 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmploying an Adjusted Stability Measure for Multi-Criteria Model Fitting on Data Sets with Similar Features
Jun 15, 2021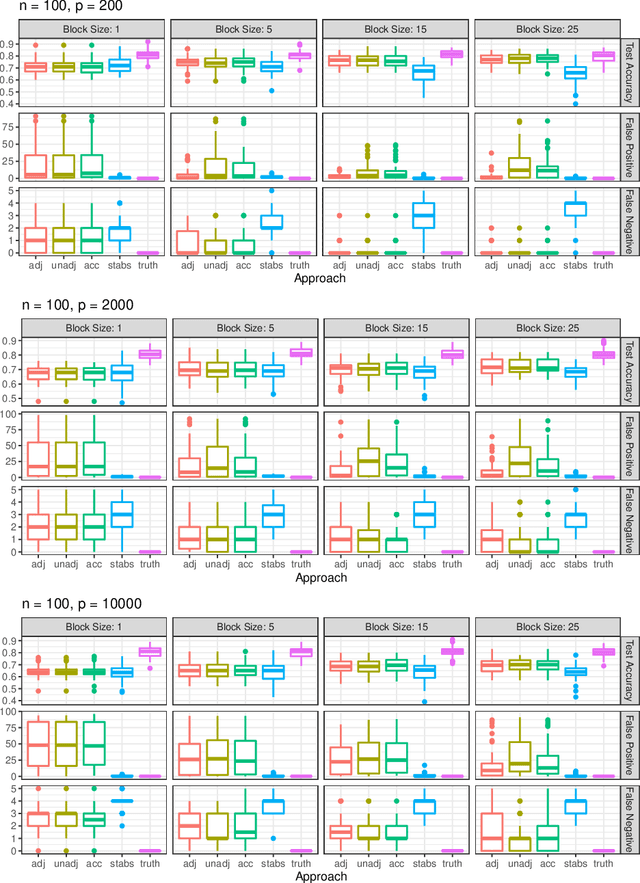
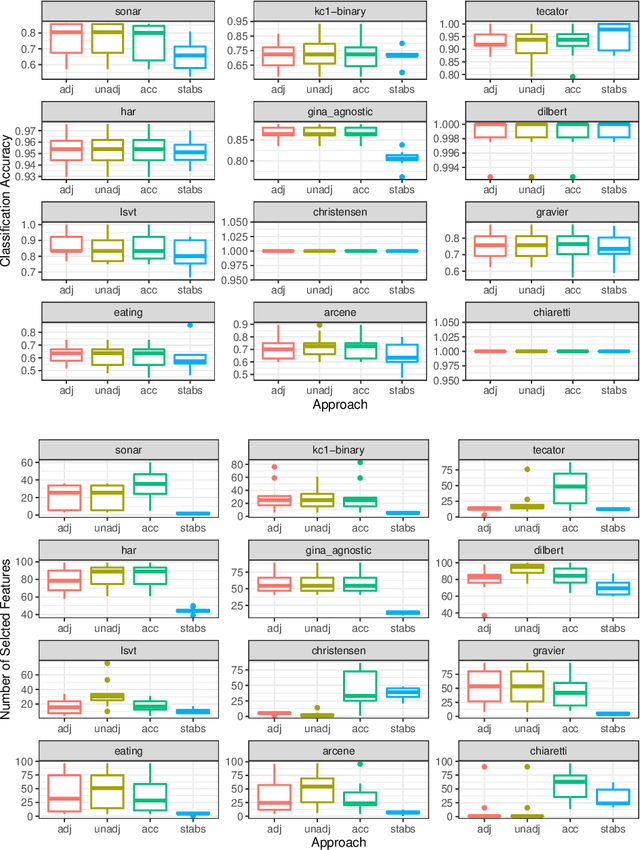
Fitting models with high predictive accuracy that include all relevant but no irrelevant or redundant features is a challenging task on data sets with similar (e.g. highly correlated) features. We propose the approach of tuning the hyperparameters of a predictive model in a multi-criteria fashion with respect to predictive accuracy and feature selection stability. We evaluate this approach based on both simulated and real data sets and we compare it to the standard approach of single-criteria tuning of the hyperparameters as well as to the state-of-the-art technique "stability selection". We conclude that our approach achieves the same or better predictive performance compared to the two established approaches. Considering the stability during tuning does not decrease the predictive accuracy of the resulting models. Our approach succeeds at selecting the relevant features while avoiding irrelevant or redundant features. The single-criteria approach fails at avoiding irrelevant or redundant features and the stability selection approach fails at selecting enough relevant features for achieving acceptable predictive accuracy. For our approach, for data sets with many similar features, the feature selection stability must be evaluated with an adjusted stability measure, that is, a measure that considers similarities between features. For data sets with only few similar features, an unadjusted stability measure suffices and is faster to compute.
