 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord-Centered Semantic Graphs for Interpretable Diachronic Sense Tracking
Jan 29, 2026We propose an interpretable, graph-based framework for analyzing semantic shift in diachronic corpora. For each target word and time slice, we induce a word-centered semantic network that integrates distributional similarity from diachronic Skip-gram embeddings with lexical substitutability from time-specific masked language models. We identify sense-related structure by clustering the peripheral graph, align clusters across time via node overlap, and track change through cluster composition and normalized cluster mass. In an application study on a corpus of New York Times Magazine articles (1980 - 2017), we show that graph connectivity reflects polysemy dynamics and that the induced communities capture contrasting trajectories: event-driven sense replacement (trump), semantic stability with cluster over-segmentation effects (god), and gradual association shifts tied to digital communication (post). Overall, word-centered semantic graphs offer a compact and transparent representation for exploring sense evolution without relying on predefined sense inventories.
ttta: Tools for Temporal Text Analysis
Mar 04, 2025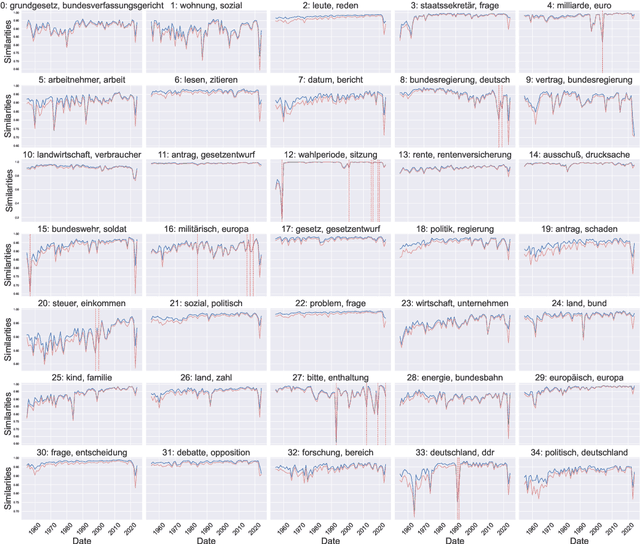
Text data is inherently temporal. The meaning of words and phrases changes over time, and the context in which they are used is constantly evolving. This is not just true for social media data, where the language used is rapidly influenced by current events, memes and trends, but also for journalistic, economic or political text data. Most NLP techniques however consider the corpus at hand to be homogenous in regard to time. This is a simplification that can lead to biased results, as the meaning of words and phrases can change over time. For instance, running a classic Latent Dirichlet Allocation on a corpus that spans several years is not enough to capture changes in the topics over time, but only portraits an "average" topic distribution over the whole time span. Researchers have developed a number of tools for analyzing text data over time. However, these tools are often scattered across different packages and libraries, making it difficult for researchers to use them in a consistent and reproducible way. The ttta package is supposed to serve as a collection of tools for analyzing text data over time.
PETapter: Leveraging PET-style classification heads for modular few-shot parameter-efficient fine-tuning
Dec 06, 2024Few-shot learning and parameter-efficient fine-tuning (PEFT) are crucial to overcome the challenges of data scarcity and ever growing language model sizes. This applies in particular to specialized scientific domains, where researchers might lack expertise and resources to fine-tune high-performing language models to nuanced tasks. We propose PETapter, a novel method that effectively combines PEFT methods with PET-style classification heads to boost few-shot learning capabilities without the significant computational overhead typically associated with full model training. We validate our approach on three established NLP benchmark datasets and one real-world dataset from communication research. We show that PETapter not only achieves comparable performance to full few-shot fine-tuning using pattern-exploiting training (PET), but also provides greater reliability and higher parameter efficiency while enabling higher modularity and easy sharing of the trained modules, which enables more researchers to utilize high-performing NLP-methods in their research.
