 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation
Feb 18, 2026Artificial Intelligence (AI) benchmarks play a central role in measuring progress in model development and guiding deployment decisions. However, many benchmarks quickly become saturated, meaning that they can no longer differentiate between the best-performing models, diminishing their long-term value. In this study, we analyze benchmark saturation across 60 Large Language Model (LLM) benchmarks selected from technical reports by major model developers. To identify factors driving saturation, we characterize benchmarks along 14 properties spanning task design, data construction, and evaluation format. We test five hypotheses examining how each property contributes to saturation rates. Our analysis reveals that nearly half of the benchmarks exhibit saturation, with rates increasing as benchmarks age. Notably, hiding test data (i.e., public vs. private) shows no protective effect, while expert-curated benchmarks resist saturation better than crowdsourced ones. Our findings highlight which design choices extend benchmark longevity and inform strategies for more durable evaluation.
Investigating Disability Representations in Text-to-Image Models
Feb 04, 2026Text-to-image generative models have made remarkable progress in producing high-quality visual content from textual descriptions, yet concerns remain about how they represent social groups. While characteristics like gender and race have received increasing attention, disability representations remain underexplored. This study investigates how people with disabilities are represented in AI-generated images by analyzing outputs from Stable Diffusion XL and DALL-E 3 using a structured prompt design. We analyze disability representations by comparing image similarities between generic disability prompts and prompts referring to specific disability categories. Moreover, we evaluate how mitigation strategies influence disability portrayals, with a focus on assessing affective framing through sentiment polarity analysis, combining both automatic and human evaluation. Our findings reveal persistent representational imbalances and highlight the need for continuous evaluation and refinement of generative models to foster more diverse and inclusive portrayals of disability.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
pdfQA: Diverse, Challenging, and Realistic Question Answering over PDFs
Jan 06, 2026PDFs are the second-most used document type on the internet (after HTML). Yet, existing QA datasets commonly start from text sources or only address specific domains. In this paper, we present pdfQA, a multi-domain 2K human-annotated (real-pdfQA) and 2K synthetic dataset (syn-pdfQA) differentiating QA pairs in ten complexity dimensions (e.g., file type, source modality, source position, answer type). We apply and evaluate quality and difficulty filters on both datasets, obtaining valid and challenging QA pairs. We answer the questions with open-source LLMs, revealing existing challenges that correlate with our complexity dimensions. pdfQA presents a basis for end-to-end QA pipeline evaluation, testing diverse skill sets and local optimizations (e.g., in information retrieval or parsing).
Kimi Linear: An Expressive, Efficient Attention Architecture
