 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Reliability of Latent Dirichlet Allocation by Assessing Its Stability Using Clustering Techniques on Replicated Runs
Paper and Code

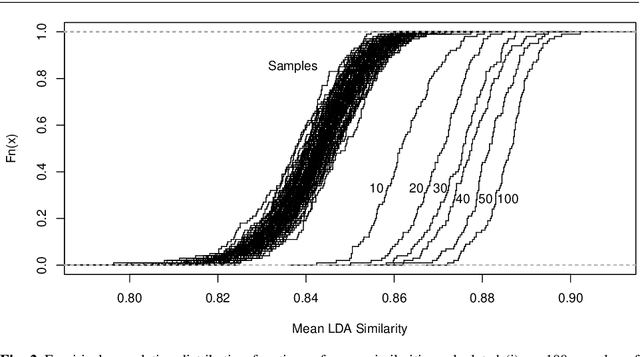
For organizing large text corpora topic modeling provides useful tools. A widely used method is Latent Dirichlet Allocation (LDA), a generative probabilistic model which models single texts in a collection of texts as mixtures of latent topics. The assignments of words to topics rely on initial values such that generally the outcome of LDA is not fully reproducible. In addition, the reassignment via Gibbs Sampling is based on conditional distributions, leading to different results in replicated runs on the same text data. This fact is often neglected in everyday practice. We aim to improve the reliability of LDA results. Therefore, we study the stability of LDA by comparing assignments from replicated runs. We propose to quantify the similarity of two generated topics by a modified Jaccard coefficient. Using such similarities, topics can be clustered. A new pruning algorithm for hierarchical clustering results based on the idea that two LDA runs create pairs of similar topics is proposed. This approach leads to the new measure S-CLOP ({\bf S}imilarity of multiple sets by {\bf C}lustering with {\bf LO}cal {\bf P}runing) for quantifying the stability of LDA models. We discuss some characteristics of this measure and illustrate it with an application to real data consisting of newspaper articles from \textit{USA Today}. Our results show that the measure S-CLOP is useful for assessing the stability of LDA models or any other topic modeling procedure that characterize its topics by word distributions. Based on the newly proposed measure for LDA stability, we propose a method to increase the reliability and hence to improve the reproducibility of empirical findings based on topic modeling. This increase in reliability is obtained by running the LDA several times and taking as prototype the most representative run, that is the LDA run with highest average similarity to all other runs.