 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Item Recommendation in the MOBA Game Dota 2
Jan 17, 2022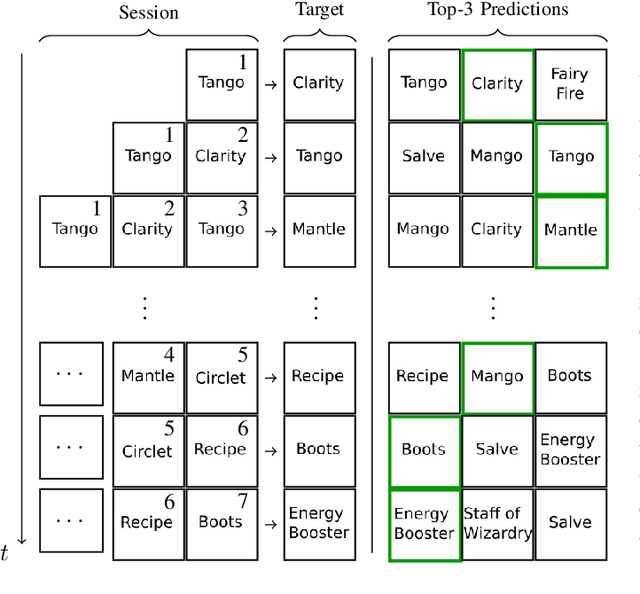
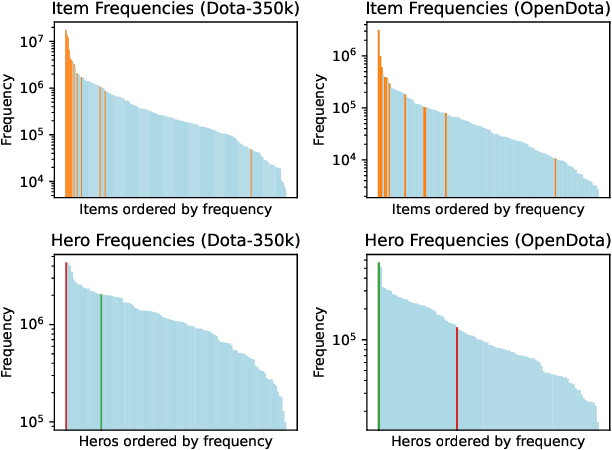
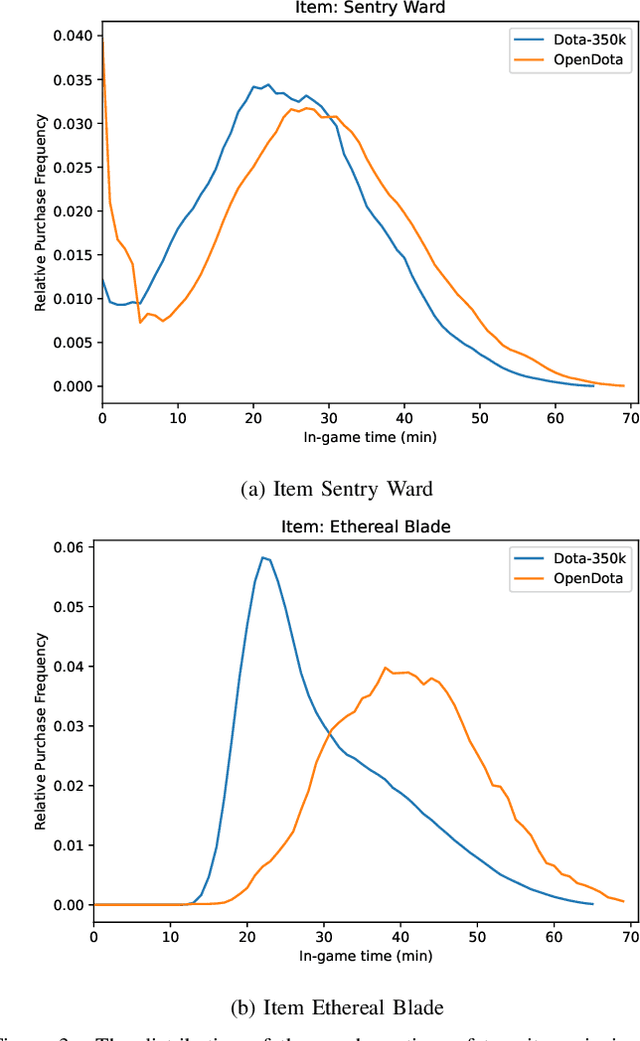
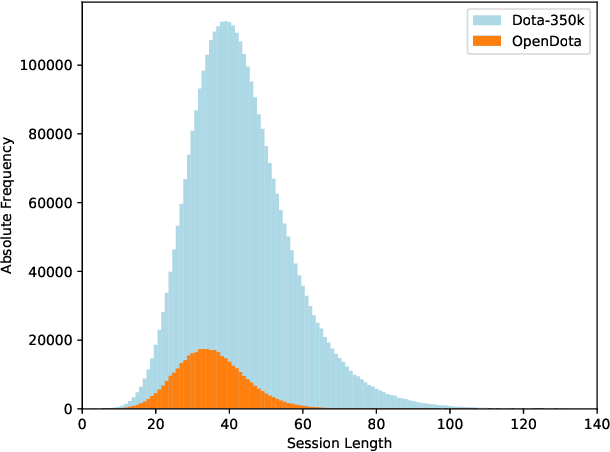
Multiplayer Online Battle Arena (MOBA) games such as Dota 2 attract hundreds of thousands of players every year. Despite the large player base, it is still important to attract new players to prevent the community of a game from becoming inactive. Entering MOBA games is, however, often demanding, requiring the player to learn numerous skills at once. An important factor of success is buying the correct items which forms a complex task depending on various in-game factors such as already purchased items, the team composition, or available resources. A recommendation system can support players by reducing the mental effort required to choose a suitable item, helping, e.g., newer players or players returning to the game after a longer break, to focus on other aspects of the game. Since Sequential Item Recommendation (SIR) has proven to be effective in various domains (e.g. e-commerce, movie recommendation or playlist continuation), we explore the applicability of well-known SIR models in the context of purchase recommendations in Dota 2. To facilitate this research, we collect, analyze and publish Dota-350k, a new large dataset based on recent Dota 2 matches. We