 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling and Analyzing the Influence of Non-Item Pages on Sequential Next-Item Prediction
Aug 28, 2024Analyzing the sequence of historical interactions between users and items, sequential recommendation models learn user intent and make predictions about the next item of interest. Next to these item interactions, most systems also have interactions with pages not related to specific items, for example navigation pages, account pages, and pages for a specific category, which may provide additional insights into the user's interests. However, while there are several approaches to integrate additional information about items and users, the topic of integrating non-item pages has been less explored. We use the hypotheses testing framework HypTrails to show that there is indeed a relationship between these non-item pages and the items of interest and fill this gap by proposing various approaches of representing non-item pages (e.g, based on their content) to use them as an additional information source for the task of sequential next-item prediction. We create a synthetic dataset with non-item pages highly related to the subsequent item to show that the models are generally capable of learning from these interactions, and subsequently evaluate the improvements gained by including non-item pages in two real-world datasets. We adapt eight popular sequential recommender models, covering CNN-, RNN- and transformer-based architectures, to integrate non-item pages and investigate the capabilities of these models to leverage their information for next item prediction. We also analyze their behavior on noisy data and compare different item representation strategies. Our results show that non-item pages are a valuable source of information, but representing such a page well is the key to successfully leverage them. The inclusion of non-item pages can increase the performance for next-item prediction in all examined model architectures with a varying degree.
Systematic Evaluation of Synthetic Data Augmentation for Multi-class NetFlow Traffic
Aug 28, 2024



