on grid-structured data while being able to process unstructured data as well.
DynaBench: A benchmark dataset for learning dynamical systems from low-resolution data
Jun 09, 2023Previous work on learning physical systems from data has focused on high-resolution grid-structured measurements. However, real-world knowledge of such systems (e.g. weather data) relies on sparsely scattered measuring stations. In this paper, we introduce a novel simulated benchmark dataset, DynaBench, for learning dynamical systems directly from sparsely scattered data without prior knowledge of the equations. The dataset focuses on predicting the evolution of a dynamical system from low-resolution, unstructured measurements. We simulate six different partial differential equations covering a variety of physical systems commonly used in the literature and evaluate several machine learning models, including traditional graph neural networks and point cloud processing models, with the task of predicting the evolution of the system. The proposed benchmark dataset is expected to advance the state of art as an out-of-the-box easy-to-use tool for evaluating models in a setting where only unstructured low-resolution observations are available. The benchmark is available at https://anonymous.4open.science/r/code-2022-dynabench/.
Semi-unsupervised Learning for Time Series Classification
Jul 13, 2022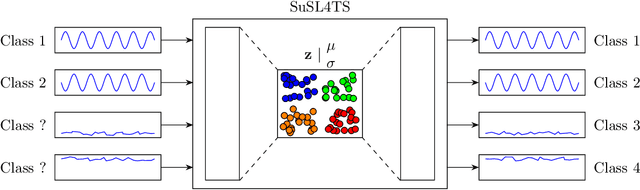


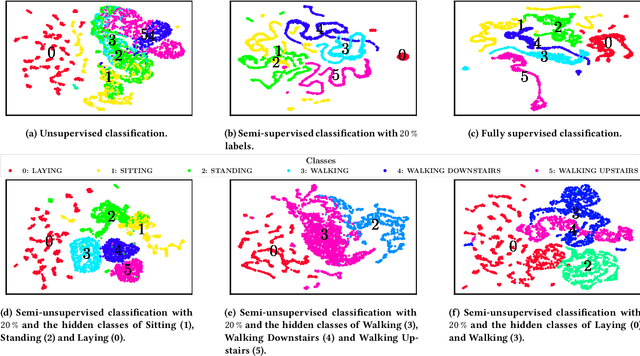
Time series are ubiquitous and therefore inherently hard to analyze and ultimately to label or cluster. With the rise of the Internet of Things (IoT) and its smart devices, data is collected in large amounts any given second. The collected data is rich in information, as one can detect accidents (e.g. cars) in real time, or assess injury/sickness over a given time span (e.g. health devices). Due to its chaotic nature and massive amounts of datapoints, timeseries are hard to label manually. Furthermore new classes within the data could emerge over time (contrary to e.g. handwritten digits), which would require relabeling the data. In this paper we present SuSL4TS, a deep generative Gaussian mixture model for semi-unsupervised learning, to classify time series data. With our approach we can alleviate manual labeling steps, since we can detect sparsely labeled classes (semi-supervised) and identify emerging classes hidden in the data (unsupervised). We demonstrate the efficacy of our approach with established time series classification datasets from different domains.
