 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling and Analyzing the Influence of Non-Item Pages on Sequential Next-Item Prediction
Aug 28, 2024



Analyzing the sequence of historical interactions between users and items, sequential recommendation models learn user intent and make predictions about the next item of interest. Next to these item interactions, most systems also have interactions with pages not related to specific items, for example navigation pages, account pages, and pages for a specific category, which may provide additional insights into the user's interests. However, while there are several approaches to integrate additional information about items and users, the topic of integrating non-item pages has been less explored. We use the hypotheses testing framework HypTrails to show that there is indeed a relationship between these non-item pages and the items of interest and fill this gap by proposing various approaches of representing non-item pages (e.g, based on their content) to use them as an additional information source for the task of sequential next-item prediction. We create a synthetic dataset with non-item pages highly related to the subsequent item to show that the models are generally capable of learning from these interactions, and subsequently evaluate the improvements gained by including non-item pages in two real-world datasets. We adapt eight popular sequential recommender models, covering CNN-, RNN- and transformer-based architectures, to integrate non-item pages and investigate the capabilities of these models to leverage their information for next item prediction. We also analyze their behavior on noisy data and compare different item representation strategies. Our results show that non-item pages are a valuable source of information, but representing such a page well is the key to successfully leverage them. The inclusion of non-item pages can increase the performance for next-item prediction in all examined model architectures with a varying degree.
Towards a Computational Analysis of Suspense: Detecting Dangerous Situations
May 11, 2023



Suspense is an important tool in storytelling to keep readers engaged and wanting to read more. However, it has so far not been studied extensively in Computational Literary Studies. In this paper, we focus on one of the elements authors can use to build up suspense: dangerous situations. We introduce a corpus of texts annotated with dangerous situations, distinguishing between 7 types of danger. Additionally, we annotate parts of the text that describe fear experienced by a character, regardless of the actual presence of danger. We present experiments towards the automatic detection of these situations, finding that unsupervised baseline methods can provide valuable signals for the detection, but more complex methods are necessary for further analysis. Not unexpectedly, the description of danger and fear often relies heavily on the context, both local (e.g., situations where danger is only mentioned, but not actually present) and global (e.g., "storm" being used in a literal sense in an adventure novel, but metaphorically in a romance novel).
One Graph to Rule them All: Using NLP and Graph Neural Networks to analyse Tolkien's Legendarium
Oct 14, 2022
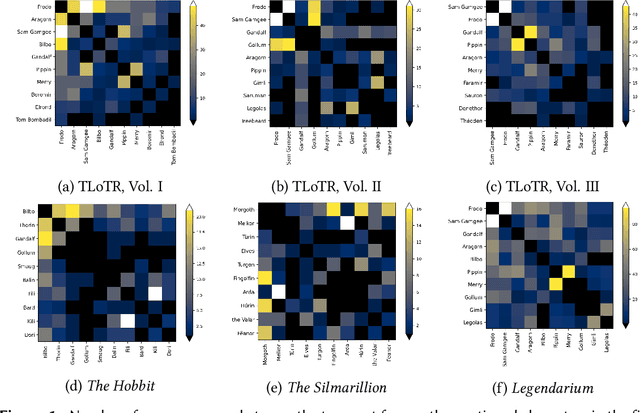

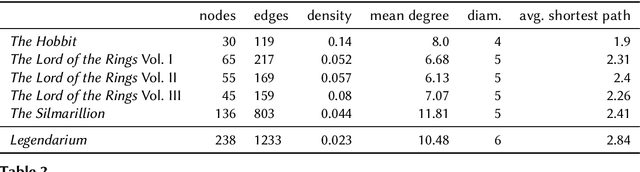
Natural Language Processing and Machine Learning have considerably advanced Computational Literary Studies. Similarly, the construction of co-occurrence networks of literary characters, and their analysis using methods from social network analysis and network science, have provided insights into the micro- and macro-level structure of literary texts. Combining these perspectives, in this work we study character networks extracted from a text corpus of J.R.R. Tolkien's Legendarium. We show that this perspective helps us to analyse and visualise the narrative style that characterises Tolkien's works. Addressing character classification, embedding and co-occurrence prediction, we further investigate the advantages of state-of-the-art Graph Neural Networks over a popular word embedding method. Our results highlight the large potential of graph learning in Computational Literary Studies.