The detection of cyber-attacks in computer networks is a crucial and ongoing research challenge. Machine learning-based attack classification offers a promising solution, as these models can be continuously updated with new data, enhancing the effectiveness of network intrusion detection systems (NIDS). Unlike binary classification models that simply indicate the presence of an attack, multi-class models can identify specific types of attacks, allowing for more targeted and effective incident responses. However, a significant drawback of these classification models is their sensitivity to imbalanced training data. Recent advances suggest that generative models can assist in data augmentation, claiming to offer superior solutions for imbalanced datasets. Classical balancing methods, although less novel, also provide potential remedies for this issue. Despite these claims, a comprehensive comparison of these methods within the NIDS domain is lacking. Most existing studies focus narrowly on individual methods, making it difficult to compare results due to varying experimental setups. To close this gap, we designed a systematic framework to compare classical and generative resampling methods for class balancing across multiple popular classification models in the NIDS domain, evaluated on several NIDS benchmark datasets. Our experiments indicate that resampling methods for balancing training data do not reliably improve classification performance. Although some instances show performance improvements, the majority of results indicate decreased performance, with no consistent trend in favor of a specific resampling technique enhancing a particular classifier.
ModeConv: A Novel Convolution for Distinguishing Anomalous and Normal Structural Behavior
Jun 28, 2024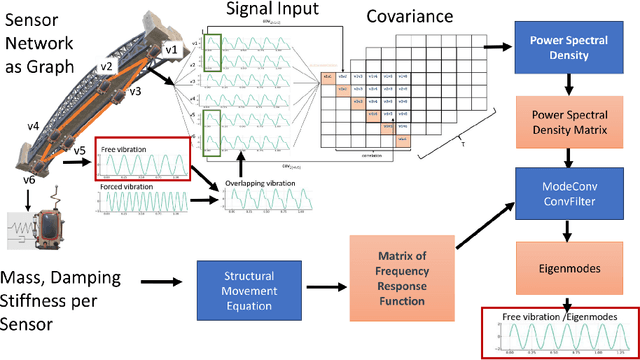
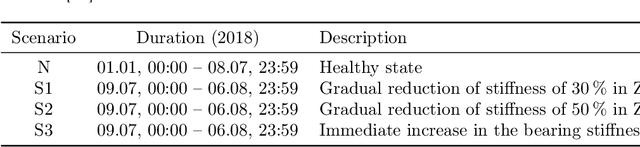
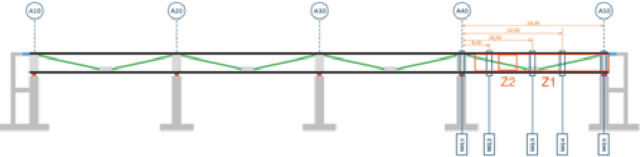
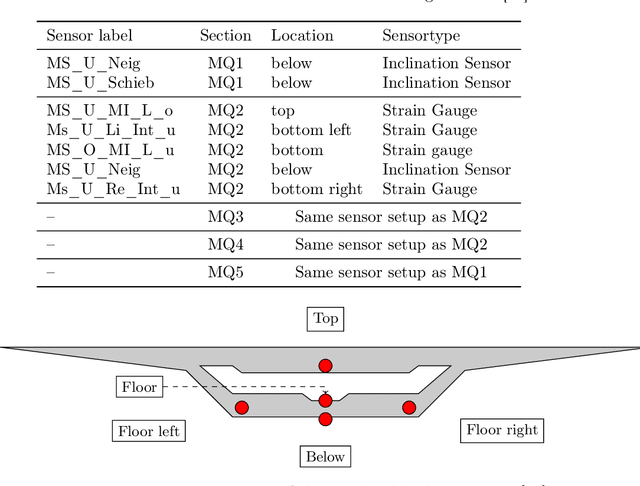
External influences such as traffic and environmental factors induce vibrations in structures, leading to material degradation over time. These vibrations result in cracks due to the material's lack of plasticity compromising structural integrity. Detecting such damage requires the installation of vibration sensors to capture the internal dynamics. However, distinguishing relevant eigenmodes from external noise necessitates the use of Deep Learning models. The detection of changes in eigenmodes can be used to anticipate these shifts in material properties and