Zeitenwenden: Detecting changes in the German political discourse
Oct 23, 2024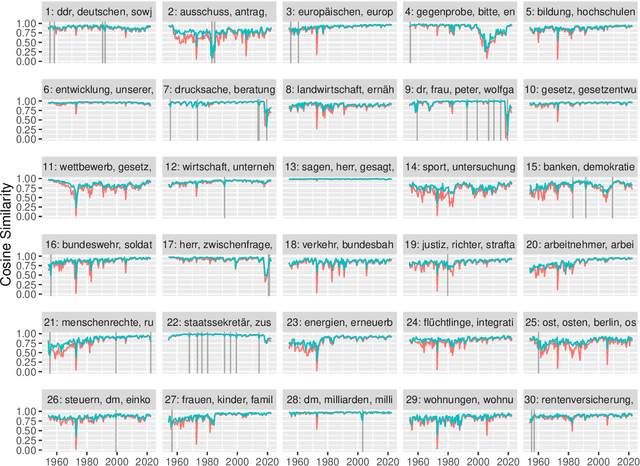
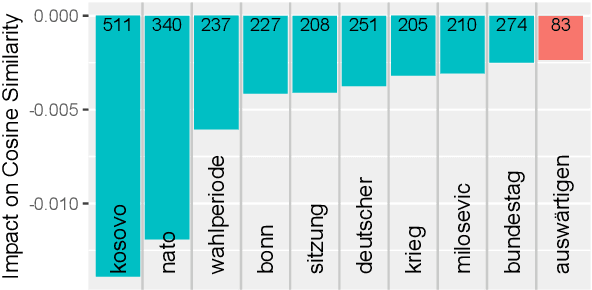
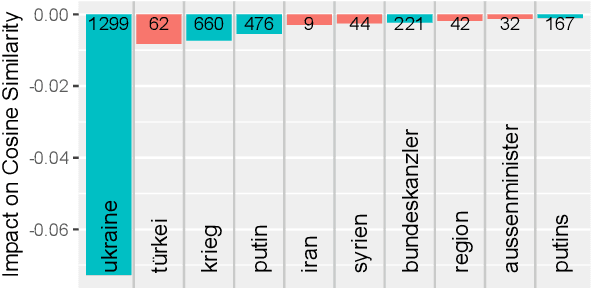
From a monarchy to a democracy, to a dictatorship and back to a democracy -- the German political landscape has been constantly changing ever since the first German national state was formed in 1871. After World War II, the Federal Republic of Germany was formed in 1949. Since then every plenary session of the German Bundestag was logged and even has been digitized over the course of the last few years. We analyze these texts using a time series variant of the topic model LDA to investigate which events had a lasting effect on the political discourse and how the political topics changed over time. This allows us to detect changes in word frequency (and thus key discussion points) in political discourse.
* 7 pages, 6 figures
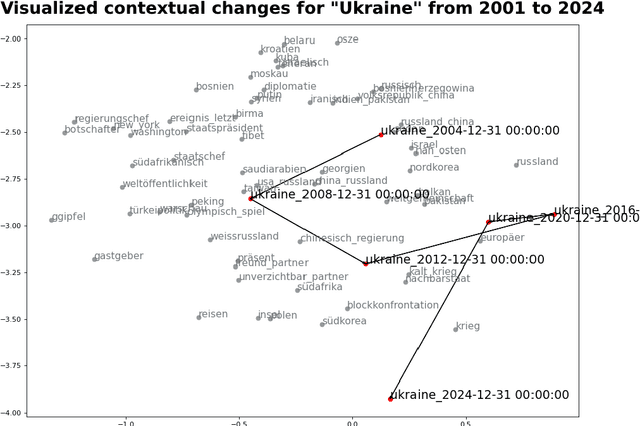
Few-shot learning for automated content analysis: Efficient coding of arguments and claims in the debate on arms deliveries to Ukraine
Dec 28, 2023Pre-trained language models (PLM) based on transformer neural networks developed in the field of natural language processing (NLP) offer great opportunities to improve automatic content analysis in communication science, especially for the coding of complex semantic categories in large datasets via supervised machine learning. However, three characteristics so far impeded the widespread adoption of the methods in the applying disciplines: the dominance of English language models in NLP research, the necessary computing resources, and the effort required to produce training data to fine-tune PLMs. In this study, we address these challenges by using a multilingual transformer model in combination with the adapter extension to transformers, and few-shot learning methods. We test our approach on a realistic use case from communication science to automatically detect claims and arguments together with their stance in the German news debate on arms deliveries to Ukraine. In three experiments, we evaluate (1) data preprocessing strategies and model variants for this task, (2) the performance of different few-shot learning methods, and (3) how well the best setup performs on varying training set sizes in terms of validity, reliability, replicability and reproducibility of the results. We find that our proposed combination of transformer adapters with pattern exploiting training provides a parameter-efficient and easily shareable alternative to fully fine-tuning PLMs. It performs on par in terms of validity, while overall, provides better properties for application in communication studies. The results also show that pre-fine-tuning for a task on a near-domain dataset leads to substantial improvement, in particular in the few-shot setting. Further, the results indicate that it is useful to bias the dataset away from the viewpoints of specific prominent individuals.
