 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Enhanced GNN: Improving Graph Neural Networks Using Model Outputs
Mar 16, 2020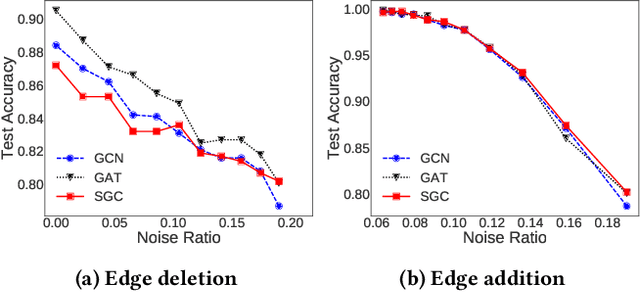
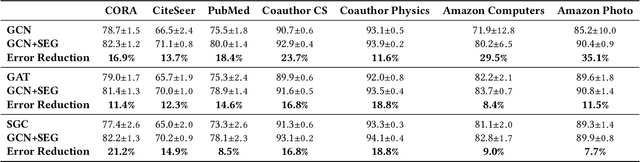
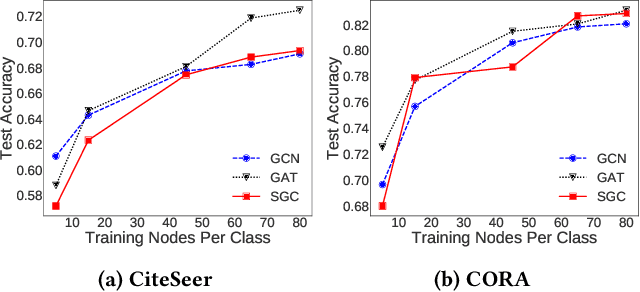
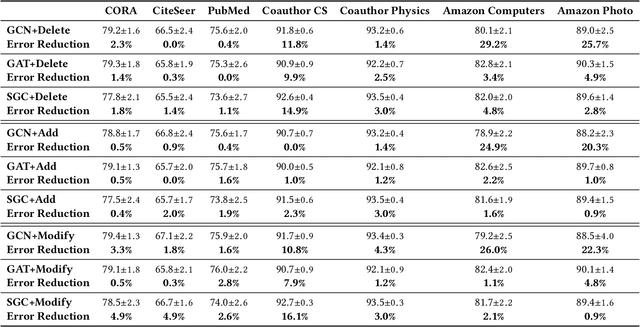
Graph neural networks (GNNs) have received much attention recently because of their excellent performance on graph-based tasks. However, existing research on GNNs focuses on designing more effective models without considering much the quality of the input data itself. In this paper, we propose self-enhanced GNN, which improves the quality of the input data using the outputs of existing GNN models for better performance on semi-supervised node classification. As graph data consist of both topology and node labels, we improve input data quality from both perspectives. For topology, we observe that higher classification accuracy can be achieved when the ratio of inter-class edges (connecting nodes from different classes) is low and propose topology update to remove inter-class edges and add intra-class edges. For node labels, we propose training node augmentation, which enlarges the training set using the labels predicted by existing GNN models. As self-enhanced GNN improves the quality of the input graph data, it is general and can be easily combined with existing GNN models. Experimental results on three well-known GNN models and seven popular datasets show that self-enhanced GNN consistently improves the performance of the three models. The reduction in classification error is 16.2% on average and can be as high as 35.1%.
Edit Distance Embedding using Convolutional Neural Networks
Jan 31, 2020

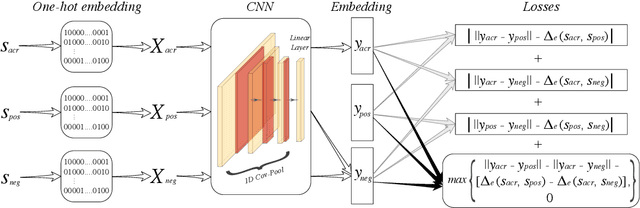

Edit-distance-based string similarity search has many applications such as spell correction, data de-duplication, and sequence alignment. However, computing edit distance is known to have high complexity, which makes string similarity search challenging for large datasets. In this paper, we propose a deep learning pipeline (called CNN-ED) that embeds edit distance into Euclidean distance for fast approximate similarity search. A convolutional neural network (CNN) is used to generate fixed-length vector embeddings for a dataset of strings and the loss function is a combination of the triplet loss and the approximation error. To justify our choice of using CNN instead of other structures (e.g., RNN) as the model, theoretical analysis is conducted to show that some basic operations in our CNN model preserve edit distance. Experimental results show that CNN-ED outperforms data-independent CGK embedding and RNN-based GRU embedding in terms of both accuracy and efficiency by a large margin. We also show that string similarity search can be significantly accelerated using CNN-based embeddings, sometimes by orders of magnitude.
Hyper-Sphere Quantization: Communication-Efficient SGD for Federated Learning
Nov 25, 2019