find that SIR models can be employed effectively for item recommendation in Dota 2. Our results show that models that consider the order of purchases are the most effective. In contrast to other domains, we find RNN-based models to outperform the more recent Transformer-based architectures on Dota-350k.
A Case Study on Sampling Strategies for Evaluating Neural Sequential Item Recommendation Models
Jul 27, 2021
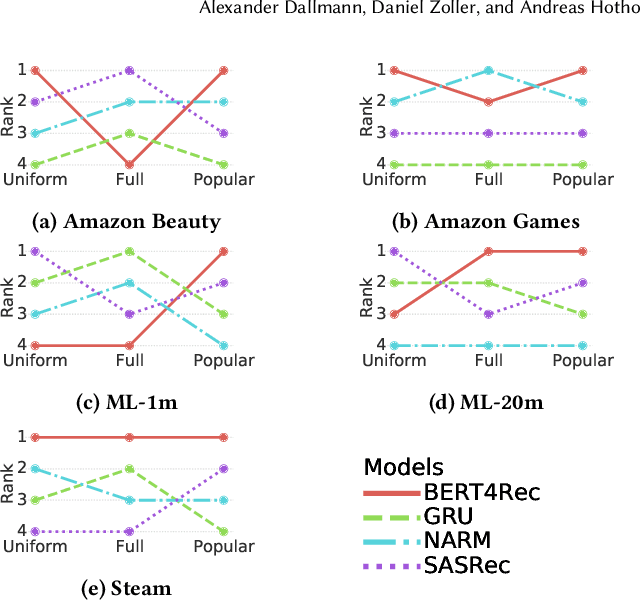
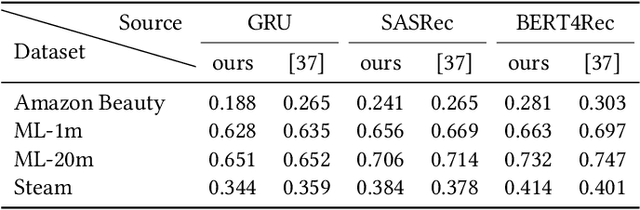
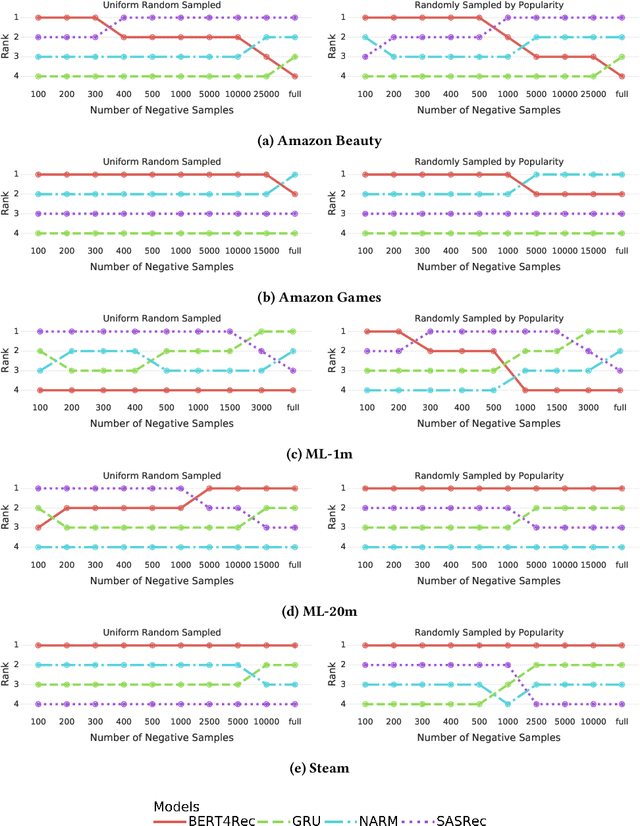
At the present time, sequential item recommendation models are compared by calculating metrics on a small item subset (target set) to speed up computation. The target set contains the relevant item and a set of negative items that are sampled from the full item set. Two well-known strategies to sample negative items are uniform random sampling and sampling by popularity to better approximate the item frequency distribution in the dataset. Most recently published papers on sequential item recommendation rely on sampling by popularity to compare the evaluated models. However, recent work has already shown that an evaluation with uniform random sampling may not be consistent with the full ranking, that is, the model ranking obtained by evaluating a metric using the full item set as target set, which raises the question whether the ranking obtained by sampling by popularity is equal to the full