Oct 30, 2025We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that extends Gated DeltaNet with a finer-grained gating mechanism, enabling more effective use of limited finite-state RNN memory. Our bespoke chunkwise algorithm achieves high hardware efficiency through a specialized variant of the Diagonal-Plus-Low-Rank (DPLR) transition matrices, which substantially reduces computation compared to the general DPLR formulation while remaining more consistent with the classical delta rule. We pretrain a Kimi Linear model with 3B activated parameters and 48B total parameters, based on a layerwise hybrid of KDA and Multi-Head Latent Attention (MLA). Our experiments show that with an identical training recipe, Kimi Linear outperforms full MLA with a sizeable margin across all evaluated tasks, while reducing KV cache usage by up to 75% and achieving up to 6 times decoding throughput for a 1M context. These results demonstrate that Kimi Linear can be a drop-in replacement for full attention architectures with superior performance and efficiency, including tasks with longer input and output lengths. To support further research, we open-source the KDA kernel and vLLM implementations, and release the pre-trained and instruction-tuned model checkpoints.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
The Medium Is Not the Message: Deconfounding Text Embeddings via Linear Concept Erasure
Jul 01, 2025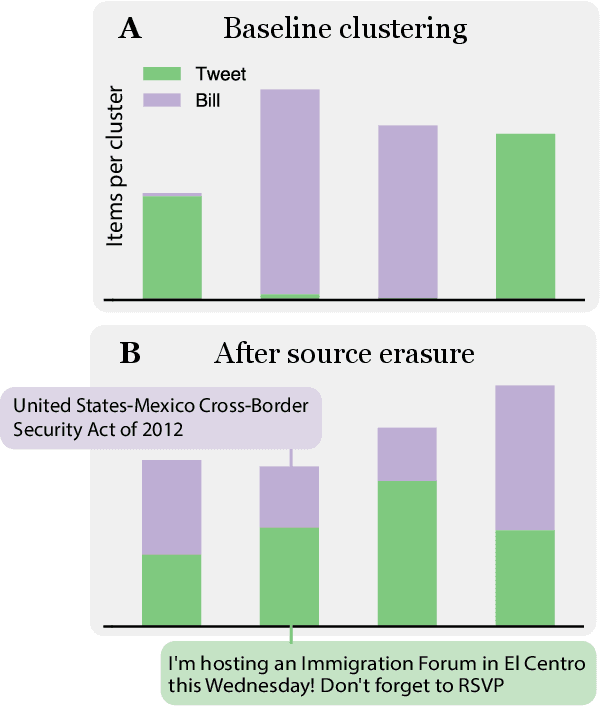
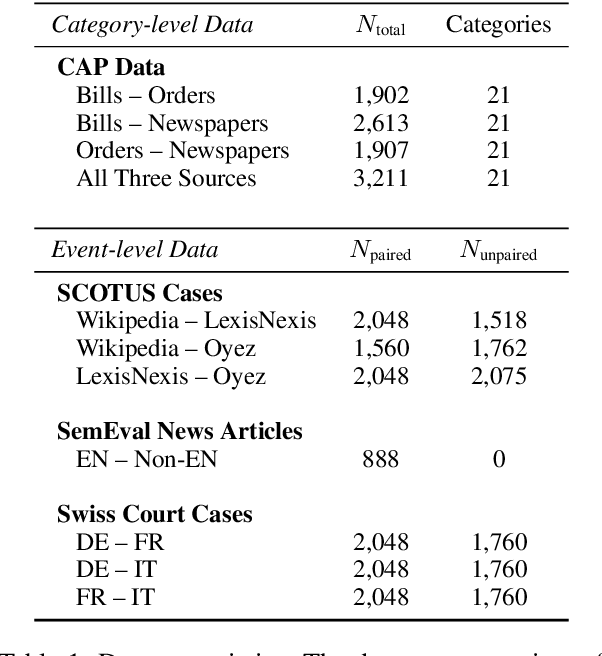
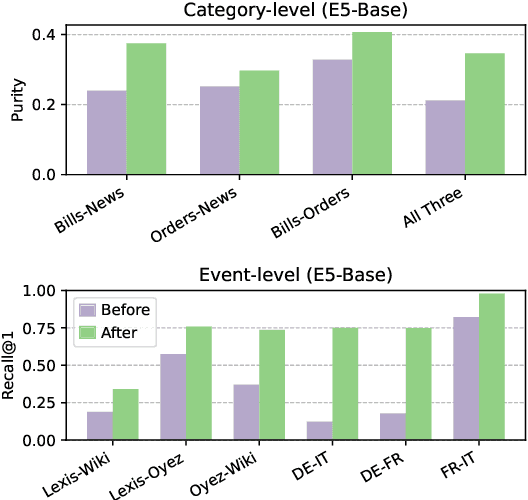
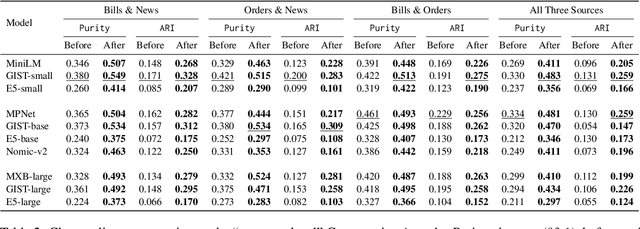
Embedding-based similarity metrics between text sequences can be influenced not just by the content dimensions we most care about, but can also be biased by spurious attributes like the text's source or language. These document confounders cause problems for many applications, but especially those that need to pool texts from different corpora. This paper shows that a debiasing algorithm that removes information about observed confounders from the encoder representations substantially reduces these biases at a minimal computational cost. Document similarity and clustering metrics improve across every embedding variant and task we evaluate -- often dramatically. Interestingly, performance on out-of-distribution benchmarks is not impacted, indicating that the embeddings are not otherwise degraded.
Can Large Language Models Capture Human Annotator Disagreements?
Jun 24, 2025Human annotation variation (i.e., annotation disagreements) is common in NLP and often reflects important information such as task subjectivity and sample ambiguity. While Large Language Models (LLMs) are increasingly used for automatic annotation to reduce human effort, their evaluation often focuses on predicting the majority-voted "ground truth" labels. It is still unclear, however, whether these models also capture informative human annotation variation. Our work addresses this gap by extensively evaluating LLMs' ability to predict annotation disagreements without access to repeated human labels. Our results show that LLMs struggle with modeling disagreements, which can be overlooked by majority label-based evaluations. Notably, while RLVR-style (Reinforcement learning with verifiable rewards) reasoning generally boosts LLM performance, it degrades performance in disagreement prediction. Our findings highlight the critical need for evaluating and improving LLM annotators in disagreement modeling. Code and data at https://github.com/EdisonNi-hku/Disagreement_Prediction.