to discern between normal and anomalous structural behavior. Eigenmodes, representing characteristic vibration patterns, provide insights into structural dynamics and deviations from expected states. Thus, we propose ModeConv to automatically capture and analyze changes in eigenmodes, facilitating effective anomaly detection in structures and material properties. In the conducted experiments, ModeConv demonstrates computational efficiency improvements, resulting in reduced runtime for model calculations. The novel ModeConv neural network layer is tailored for temporal graph neural networks, in which every node represents one sensor. ModeConv employs a singular value decomposition based convolutional filter design for complex numbers and leverages modal transformation in lieu of Fourier or Laplace transformations in spectral graph convolutions. We include a mathematical complexity analysis illustrating the runtime reduction.
Open ERP System Data For Occupational Fraud Detection
Jun 10, 2022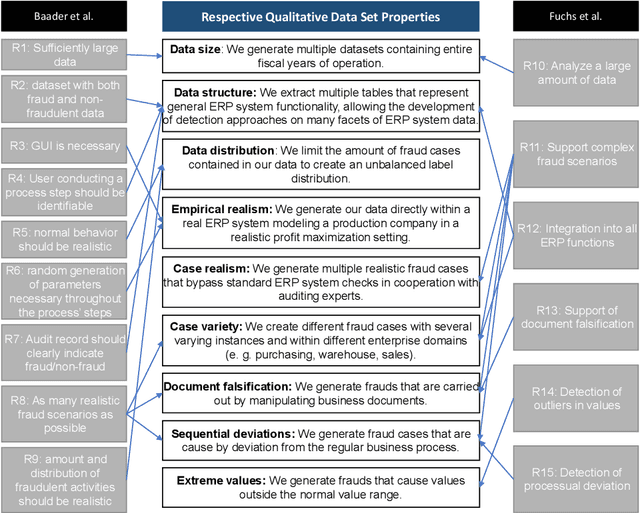
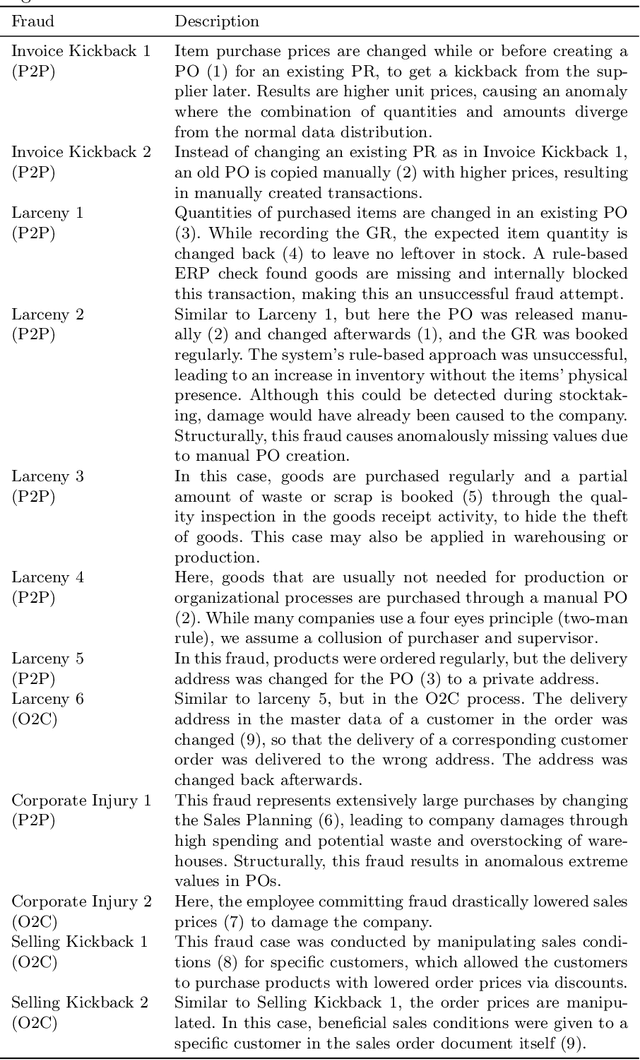

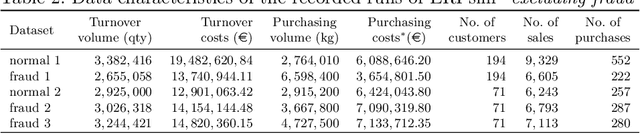
Recent estimates report that companies lose 5% of their revenue to occupational fraud. Since most medium-sized and large companies employ Enterprise Resource Planning (ERP) systems to track vast amounts of information regarding their business process, researchers have in the past shown interest in automatically detecting fraud through ERP system data. Current research in this area, however, is hindered by the fact that ERP system data is not publicly available for the development and comparison of fraud detection methods. We therefore endeavour to generate public ERP system data that includes both normal business operation and fraud. We propose a strategy for generating ERP system data through a serious game, model a variety of fraud scenarios in cooperation with auditing experts, and generate data from a simulated make-to-stock production company with multiple research participants. We aggregate the generated data into ready to used datasets for fraud detection in ERP systems, and supply both the raw and aggregated data to the general public to allow for open development and comparison of fraud detection approaches on ERP system data.
iNALU: Improved Neural Arithmetic Logic Unit