Open ERP System Data For Occupational Fraud Detection
Jun 10, 2022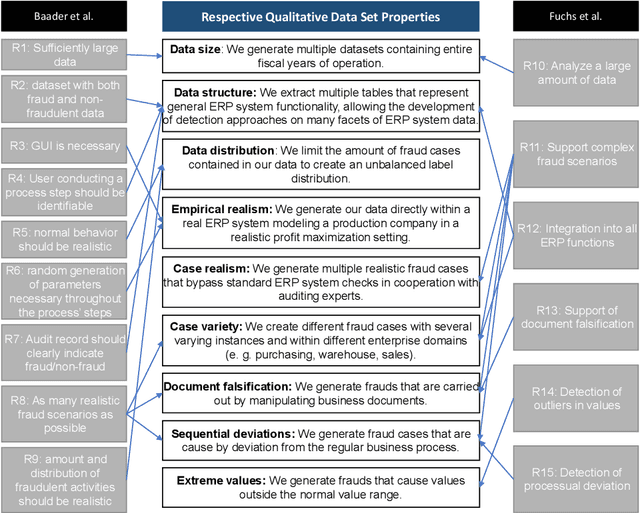
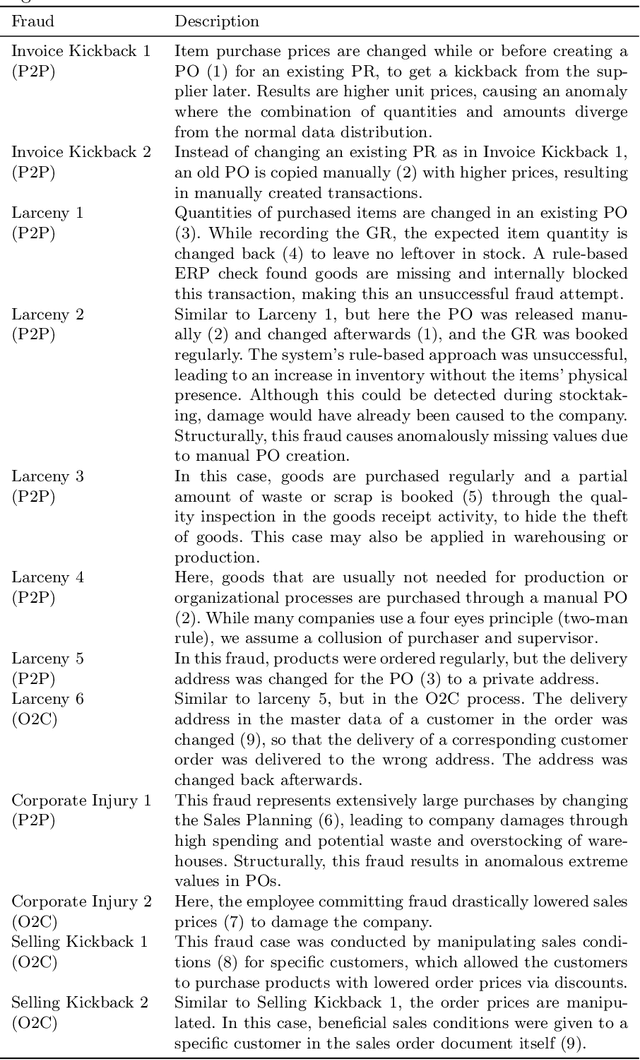

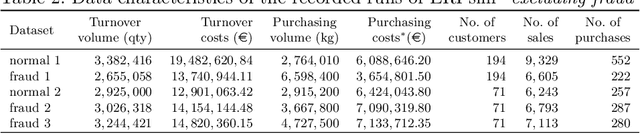
Recent estimates report that companies lose 5% of their revenue to occupational fraud. Since most medium-sized and large companies employ Enterprise Resource Planning (ERP) systems to track vast amounts of information regarding their business process, researchers have in the past shown interest in automatically detecting fraud through ERP system data. Current research in this area, however, is hindered by the fact that ERP system data is not publicly available for the development and comparison of fraud detection methods. We therefore endeavour to generate public ERP system data that includes both normal business operation and fraud. We propose a strategy for generating ERP system data through a serious game, model a variety of fraud scenarios in cooperation with auditing experts, and generate data from a simulated make-to-stock production company with multiple research participants. We aggregate the generated data into ready to used datasets for fraud detection in ERP systems, and supply both the raw and aggregated data to the general public to allow for open development and comparison of fraud detection approaches on ERP system data.
NeuralPDE: Modelling Dynamical Systems from Data
Nov 15, 2021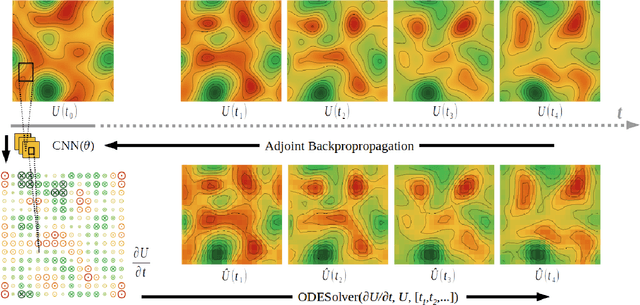
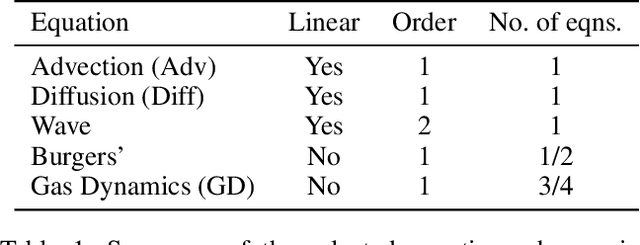

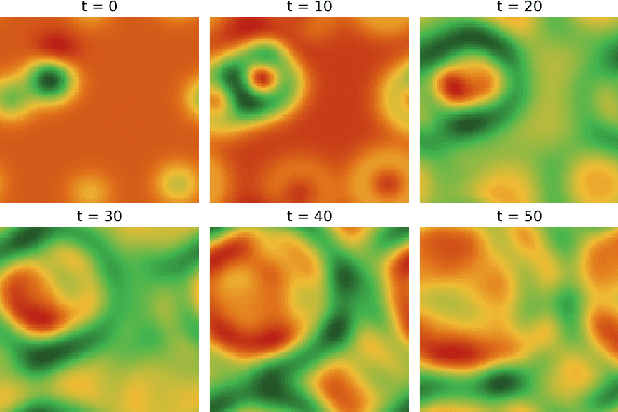
Many physical processes such as weather phenomena or fluid mechanics are governed by partial differential equations (PDEs). Modelling such dynamical systems using Neural Networks is an emerging research field. However, current methods are restricted in various ways: they require prior knowledge about the governing equations, and are limited to linear or first-order equations. In this work we propose NeuralPDE, a model which combines convolutional neural networks (CNNs) with differentiable ODE solvers to model dynamical systems. We show that the Method of Lines used in standard PDE solvers can be represented using convolutions which makes CNNs the natural choice to parametrize arbitrary PDE dynamics. Our model can be applied to any data without requiring any prior knowledge about the governing PDE. We evaluate NeuralPDE on datasets generated by solving a wide variety of PDEs, covering higher orders, non-linear equations and multiple spatial dimensions.