SimLoss: Class Similarities in Cross Entropy
Mar 06, 2020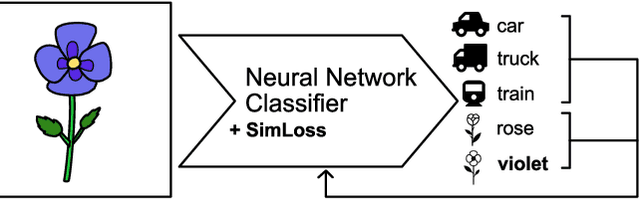
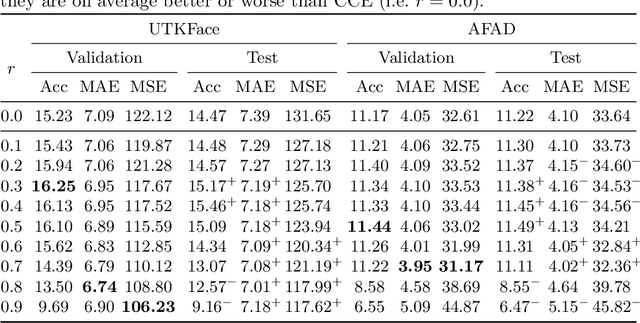
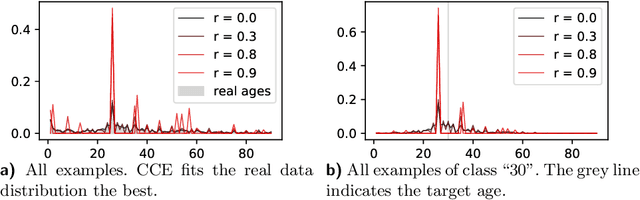
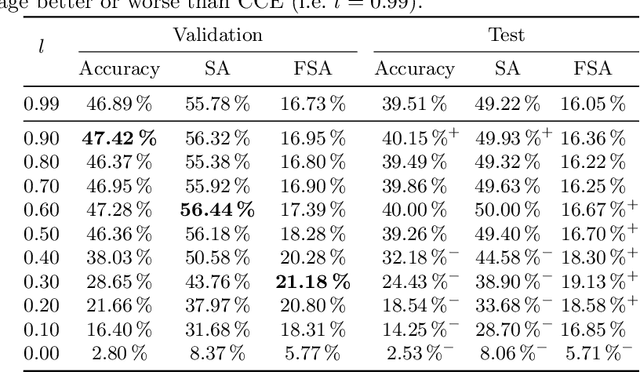
One common loss function in neural network classification tasks is Categorical Cross Entropy (CCE), which punishes all misclassifications equally. However, classes often have an inherent structure. For instance, classifying an image of a rose as "violet" is better than as "truck". We introduce SimLoss, a drop-in replacement for CCE that incorporates class similarities along with two techniques to construct such matrices from task-specific knowledge. We test SimLoss on Age Estimation and Image Classification and find that it brings significant improvements over CCE on several metrics. SimLoss therefore allows for explicit modeling of background knowledge by simply exchanging the loss function, while keeping the neural network architecture the same. Code and additional resources can be found at https://github.com/konstantinkobs/SimLoss.
MapLUR: Exploring a new Paradigm for Estimating Air Pollution using Deep Learning on Map Images
Feb 18, 2020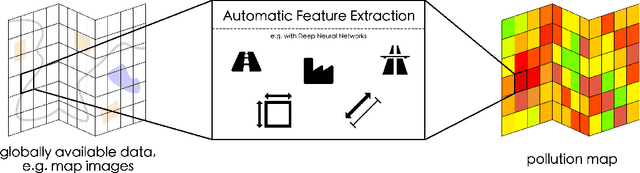
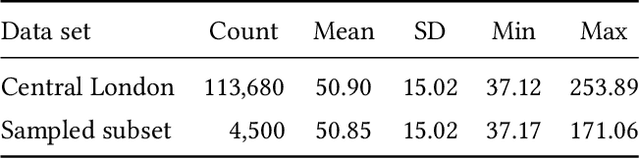

Land-use regression (LUR) models are important for the assessment of air pollution concentrations in areas without measurement stations. While many such models exist, they often use manually constructed features based on restricted, locally available data. Thus, they are typically hard to reproduce and challenging to adapt to areas beyond those they have been developed for. In this paper, we advocate a paradigm shift for LUR models: We propose the Data-driven, Open, Global (DOG) paradigm that entails models based on purely data-driven approaches using only openly and globally available data. Progress within this paradigm will alleviate the need for experts to adapt models to the local characteristics of the available data sources and thus facilitate the generalizability of air pollution models to new areas on a global scale. In order to illustrate the feasibility of the DOG paradigm for LUR, we introduce a deep learning model called MapLUR. It is based on a convolutional neural network architecture and is trained exclusively on globally and openly available map data without requiring manual feature engineering. We compare our model to state-of-the-art baselines like linear regression, random forests and multi-layer perceptrons using a large data set of modeled $\text{NO}_2$ concentrations in Central London. Our results show that MapLUR significantly outperforms these approaches even though they are provided with manually tailored features. Furthermore, we illustrate that the automatic feature extraction inherent to models based on the DOG paradigm can learn features that are readily interpretable and closely resemble those commonly used in traditional LUR approaches.