Adjusted Measures for Feature Selection Stability for Data Sets with Similar Features
Sep 25, 2020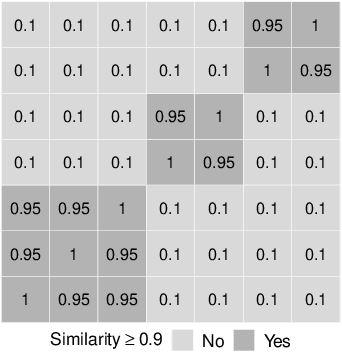
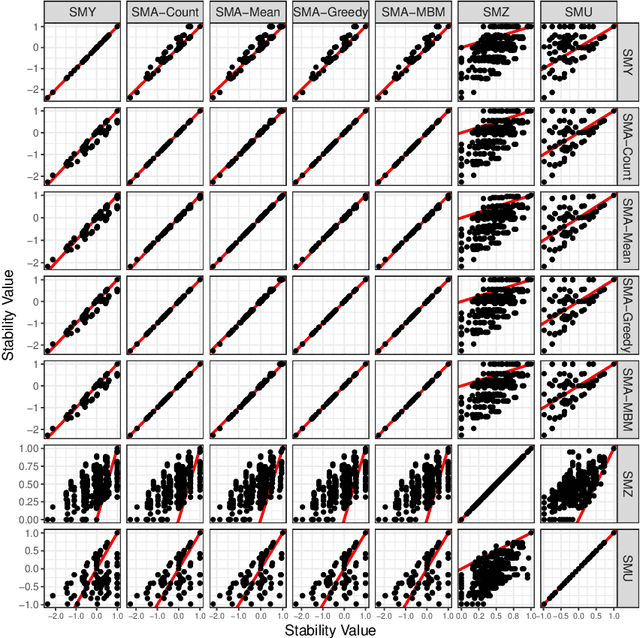
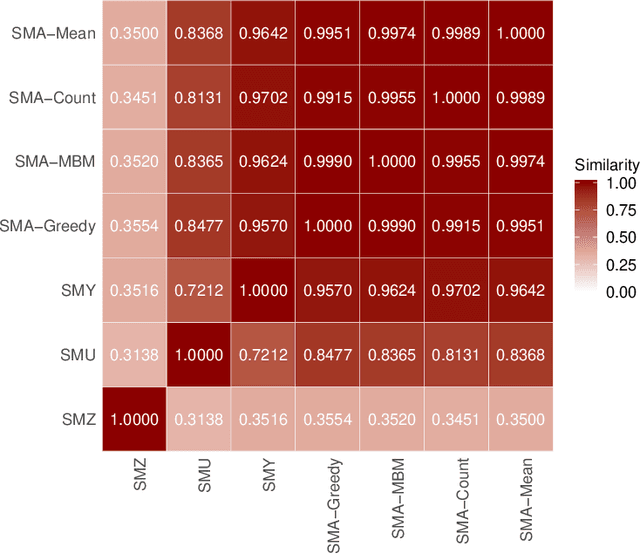
For data sets with similar features, for example highly correlated features, most existing stability measures behave in an undesired way: They consider features that are almost identical but have different identifiers as different features. Existing adjusted stability measures, that is, stability measures that take into account the similarities between features, have major theoretical drawbacks. We introduce new adjusted stability measures that overcome these drawbacks. We compare them to each other and to existing stability measures based on both artificial and real sets of selected features. Based on the results, we suggest using one new stability measure that considers highly similar features as exchangeable.
