 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Session Recommendation with Recurrent Neural Networks by Exploiting Dwell Time
Jun 30, 2017
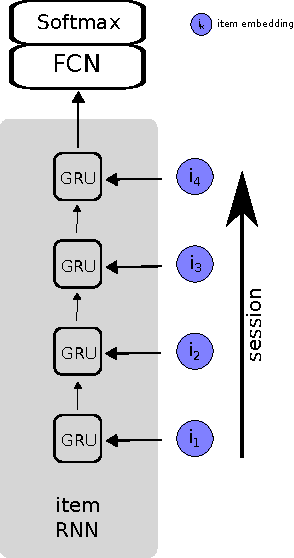
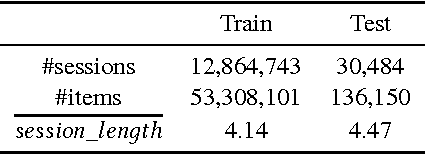
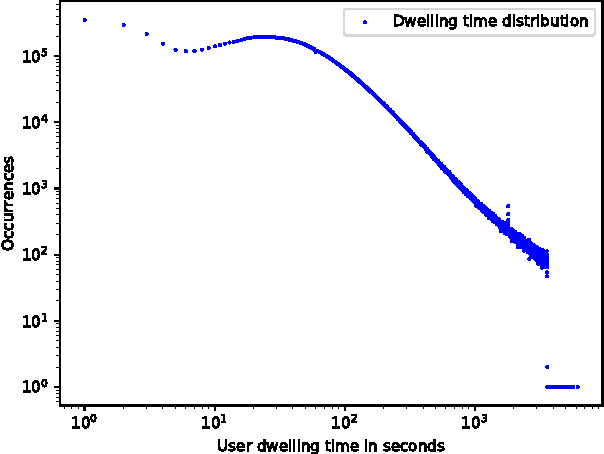
Recently, Recurrent Neural Networks (RNNs) have been applied to the task of session-based recommendation. These approaches use RNNs to predict the next item in a user session based on the previ- ously visited items. While some approaches consider additional item properties, we argue that item dwell time can be used as an implicit measure of user interest to improve session-based item recommen- dations. We propose an extension to existing RNN approaches that captures user dwell time in addition to the visited items and show that recommendation performance can be improved. Additionally, we investigate the usefulness of a single validation split for model selection in the case of minor improvements and find that in our case the best model is not selected and a fold-like study with different validation sets is necessary to ensure the selection of the best model.
Learning Semantic Relatedness From Human Feedback Using Metric Learning
May 24, 2017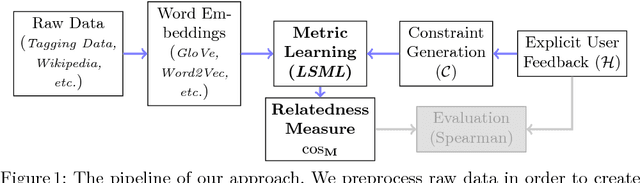
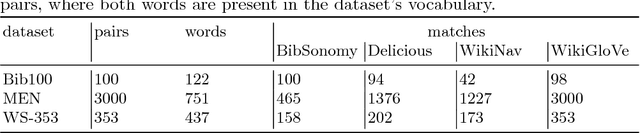
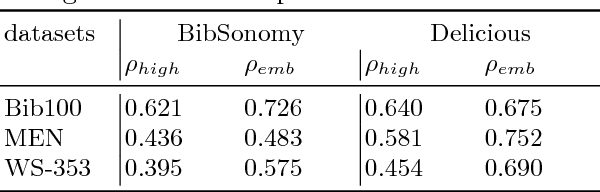
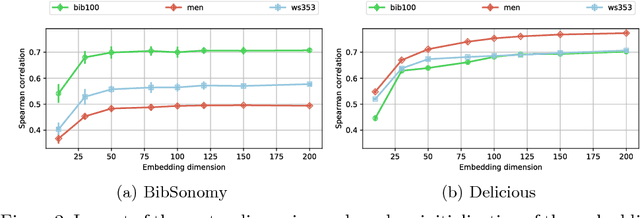
Assessing the degree of semantic relatedness between words is an important task with a variety of semantic applications, such as ontology learning for the Semantic Web, semantic search or query expansion. To accomplish this in an automated fashion, many relatedness measures have been proposed. However, most of these metrics only encode information contained in the underlying corpus and thus do not directly model human intuition. To solve this, we propose to utilize a metric learning approach to improve existing semantic relatedness measures by learning from additional information, such as explicit human feedback. For this, we argue to use word embeddings instead of traditional high-dimensional vector representations in order to leverage their semantic density and to reduce computational cost. We rigorously test our approach on several domains including tagging data as well as publicly available embeddings based on Wikipedia texts and navigation. Human feedback about semantic relatedness for learning and evaluation is extracted from publicly available datasets such as MEN or WS-353. We find that our method can significantly improve semantic relatedness measures by learning from additional information, such as explicit human feedback. For tagging data, we are the first to generate and study embeddings. Our results are of special interest for ontology and recommendation engineers, but also for any other researchers and practitioners of Semantic Web techniques.
Machine Learning meets Data-Driven Journalism: Boosting International Understanding and Transparency in News Coverage
Jun 16, 2016
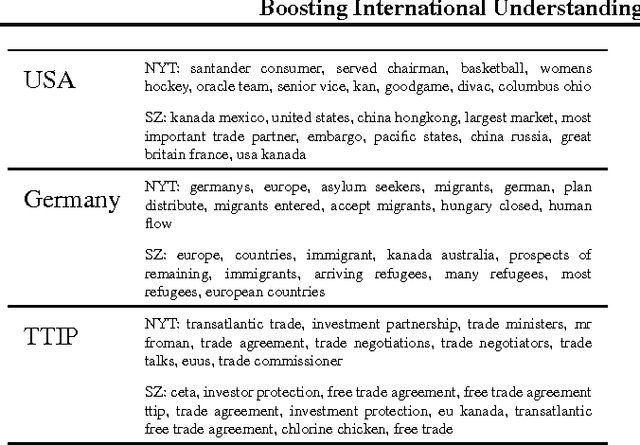

Migration crisis, climate change or tax havens: Global challenges need global solutions. But agreeing on a joint approach is difficult without a common ground for discussion. Public spheres are highly segmented because news are mainly produced and received on a national level. Gain- ing a global view on international debates about important issues is hindered by the enormous quantity of news and by language barriers. Media analysis usually focuses only on qualitative re- search. In this position statement, we argue that it is imperative to pool methods from machine learning, journalism studies and statistics to help bridging the segmented data of the international public sphere, using the Transatlantic Trade and Investment Partnership (TTIP) as a case study.