ClaiRE at SemEval-2018 Task 7 - Extended Version
May 15, 2018
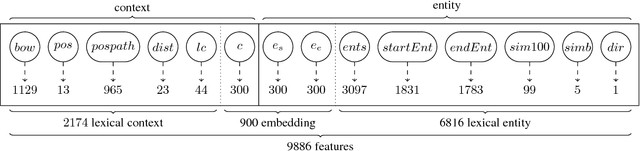
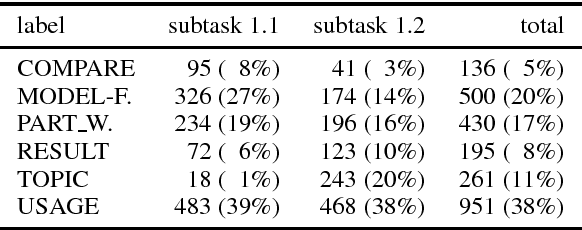
In this paper we describe our post-evaluation results for SemEval-2018 Task 7 on clas- sification of semantic relations in scientific literature for clean (subtask 1.1) and noisy data (subtask 1.2). This is an extended ver- sion of our workshop paper (Hettinger et al., 2018) including further technical details (Sec- tions 3.2 and 4.3) and changes made to the preprocessing step in the post-evaluation phase (Section 2.1). Due to these changes Classification of Relations using Embeddings (ClaiRE) achieved an improved F1 score of 75.11% for the first subtask and 81.44% for the second.
Analyzing Features for the Detection of Happy Endings in German Novels
Nov 28, 2016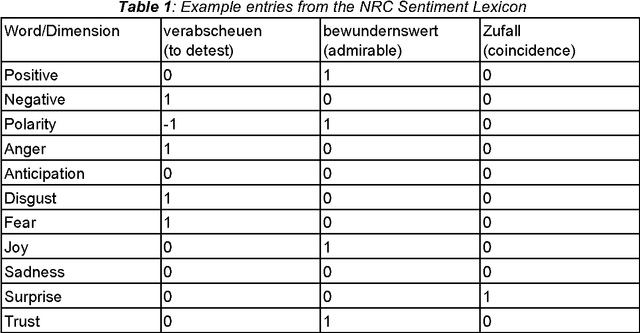
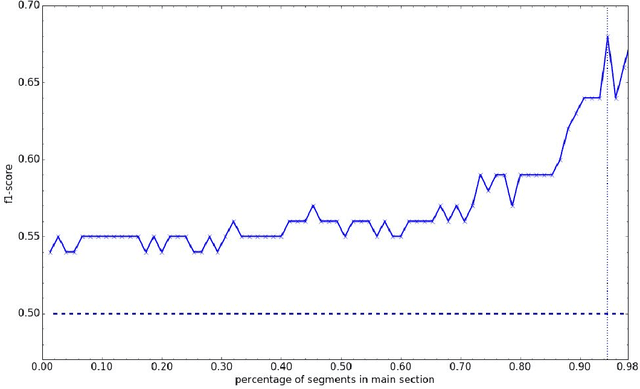
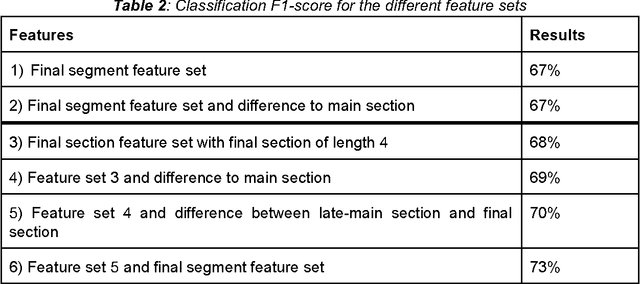
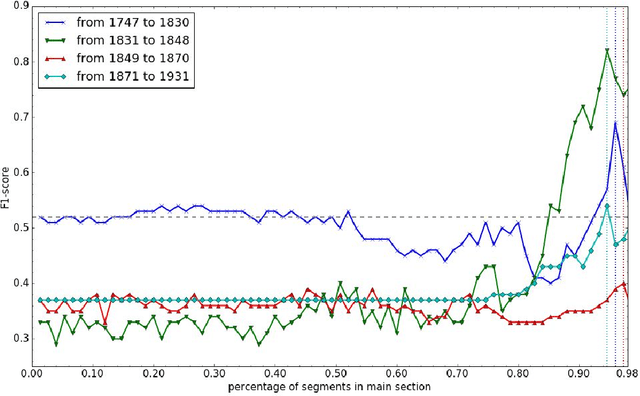
With regard to a computational representation of literary plot, this paper looks at the use of sentiment analysis for happy ending detection in German novels. Its focus lies on the investigation of previously proposed sentiment features in order to gain insight about the relevance of specific features on the one hand and the implications of their performance on the other hand. Therefore, we study various partitionings of novels, considering the highly variable concept of "ending". We also show that our approach, even though still rather simple, can potentially lead to substantial findings relevant to literary studies.