Feature Selection Methods for Cost-Constrained Classification in Random Forests
Aug 17, 2020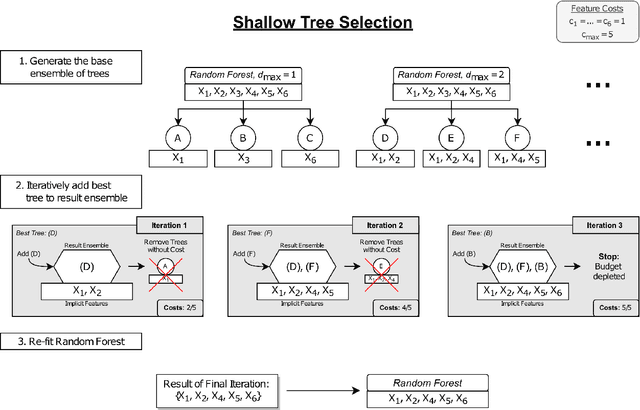

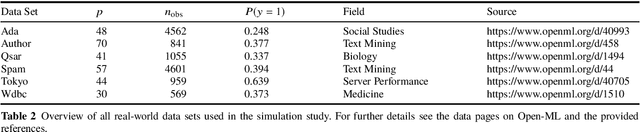
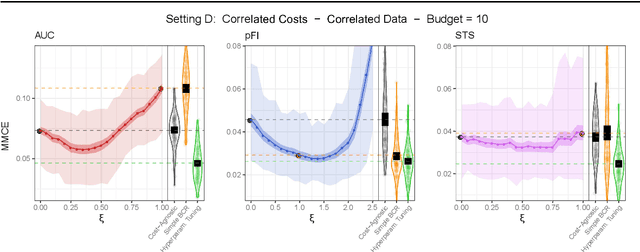
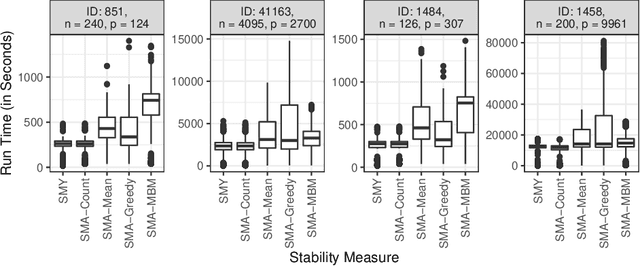
Cost-sensitive feature selection describes a feature selection problem, where features raise individual costs for inclusion in a model. These costs allow to incorporate disfavored aspects of features, e.g. failure rates of as measuring device, or patient harm, in the model selection process. Random Forests define a particularly challenging problem for feature selection, as features are generally entangled in an ensemble of multiple trees, which makes a post hoc removal of features infeasible. Feature selection methods therefore often either focus on simple pre-filtering methods, or require many Random Forest evaluations along their optimization path, which drastically increases the computational complexity. To solve both issues, we propose Shallow Tree Selection, a novel fast and multivariate feature selection method that selects features from small tree structures. Additionally, we also adapt three standard feature selection algorithms for cost-sensitive learning by introducing a hyperparameter-controlled benefit-cost ratio criterion (BCR) for each method. In an extensive simulation study, we assess this criterion, and compare the proposed methods to multiple performance-based baseline alternatives on four artificial data settings and seven real-world data settings. We show that all methods using a hyperparameterized BCR criterion outperform the baseline alternatives. In a direct comparison between the proposed methods, each method indicates strengths in certain settings, but no one-fits-all solution exists. On a global average, we could identify preferable choices among our BCR based methods. Nevertheless, we conclude that a practical analysis should never rely on a single method only, but always compare different approaches to obtain the best results.
Implications on Feature Detection when using the Benefit-Cost Ratio
Aug 15, 2020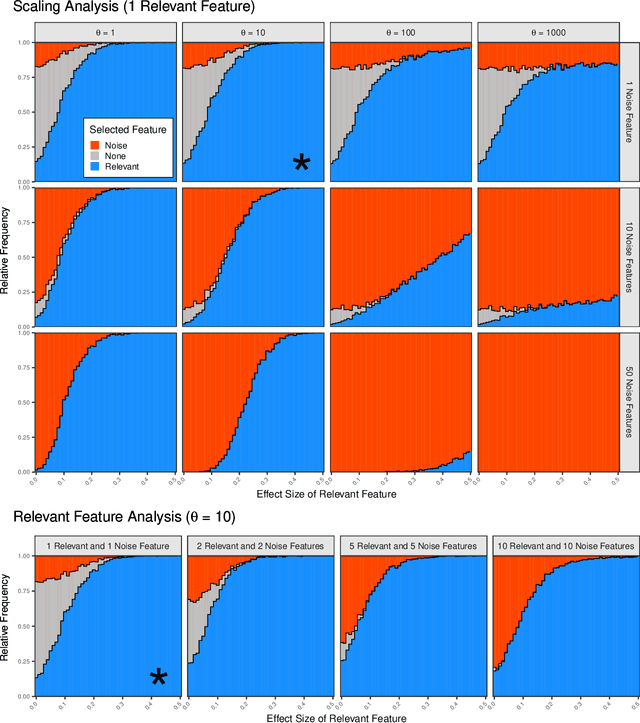
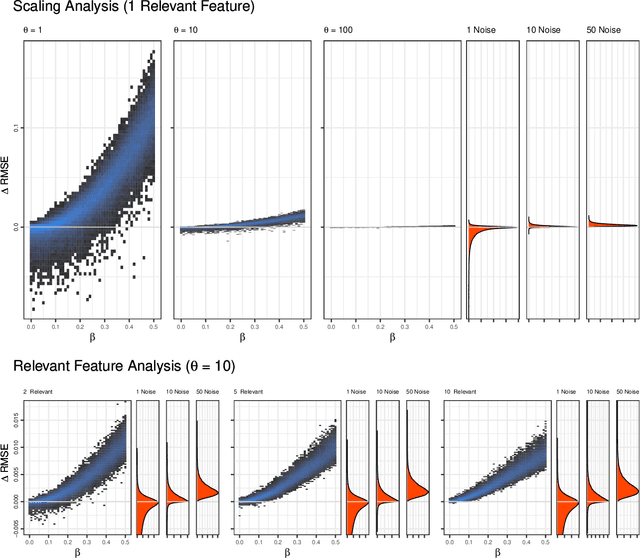
In many practical machine learning applications, there are two objectives: one is to maximize predictive accuracy and the other is to minimize costs of the resulting model. These costs of individual features may be financial costs, but can also refer to other aspects, like for example evaluation time. Feature selection addresses both objectives, as it reduces the number of features and can improve the generalization ability of the model. If costs differ between features, the feature selection needs to trade-off the individual benefit and cost of each feature. A popular trade-off choice is the ratio of both, the BCR (benefit-cost ratio). In this paper we analyze implications of using this measure with special focus to the ability to distinguish