ranking. In this work, we re-evaluate current state-of-the-art sequential recommender models from the point of view, whether these sampling strategies have an impact on the final ranking of the models. We therefore train four recently proposed sequential recommendation models on five widely known datasets. For each dataset and model, we employ three evaluation strategies. First, we compute the full model ranking. Then we evaluate all models on a target set sampled by the two different sampling strategies, uniform random sampling and sampling by popularity with the commonly used target set size of 100, compute the model ranking for each strategy and compare them with each other. Additionally, we vary the size of the sampled target set. Overall, we find that both sampling strategies can produce inconsistent rankings compared with the full ranking of the models. Furthermore, both sampling by popularity and uniform random sampling do not consistently produce the same ranking ...
ClaiRE at SemEval-2018 Task 7 - Extended Version
May 15, 2018
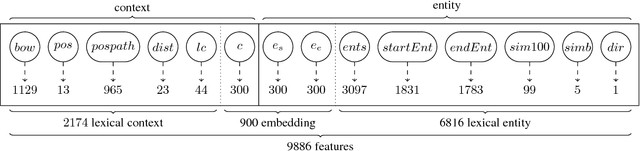
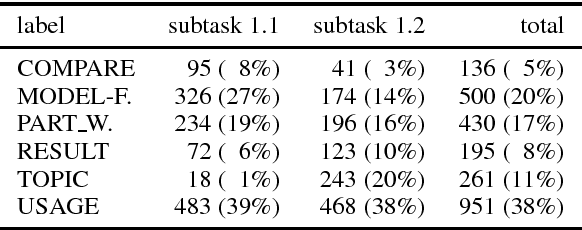
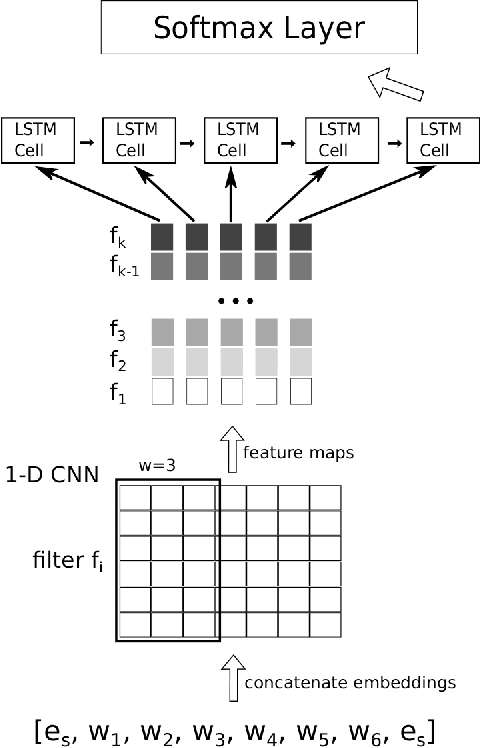
In this paper we describe our post-evaluation results for SemEval-2018 Task 7 on clas- sification of semantic relations in scientific literature for clean (subtask 1.1) and noisy data (subtask 1.2). This is an extended ver- sion of our workshop paper (Hettinger et al., 