 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord-Centered Semantic Graphs for Interpretable Diachronic Sense Tracking
Jan 29, 2026We propose an interpretable, graph-based framework for analyzing semantic shift in diachronic corpora. For each target word and time slice, we induce a word-centered semantic network that integrates distributional similarity from diachronic Skip-gram embeddings with lexical substitutability from time-specific masked language models. We identify sense-related structure by clustering the peripheral graph, align clusters across time via node overlap, and track change through cluster composition and normalized cluster mass. In an application study on a corpus of New York Times Magazine articles (1980 - 2017), we show that graph connectivity reflects polysemy dynamics and that the induced communities capture contrasting trajectories: event-driven sense replacement (trump), semantic stability with cluster over-segmentation effects (god), and gradual association shifts tied to digital communication (post). Overall, word-centered semantic graphs offer a compact and transparent representation for exploring sense evolution without relying on predefined sense inventories.
pdfQA: Diverse, Challenging, and Realistic Question Answering over PDFs
Jan 06, 2026PDFs are the second-most used document type on the internet (after HTML). Yet, existing QA datasets commonly start from text sources or only address specific domains. In this paper, we present pdfQA, a multi-domain 2K human-annotated (real-pdfQA) and 2K synthetic dataset (syn-pdfQA) differentiating QA pairs in ten complexity dimensions (e.g., file type, source modality, source position, answer type). We apply and evaluate quality and difficulty filters on both datasets, obtaining valid and challenging QA pairs. We answer the questions with open-source LLMs, revealing existing challenges that correlate with our complexity dimensions. pdfQA presents a basis for end-to-end QA pipeline evaluation, testing diverse skill sets and local optimizations (e.g., in information retrieval or parsing).
Automated Evidence Extraction and Scoring for Corporate Climate Policy Engagement: A Multilingual RAG Approach
Sep 10, 2025InfluenceMap's LobbyMap Platform monitors the climate policy engagement of over 500 companies and 250 industry associations, assessing each entity's support or opposition to science-based policy pathways for achieving the Paris Agreement's goal of limiting global warming to 1.5{\deg}C. Although InfluenceMap has made progress with automating key elements of the analytical workflow, a significant portion of the assessment remains manual, making it time- and labor-intensive and susceptible to human error. We propose an AI-assisted framework to accelerate the monitoring of corporate climate policy engagement by leveraging Retrieval-Augmented Generation to automate the most time-intensive extraction of relevant evidence from large-scale textual data. Our evaluation shows that a combination of layout-aware parsing, the Nomic embedding model, and few-shot prompting strategies yields the best performance in extracting and classifying evidence from multilingual corporate documents. We conclude that while the automated RAG system effectively accelerates evidence extraction, the nuanced nature of the analysis necessitates a human-in-the-loop approach where the technology augments, rather than replaces, expert judgment to ensure accuracy.
ttta: Tools for Temporal Text Analysis
Mar 04, 2025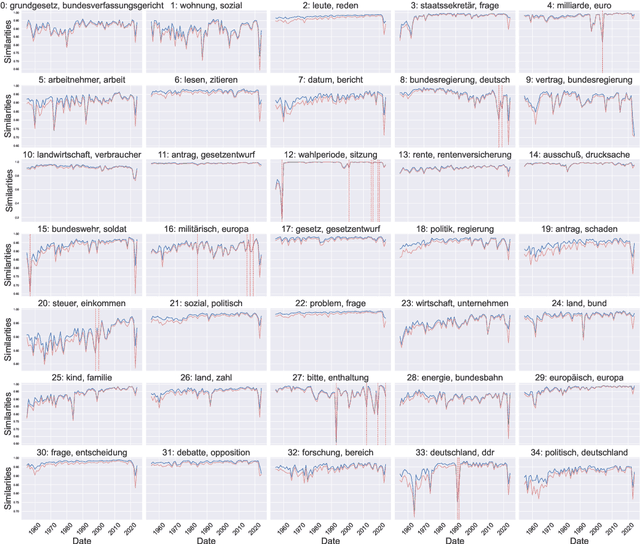
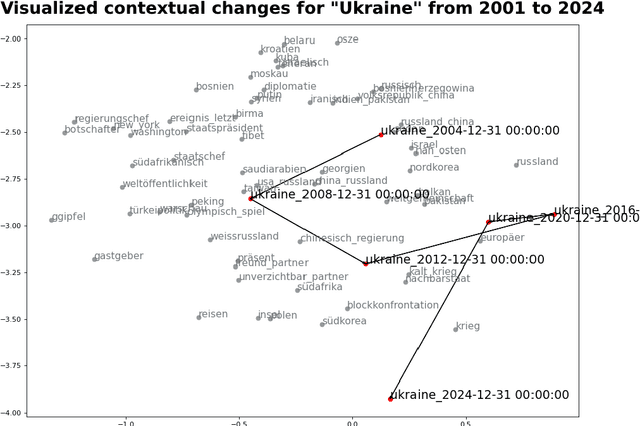
Text data is inherently temporal. The meaning of words and phrases changes over time, and the context in which they are used is constantly evolving. This is not just true for social media data, where the language used is rapidly influenced by current events, memes and trends, but also for journalistic, economic or political text data. Most NLP techniques however consider the corpus at hand to be homogenous in regard to time. This is a simplification that can lead to biased results, as the meaning of words and phrases can change over time. For instance, running a classic Latent Dirichlet Allocation on a corpus that spans several years is not enough to capture changes in the topics over time, but only portraits an "average" topic distribution over the whole time span. Researchers have developed a number of tools for analyzing text data over time. However, these tools are often scattered across different packages and libraries, making it difficult for researchers to use them in a consistent and reproducible way. The ttta package is supposed to serve as a collection of tools for analyzing text data over time.