relevant features from noise. We perform a simulation study for different cost and data settings and obtain detection rates of relevant features and empirical distributions of the trade-off ratio. Our simulation study exposed a clear impact of the cost setting on the detection rate. In situations with large cost differences and small effect sizes, the BCR missed relevant features and preferred cheap noise features. We conclude that a trade-off between predictive performance and costs without a controlling hyperparameter can easily overemphasize very cheap noise features. While the simple benefit-cost ratio offers an easy solution to incorporate costs, it is important to be aware of its risks. Avoiding costs close to 0, rescaling large cost differences, or using a hyperparameter trade-off are ways to counteract the adverse effects exposed in this paper.
Improving Reliability of Latent Dirichlet Allocation by Assessing Its Stability Using Clustering Techniques on Replicated Runs
Feb 14, 2020
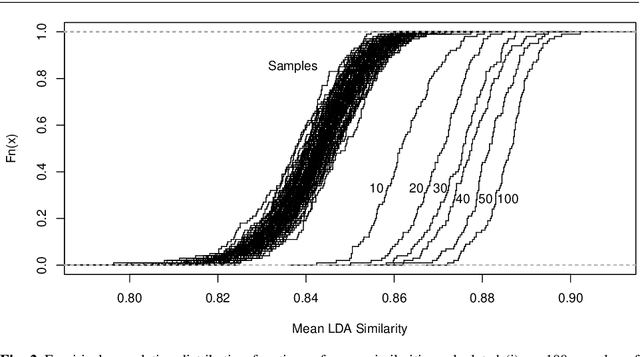
For organizing large text corpora topic modeling provides useful tools. A widely used method is Latent Dirichlet Allocation (LDA), a generative probabilistic model which models single texts in a collection of texts as mixtures of latent topics. The assignments of words to topics rely on initial values such that generally the outcome of LDA is not fully reproducible. In addition, the reassignment via Gibbs Sampling is based on conditional distributions, leading to different results in replicated runs on the same text data. This fact is often neglected in everyday practice. We aim to improve the reliability of LDA results. Therefore, we study the stability of LDA by comparing assignments from replicated runs. We propose to quantify the similarity of two generated topics by a modified Jaccard coefficient. Using such similarities, topics can be clustered. A new pruning algorithm for hierarchical clustering results based on the idea that two LDA runs create pairs of similar topics is proposed. This approach leads to the new measure S-CLOP ({\bf S}imilarity of multiple sets by {\bf C}lustering with {\bf LO}cal {\bf P}runing) for quantifying the stability of LDA models. We discuss some characteristics of this measure and illustrate it with an application to real data consisting of newspaper articles from \textit{USA Today}. Our results show that the measure S-CLOP is useful for assessing the stability of LDA models or any other topic modeling procedure that characterize its topics by word distributions. Based on the newly proposed measure for LDA stability, we propose a method to increase the reliability and hence to improve the reproducibility of empirical findings based on topic modeling. This increase in reliability is obtained by running the LDA several times and taking as prototype the most representative run, that is the LDA run with highest average similarity to all other runs.