LEXam: Benchmarking Legal Reasoning on 340 Law Exams
May 19, 2025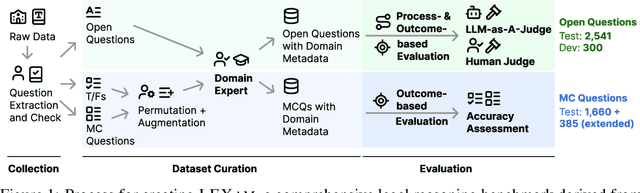
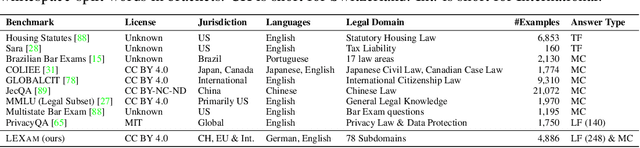
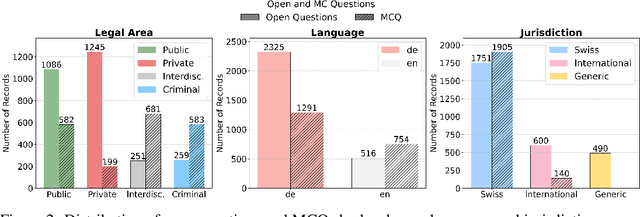
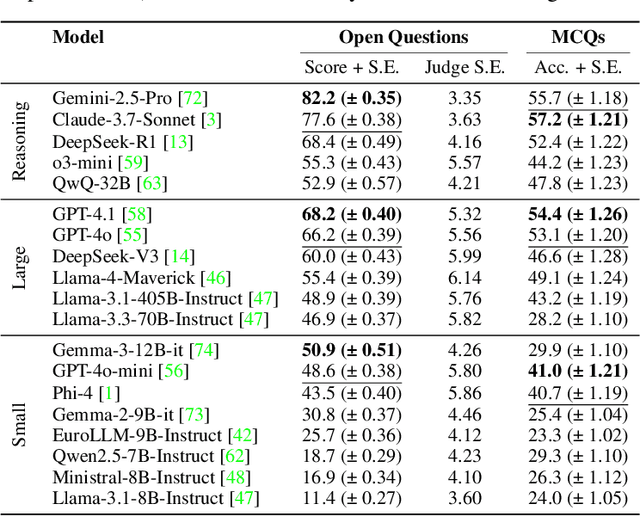
Long-form legal reasoning remains a key challenge for large language models (LLMs) in spite of recent advances in test-time scaling. We introduce LEXam, a novel benchmark derived from 340 law exams spanning 116 law school courses across a range of subjects and degree levels. The dataset comprises 4,886 law exam questions in English and German, including 2,841 long-form, open-ended questions and 2,045 multiple-choice questions. Besides reference answers, the open questions are also accompanied by explicit guidance outlining the expected legal reasoning approach such as issue spotting, rule recall, or rule application. Our evaluation on both open-ended and multiple-choice questions present significant challenges for current LLMs; in particular, they notably struggle with open questions that require structured, multi-step legal reasoning. Moreover, our results underscore the effectiveness of the dataset in differentiating between models with varying capabilities. Adopting an LLM-as-a-Judge paradigm with rigorous human expert validation, we demonstrate how model-generated reasoning steps can be evaluated consistently and accurately. Our evaluation setup provides a scalable method to assess legal reasoning quality beyond simple accuracy metrics. Project page: https://lexam-benchmark.github.io/
TrackRAD2025 challenge dataset: Real-time tumor tracking for MRI-guided radiotherapy
Mar 24, 2025Purpose: Magnetic resonance imaging (MRI) to visualize anatomical motion is becoming increasingly important when treating cancer patients with radiotherapy. Hybrid MRI-linear accelerator (MRI-linac) systems allow real-time motion management during irradiation. This paper presents a multi-institutional real-time MRI time series dataset from different MRI-linac vendors. The dataset is designed to support developing and evaluating real-time tumor localization (tracking) algorithms for MRI-guided radiotherapy within the TrackRAD2025 challenge (https://trackrad2025.grand-challenge.org/). Acquisition and validation methods: The dataset consists of sagittal 2D cine MRIs in 585 patients from six centers (3 Dutch, 1 German, 1 Australian, and 1 Chinese). Tumors in the thorax, abdomen, and pelvis acquired on two commercially available MRI-linacs (0.35 T and 1.5 T) were included. For 108 cases, irradiation targets or tracking surrogates were manually segmented on each temporal frame. The dataset was randomly split into a public training set of 527 cases (477 unlabeled and 50 labeled) and a private testing set of 58 cases (all labeled). Data Format and Usage Notes: The data is publicly available under the TrackRAD2025 collection: https://doi.org/10.57967/hf/4539. Both the images and segmentations for each patient are available in metadata format. Potential Applications: This novel clinical dataset will enable the development and evaluation of real-time tumor localization algorithms for MRI-guided radiotherapy. By enabling more accurate motion management and adaptive treatment strategies, this dataset has the potential to advance the field of radiotherapy significantly.