Mar 17, 2020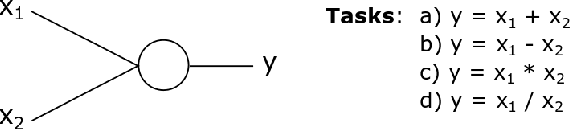
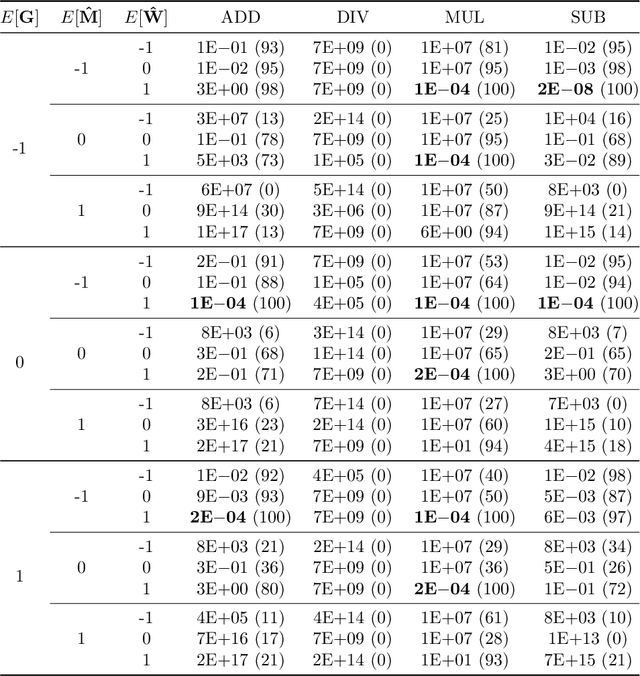
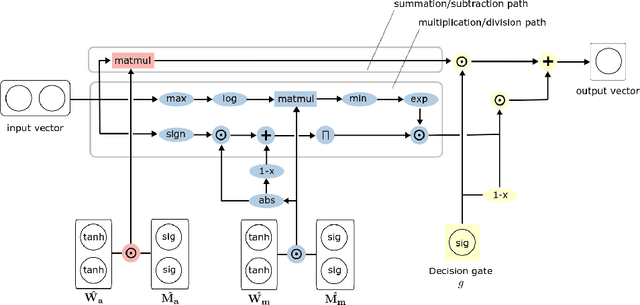
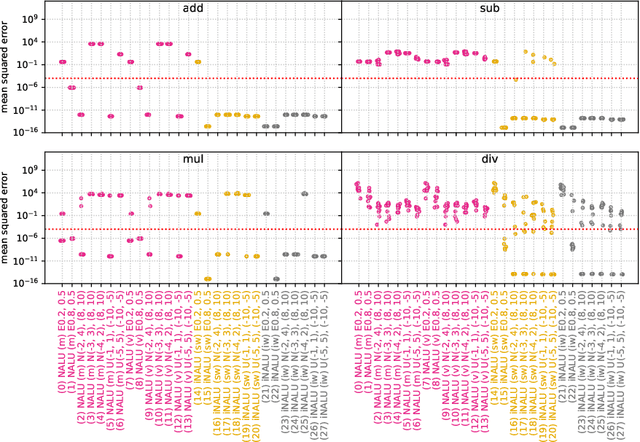
Neural networks have to capture mathematical relationships in order to learn various tasks. They approximate these relations implicitly and therefore often do not generalize well. The recently proposed Neural Arithmetic Logic Unit (NALU) is a novel neural architecture which is able to explicitly represent the mathematical relationships by the units of the network to learn operations such as summation, subtraction or multiplication. Although NALUs have been shown to perform well on various downstream tasks, an in-depth analysis reveals practical shortcomings by design, such as the inability to multiply or divide negative input values or training stability issues for deeper networks. We address these issues and propose an improved model architecture. We evaluate our model empirically in various settings from learning basic arithmetic operations to more complex functions. Our experiments indicate that our model solves stability issues and outperforms the original NALU model in means of arithmetic precision and convergence.
Flow-based Network Traffic Generation using Generative Adversarial Networks
Sep 27, 2018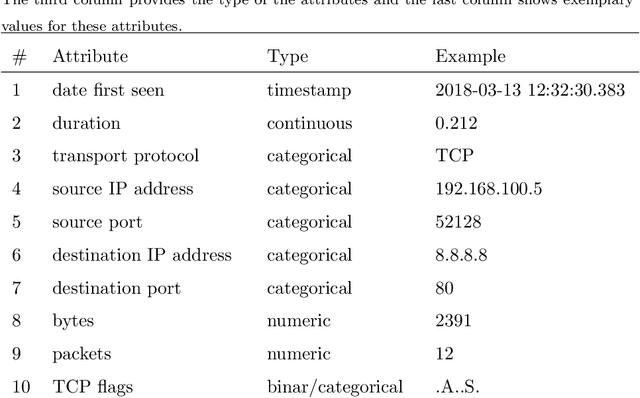



Flow-based data sets are necessary for evaluating network-based intrusion detection systems (NIDS). In this work, we propose a novel methodology for generating realistic flow-based network traffic. Our approach is based on Generative Adversarial Networks (GANs) which achieve good results for image generation. A major challenge lies in the fact that GANs can only process continuous attributes. However, flow-based data inevitably contain categorical attributes such as IP addresses or port numbers. Therefore, we propose three different preprocessing approaches for flow-based data in order to transform them into continuous values. Further, we present a new method for evaluating the generated flow-based network traffic which uses domain knowledge to define quality tests. We use the three approaches for generating flow-based network traffic based on the CIDDS-001 data set. Experiments indicate that two of the three approaches are able to generate high quality data.