Anomaly Detection in Beehives: An Algorithm Comparison
Oct 08, 2021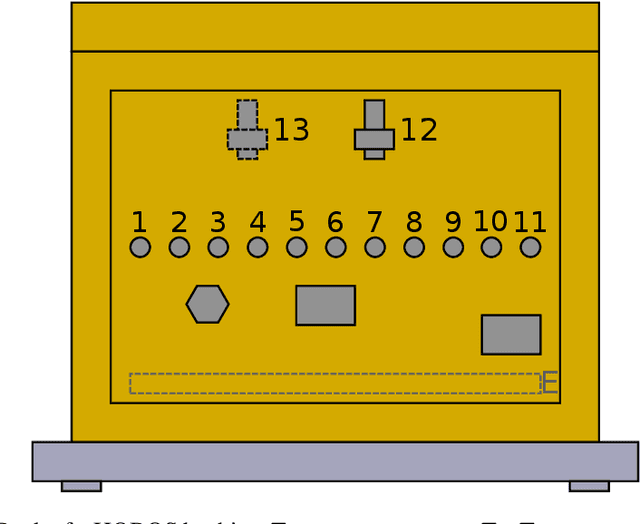
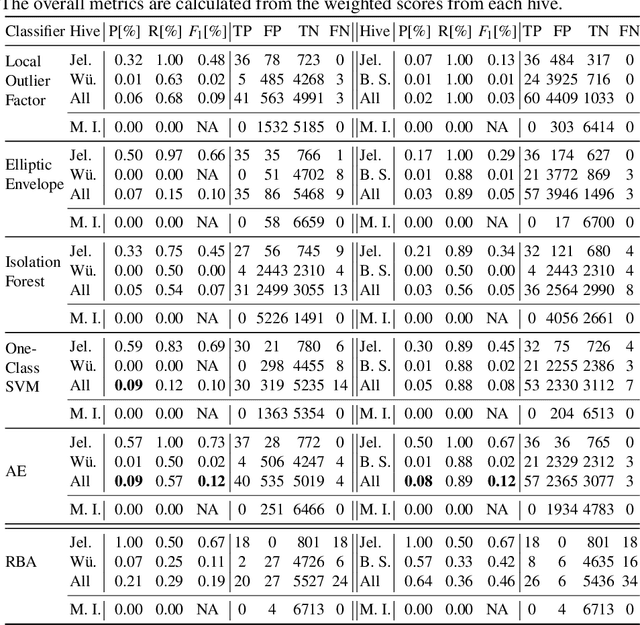
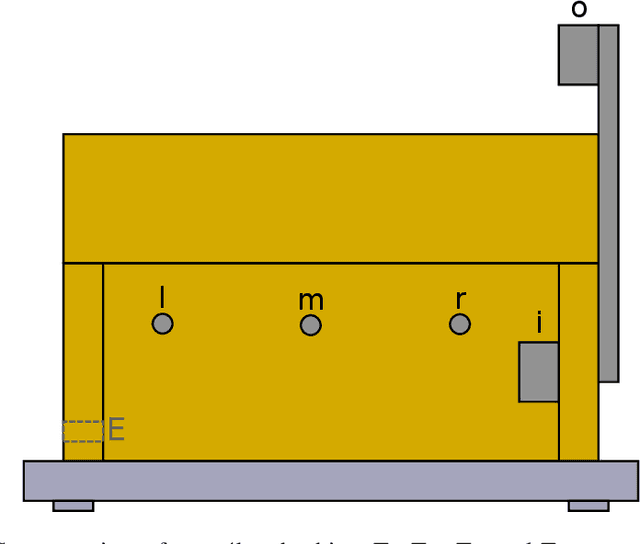
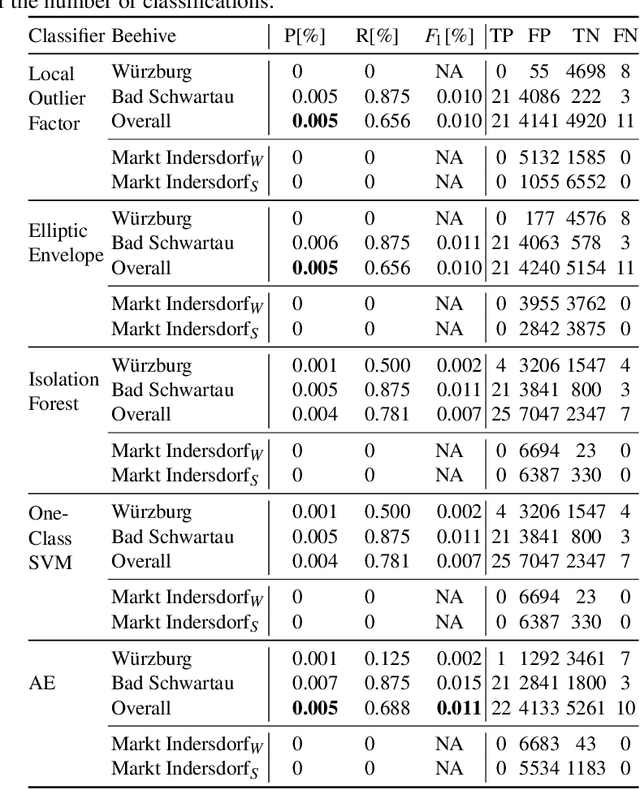
Sensor-equipped beehives allow monitoring the living conditions of bees. Machine learning models can use the data of such hives to learn behavioral patterns and find anomalous events. One type of event that is of particular interest to apiarists for economical reasons is bee swarming. Other events of interest are behavioral anomalies from illness and technical anomalies, e.g. sensor failure. Beekeepers can be supported by suitable machine learning models which can detect these events. In this paper we compare multiple machine learning models for anomaly detection and evaluate them for their applicability in the context of beehives. Namely we employed Deep Recurrent Autoencoder, Elliptic Envelope, Isolation Forest, Local Outlier Factor and One-Class SVM. Through evaluation with real world datasets of different hives and with different sensor setups we find that the autoencoder is the best multi-purpose anomaly detector in comparison.