Lex2Sent: A bagging approach to unsupervised sentiment analysis
Sep 26, 2022
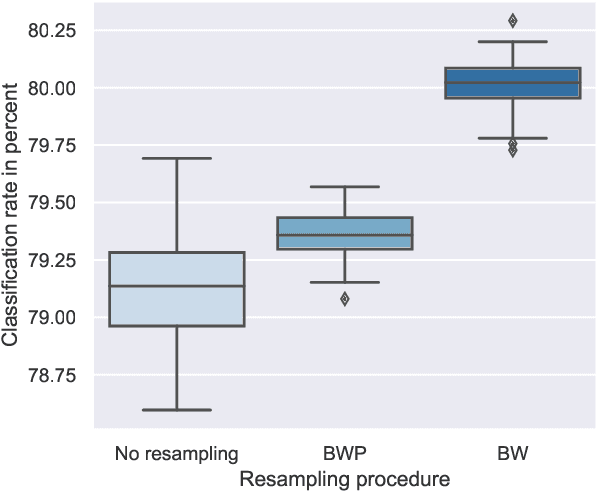
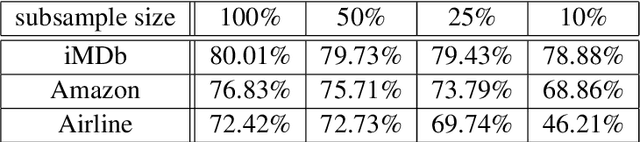
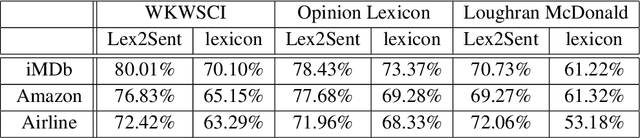
Unsupervised sentiment analysis is traditionally performed by counting those words in a text that are stored in a sentiment lexicon and then assigning a label depending on the proportion of positive and negative words registered. While these "counting" methods are considered to be beneficial as they rate a text deterministically, their classification rates decrease when the analyzed texts are short or the vocabulary differs from what the lexicon considers default. The model proposed in this paper, called Lex2Sent, is an unsupervised sentiment analysis method to improve the classification of sentiment lexicon methods. For this purpose, a Doc2Vec-model is trained to determine the distances between document embeddings and the embeddings of the positive and negative part of a sentiment lexicon. These distances are then evaluated for multiple executions of Doc2Vec on resampled documents and are averaged to perform the classification task. For three benchmark datasets considered in this paper, the proposed Lex2Sent outperforms every evaluated lexicon, including state-of-the-art lexica like VADER or the Opinion Lexicon in terms of classification rate.
Improving Reliability of Latent Dirichlet Allocation by Assessing Its Stability Using Clustering Techniques on Replicated Runs
Feb 14, 2020
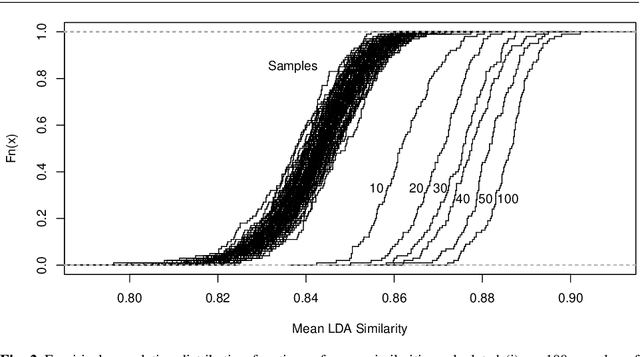
For organizing large text corpora topic modeling provides useful tools. A widely used method is Latent Dirichlet Allocation (LDA), a generative probabilistic model which models single texts in a collection of texts as mixtures of latent topics. The assignments of words to topics rely on initial values such that generally the outcome of LDA is not fully reproducible. In addition, the reassignment via Gibbs Sampling is based on conditional distributions, leading to different results in replicated runs on the same text data. This fact is often neglected in everyday practice. We aim to improve the reliability of LDA results. Therefore, we study the stability of LDA by comparing assignments from replicated runs. We propose to quantify the similarity of two generated topics by a modified Jaccard coefficient. Using such similarities, topics can be clustered. A new pruning algorithm for hierarchical clustering results based on the idea that two LDA runs create pairs of similar topics is proposed. This approach leads to the new measure S-CLOP ({\bf S}imilarity of multiple sets by {\bf C}lustering with {\bf LO}cal {\bf P}runing) for quantifying the stability of LDA models. We discuss some characteristics of this measure and illustrate it with an application to real data consisting of newspaper articles from \textit{USA Today}. Our results show that the measure S-CLOP is useful for assessing the stability of LDA models or any other topic modeling procedure that characterize its topics by word distributions. Based on the newly proposed measure for LDA stability, we propose a method to increase the reliability and hence to improve the reproducibility of empirical findings based on topic modeling. This increase in reliability is obtained by running the LDA several times and taking as prototype the most representative run, that is the LDA run with highest average similarity to all other runs.