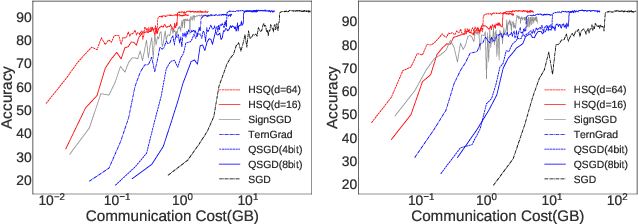
The high cost of communicating gradients is a major bottleneck for federated learning, as the bandwidth of the participating user devices is limited. Existing gradient compression algorithms are mainly designed for data centers with high-speed network and achieve $O(\sqrt{d} \log d)$ per-iteration communication cost at best, where $d$ is the size of the model. We propose hyper-sphere quantization (HSQ), a general framework that can be configured to achieve a continuum of trade-offs between communication efficiency and gradient accuracy. In particular, at the high compression ratio end, HSQ provides a low per-iteration communication cost of $O(\log d)$, which is favorable for federated learning. We prove the convergence of HSQ theoretically and show by experiments that HSQ significantly reduces the communication cost of model training without hurting convergence accuracy.
Norm-Explicit Quantization: Improving Vector Quantization for Maximum Inner Product Search
Nov 20, 2019
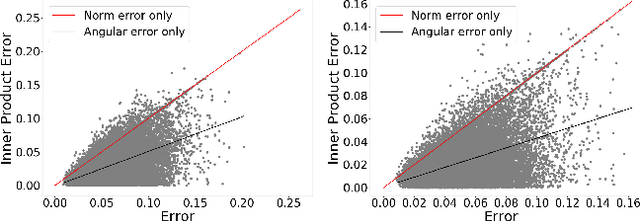


Vector quantization (VQ) techniques are widely used in similarity search for data compression, fast metric computation and etc. Originally designed for Euclidean distance, existing VQ techniques (e.g., PQ, AQ) explicitly or implicitly minimize the quantization error. In this paper, we present a new angle to analyze the quantization error, which decomposes the quantization error into norm error and direction error. We show that quantization errors in norm have much higher influence on inner products than quantization errors in direction, and small quantization error does not necessarily lead to good performance in maximum inner product search (MIPS). Based on this observation, we propose norm-explicit quantization (NEQ) --- a general paradigm that improves existing VQ techniques for MIPS. NEQ quantizes the norms of items in a dataset explicitly to reduce errors in norm, which is crucial for MIPS. For the direction vectors, NEQ can simply reuse an existing VQ technique to quantize them without modification. We conducted extensive experiments on a variety of datasets and parameter configurations. The experimental results show that NEQ improves the performance of various VQ techniques for MIPS, including PQ, OPQ, RQ and AQ.
Understanding and Improving Proximity Graph based Maximum Inner Product Search
Sep 30, 2019