High Dimensional Restrictive Federated Model Selection with multi-objective Bayesian Optimization over shifted distributions
Feb 24, 2019
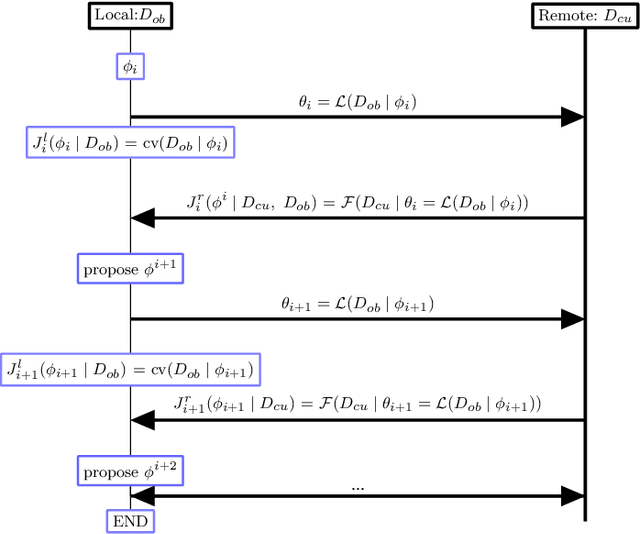

A novel machine learning optimization process coined Restrictive Federated Model Selection (RFMS) is proposed under the scenario, for example, when data from healthcare units can not leave the site it is situated on and it is forbidden to carry out training algorithms on remote data sites due to either technical or privacy and trust concerns. To carry out a clinical research under this scenario, an analyst could train a machine learning model only on local data site, but it is still possible to execute a statistical query at a certain cost in the form of sending a machine learning model to some of the remote data sites and get the performance measures as feedback, maybe due to prediction being usually much cheaper. Compared to federated learning, which is optimizing the model parameters directly by carrying out training across all data sites, RFMS trains model parameters only on one local data site but optimizes hyper-parameters across other data sites jointly since hyper-parameters play an important role in machine learning performance. The aim is to get a Pareto optimal model with respective to both local and remote unseen prediction losses, which could generalize well across data sites. In this work, we specifically consider high dimensional data with shifted distributions over data sites. As an initial investigation, Bayesian Optimization especially multi-objective Bayesian Optimization is used to guide an adaptive hyper-parameter optimization process to select models under the RFMS scenario. Empirical results show that solely using the local data site to tune hyper-parameters generalizes poorly across data sites, compared to methods that utilize the local and remote performances. Furthermore, in terms of dominated hypervolumes, multi-objective Bayesian Optimization algorithms show increased performance across multiple data sites among other candidates.
Machine Learning meets Data-Driven Journalism: Boosting International Understanding and Transparency in News Coverage
Jun 16, 2016
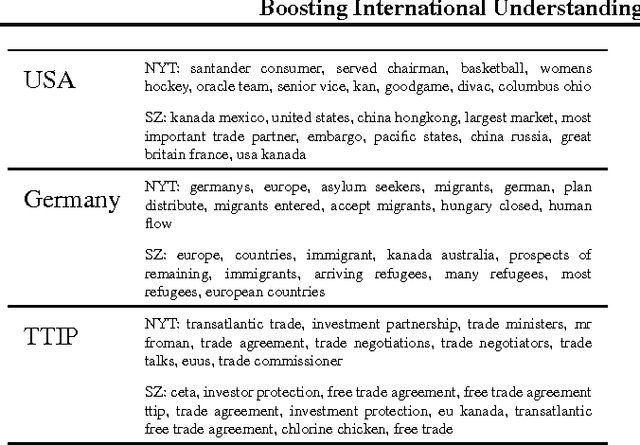

Migration crisis, climate change or tax havens: Global challenges need global solutions. But agreeing on a joint approach is difficult without a common ground for discussion. Public spheres are highly segmented because news are mainly produced and received on a national level. Gain- ing a global view on international debates about important issues is hindered by the enormous quantity of news and by language barriers. Media analysis usually focuses only on qualitative re- search. In this position statement, we argue that it is imperative to pool methods from machine learning, journalism studies and statistics to help bridging the segmented data of the international public sphere, using the Transatlantic Trade and Investment Partnership (TTIP) as a case study.