Deep Learning for Climate Model Output Statistics
Dec 09, 2020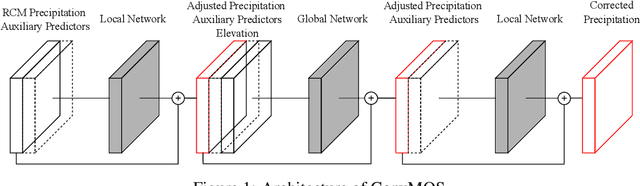
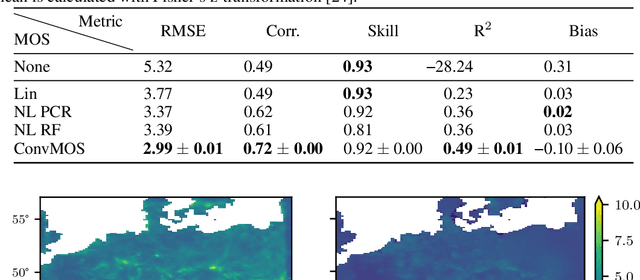
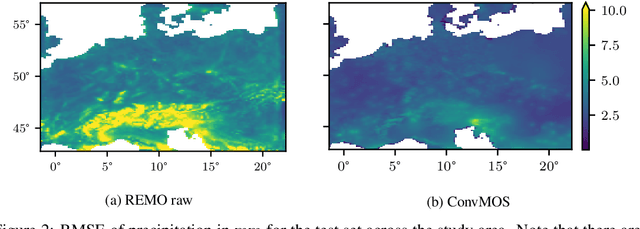

Climate models are an important tool for the assessment of prospective climate change effects but they suffer from systematic and representation errors, especially for precipitation. Model output statistics (MOS) reduce these errors by fitting the model output to observational data with machine learning. In this work, we explore the feasibility and potential of deep learning with convolutional neural networks (CNNs) for MOS. We propose the CNN architecture ConvMOS specifically designed for reducing errors in climate model outputs and apply it to the climate model REMO. Our results show a considerable reduction of errors and mostly improved performance compared to three commonly used MOS approaches.