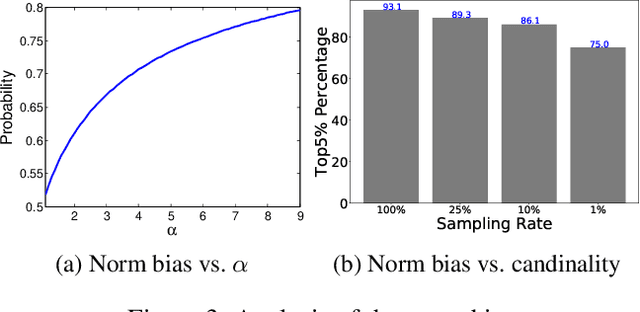
The inner-product navigable small world graph (ip-NSW) represents the state-of-the-art method for approximate maximum inner product search (MIPS) and it can achieve an order of magnitude speedup over the fastest baseline. However, to date it is still unclear where its exceptional performance comes from. In this paper, we show that there is a strong norm bias in the MIPS problem, which means that the large norm items are very likely to become the result of MIPS. Then we explain the good performance of ip-NSW as matching the norm bias of the MIPS problem - large norm items have big in-degrees in the ip-NSW proximity graph and a walk on the graph spends the majority of computation on these items, thus effectively avoids unnecessary computation on small norm items. Furthermore, we propose the ip-NSW+ algorithm, which improves ip-NSW by introducing an additional angular proximity graph. Search is first conducted on the angular graph to find the angular neighbors of a query and then the MIPS neighbors of these angular neighbors are used to initialize the candidate pool for search on the inner-product proximity graph. Experiment results show that ip-NSW+ consistently and significantly outperforms ip-NSW and provides more robust performance under different data distributions.
Norm-Range Partition: A Universal Catalyst for LSH based Maximum Inner Product Search
Nov 05, 2018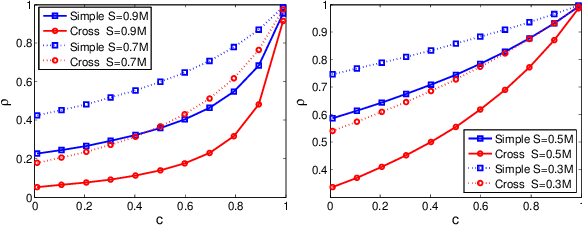
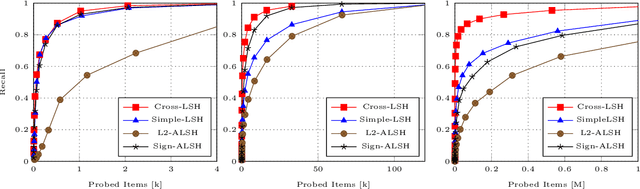
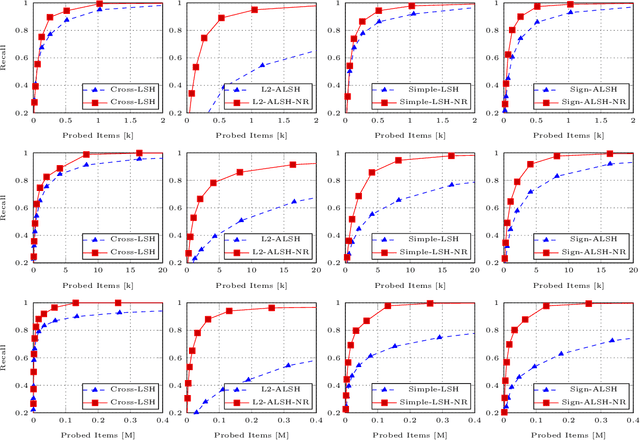

Recently, locality sensitive hashing (LSH) was shown to be effective for MIPS and several algorithms including $L_2$-ALSH, Sign-ALSH and Simple-LSH have been proposed. In this paper, we introduce the norm-range partition technique, which partitions the original dataset into sub-datasets containing items with similar 2-norms and builds hash index independently for each sub-dataset. We prove that norm-range partition reduces the query processing complexity for all existing LSH based MIPS algorithms under mild conditions. The key to performance improvement is that norm-range partition allows to use smaller normalization factor most sub-datasets. For efficient query processing, we also formulate a unified framework to rank the buckets from the hash indexes of different sub-datasets. Experiments on real datasets show that norm-range partition significantly reduces the number of probed for LSH based MIPS algorithms when achieving the same recall.
Norm-Ranging LSH for Maximum Inner Product Search
Oct 22, 2018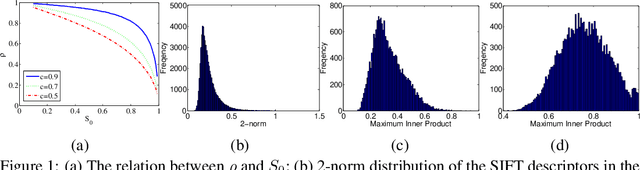

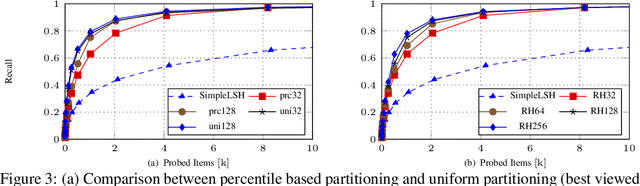
Neyshabur and Srebro proposed Simple-LSH, which is the state-of-the-art hashing method for maximum inner product search (MIPS) with performance guarantee. We found that the performance of Simple-LSH, in both theory and practice, suffers from long tails in the 2-norm distribution of real datasets. We propose Norm-ranging LSH, which addresses the excessive normalization problem caused by long tails in Simple-LSH by partitioning a dataset into multiple sub-datasets and building a hash index for each sub-dataset independently. We prove that Norm-ranging LSH has lower query time complexity than Simple-LSH. We also show that the idea of partitioning the dataset can improve other hashing based methods for MIPS. To support efficient query processing on the hash indexes of the sub-datasets, a novel similarity metric is formulated. Experiments show that Norm-ranging LSH achieves an order of magnitude speedup over Simple-LSH for the same recall, thus significantly benefiting applications that involve MIPS.