2018) including further technical details (Sec- tions 3.2 and 4.3) and changes made to the preprocessing step in the post-evaluation phase (Section 2.1). Due to these changes Classification of Relations using Embeddings (ClaiRE) achieved an improved F1 score of 75.11% for the first subtask and 81.44% for the second.
Improving Session Recommendation with Recurrent Neural Networks by Exploiting Dwell Time
Jun 30, 2017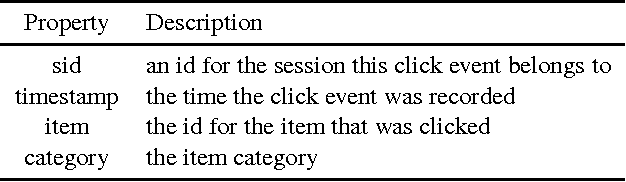
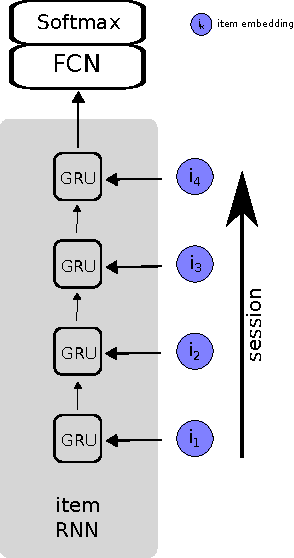
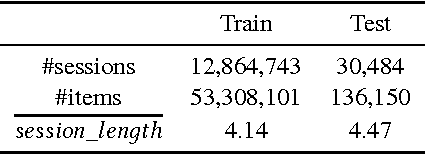
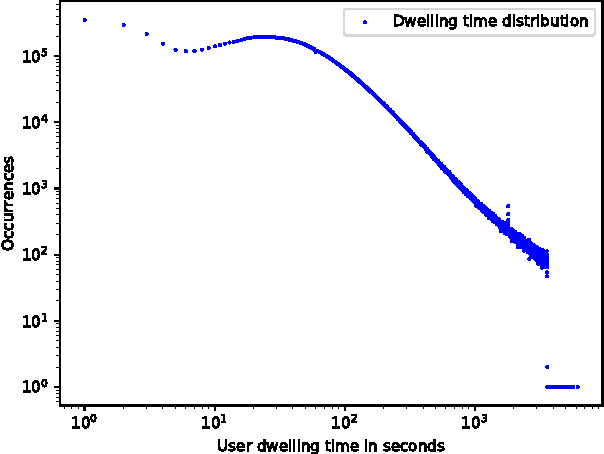
Recently, Recurrent Neural Networks (RNNs) have been applied to the task of session-based recommendation. These approaches use RNNs to predict the next item in a user session based on the previ- ously visited items. While some approaches consider additional item properties, we argue that item dwell time can be used as an implicit measure of user interest to improve session-based item recommen- dations. We propose an extension to existing RNN approaches that captures user dwell time in addition to the visited items and show that recommendation performance can be improved. Additionally, we investigate the usefulness of a single validation split for model selection in the case of minor improvements and find that in our case the best model is not selected and a fold-like study with different validation sets is necessary to ensure the selection of the best model.